 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Radar Odometry Beyond the Pavement: Current Capabilities and Challenges
Apr 27, 2026Radar offers unique advantages for localization in unstructured environments, including robustness to weather, lighting, and airborne particulates. While most prior work has studied radar odometry in urban, largely planar settings, its performance in off-road environments remains less understood. In this paper, we investigate the potential of radar for off-road odometry estimation and identify key challenges that arise from full $SE(3)$ vehicle motion, terrain-induced ground returns, and sparse or unstable features. To address these issues, we introduce two simple baselines: Radar-KISSICP, which applies motion compensation to generate 3D-aware radar pointclouds, and Radar-IMU, which leverages IMU preintegration to stabilize scan matching. Experiments on the Great Outdoors (GO) dataset demonstrate that these baselines improve trajectory estimation in challenging routes and provide a reference point for future development of radar odometry in off-road robotics.
Stylos: Multi-View 3D Stylization with Single-Forward Gaussian Splatting
Sep 30, 2025We present Stylos, a single-forward 3D Gaussian framework for 3D style transfer that operates on unposed content, from a single image to a multi-view collection, conditioned on a separate reference style image. Stylos synthesizes a stylized 3D Gaussian scene without per-scene optimization or precomputed poses, achieving geometry-aware, view-consistent stylization that generalizes to unseen categories, scenes, and styles. At its core, Stylos adopts a Transformer backbone with two pathways: geometry predictions retain self-attention to preserve geometric fidelity, while style is injected via global cross-attention to enforce visual consistency across views. With the addition of a voxel-based 3D style loss that aligns aggregated scene features to style statistics, Stylos enforces view-consistent stylization while preserving geometry. Experiments across multiple datasets demonstrate that Stylos delivers high-quality zero-shot stylization, highlighting the effectiveness of global style-content coupling, the proposed 3D style loss, and the scalability of our framework from single view to large-scale multi-view settings.
Trailblazer: Learning offroad costmaps for long range planning
May 14, 2025Autonomous navigation in off-road environments remains a significant challenge in field robotics, particularly for Unmanned Ground Vehicles (UGVs) tasked with search and rescue, exploration, and surveillance. Effective long-range planning relies on the integration of onboard perception systems with prior environmental knowledge, such as satellite imagery and LiDAR data. This work introduces Trailblazer, a novel framework that automates the conversion of multi-modal sensor data into costmaps, enabling efficient path planning without manual tuning. Unlike traditional approaches, Trailblazer leverages imitation learning and a differentiable A* planner to learn costmaps directly from expert demonstrations, enhancing adaptability across diverse terrains. The proposed methodology was validated through extensive real-world testing, achieving robust performance in dynamic and complex environments, demonstrating Trailblazer's potential for scalable, efficient autonomous navigation.
Learning Autonomy: Off-Road Navigation Enhanced by Human Input
Feb 26, 2025In the area of autonomous driving, navigating off-road terrains presents a unique set of challenges, from unpredictable surfaces like grass and dirt to unexpected obstacles such as bushes and puddles. In this work, we present a novel learning-based local planner that addresses these challenges by directly capturing human driving nuances from real-world demonstrations using only a monocular camera. The key features of our planner are its ability to navigate in challenging off-road environments with various terrain types and its fast learning capabilities. By utilizing minimal human demonstration data (5-10 mins), it quickly learns to navigate in a wide array of off-road conditions. The local planner significantly reduces the real world data required to learn human driving preferences. This allows the planner to apply learned behaviors to real-world scenarios without the need for manual fine-tuning, demonstrating quick adjustment and adaptability in off-road autonomous driving technology.
