 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaLiTy and LADS: A Unified Framework and Dataset Suite for LiDAR Adaptation Across Sensors