GO: The Great Outdoors Multimodal Dataset
Jan 31, 2025



The Great Outdoors (GO) dataset is a multi-modal annotated data resource aimed at advancing ground robotics research in unstructured environments. This dataset provides the most comprehensive set of data modalities and annotations compared to existing off-road datasets. In total, the GO dataset includes six unique sensor types with high-quality semantic annotations and GPS traces to support tasks such as semantic segmentation, object detection, and SLAM. The diverse environmental conditions represented in the dataset present significant real-world challenges that provide opportunities to develop more robust solutions to support the continued advancement of field robotics, autonomous exploration, and perception systems in natural environments. The dataset can be downloaded at: https://www.unmannedlab.org/the-great-outdoors-dataset/
Exploring Unstructured Environments using Minimal Sensing on Cooperative Nano-Drones
Jul 09, 2024
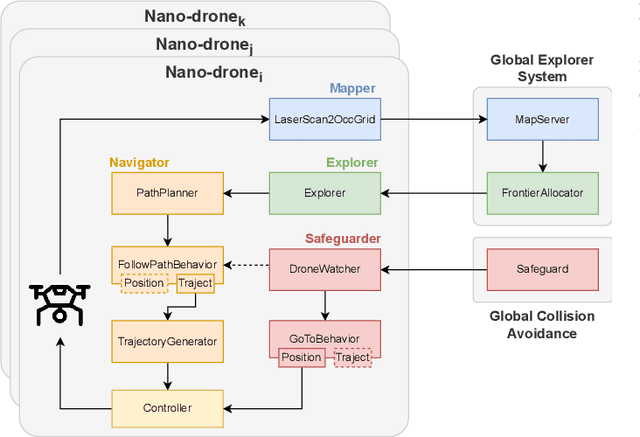
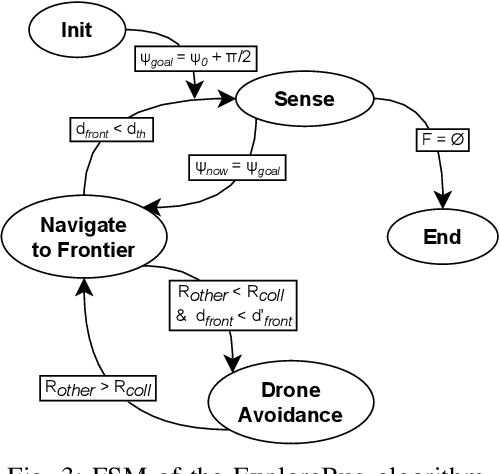
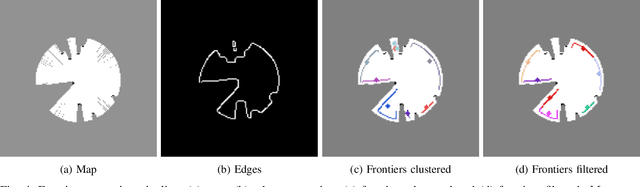
Recent advances have improved autonomous navigation and mapping under payload constraints, but current multi-robot inspection algorithms are unsuitable for nano-drones due to their need for heavy sensors and high computational resources. To address these challenges, we introduce ExploreBug, a novel hybrid frontier range bug algorithm designed to handle limited sensing capabilities for a swarm of nano-drones. This system includes three primary components: a mapping subsystem, an exploration subsystem, and a navigation subsystem. Additionally, an intra-swarm collision avoidance system is integrated to prevent collisions between drones. We validate the efficacy of our approach through extensive simulations and real-world exploration experiments involving up to seven drones in simulations and three in real-world settings, across various obstacle configurations and with a maximum navigation speed of 0.75 m/s. Our tests demonstrate that the algorithm efficiently completes exploration tasks, even with minimal sensing, across different swarm sizes and obstacle densities. Furthermore, our frontier allocation heuristic ensures an equal distribution of explored areas and paths traveled by each drone in the swarm. We publicly release the source code of the proposed system to foster further developments in mapping and exploration using autonomous nano drones.
Reflectivity Is All You Need!: Advancing LiDAR Semantic Segmentation
Mar 19, 2024



LiDAR semantic segmentation frameworks predominantly leverage geometry-based features to differentiate objects within a scan. While these methods excel in scenarios with clear boundaries and distinct shapes, their performance declines in environments where boundaries are blurred, particularly in off-road contexts. To address this, recent strides in 3D segmentation algorithms have focused on harnessing raw LiDAR intensity measurements to improve prediction accuracy. Despite these efforts, current learning-based models struggle to correlate the intricate connections between raw intensity and factors such as distance, incidence angle, material reflectivity, and atmospheric conditions. Building upon our prior work, this paper delves into the advantages of employing calibrated intensity (also referred to as reflectivity) within learning-based LiDAR semantic segmentation frameworks. We initially establish that incorporating reflectivity as an input enhances the existing LiDAR semantic segmentation model. Furthermore, we present findings that enable the model to learn to calibrate intensity can boost its performance. Through extensive experimentation on the off-road dataset Rellis-3D, we demonstrate notable improvements. Specifically, converting intensity to reflectivity results in a 4% increase in mean Intersection over Union (mIoU) when compared to using raw intensity in Off-road scenarios. Additionally, we also investigate the possible benefits of using calibrated intensity in semantic segmentation in urban environments (SemanticKITTI) and cross-sensor domain adaptation.
3DGS-ReLoc: 3D Gaussian Splatting for Map Representation and Visual ReLocalization
Mar 17, 2024



This paper presents a novel system designed for 3D mapping and visual relocalization using 3D Gaussian Splatting. Our proposed method uses LiDAR and camera data to create accurate and visually plausible representations of the environment. By leveraging LiDAR data to initiate the training of the 3D Gaussian Splatting map, our system constructs maps that are both detailed and geometrically accurate. To mitigate excessive GPU memory usage and facilitate rapid spatial queries, we employ a combination of a 2D voxel map and a KD-tree. This preparation makes our method well-suited for visual localization tasks, enabling efficient identification of correspondences between the query image and the rendered image from the Gaussian Splatting map via normalized cross-correlation (NCC). Additionally, we refine the camera pose of the query image using feature-based matching and the Perspective-n-Point (PnP) technique. The effectiveness, adaptability, and precision of our system are demonstrated through extensive evaluation on the KITTI360 dataset.
Off-Road LiDAR Intensity Based Semantic Segmentation
Jan 02, 2024LiDAR is used in autonomous driving to provide 3D spatial information and enable accurate perception in off-road environments, aiding in obstacle detection, mapping, and path planning. Learning-based LiDAR semantic segmentation utilizes machine learning techniques to automatically classify objects and regions in LiDAR point clouds. Learning-based models struggle in off-road environments due to the presence of diverse objects with varying colors, textures, and undefined boundaries, which can lead to difficulties in accurately classifying and segmenting objects using traditional geometric-based features. In this paper, we address this problem by harnessing the LiDAR intensity parameter to enhance object segmentation in off-road environments. Our approach was evaluated in the RELLIS-3D data set and yielded promising results as a preliminary analysis with improved mIoU for classes "puddle" and "grass" compared to more complex deep learning-based benchmarks. The methodology was evaluated for compatibility across both Velodyne and Ouster LiDAR systems, assuring its cross-platform applicability. This analysis advocates for the incorporation of calibrated intensity as a supplementary input, aiming to enhance the prediction accuracy of learning based semantic segmentation frameworks. https://github.com/MOONLABIISERB/lidar-intensity-predictor/tree/main
GPT-4V Takes the Wheel: Evaluating Promise and Challenges for Pedestrian Behavior Prediction
Nov 24, 2023



Existing pedestrian behavior prediction methods rely primarily on deep neural networks that utilize features extracted from video frame sequences. Although these vision-based models have shown promising results, they face limitations in effectively capturing and utilizing the dynamic spatio-temporal interactions between the target pedestrian and its surrounding traffic elements, crucial for accurate reasoning. Additionally, training these models requires manually annotating domain-specific datasets, a process that is expensive, time-consuming, and difficult to generalize to new environments and scenarios. The recent emergence of Large Multimodal Models (LMMs) offers potential solutions to these limitations due to their superior visual understanding and causal reasoning capabilities, which can be harnessed through semi-supervised training. GPT-4V(ision), the latest iteration of the state-of-the-art Large-Language Model GPTs, now incorporates vision input capabilities. This report provides a comprehensive evaluation of the potential of GPT-4V for pedestrian behavior prediction in autonomous driving using publicly available datasets: JAAD, PIE, and WiDEVIEW. Quantitative and qualitative evaluations demonstrate GPT-4V(ision)'s promise in zero-shot pedestrian behavior prediction and driving scene understanding ability for autonomous driving. However, it still falls short of the state-of-the-art traditional domain-specific models. Challenges include difficulties in handling small pedestrians and vehicles in motion. These limitations highlight the need for further research and development in this area.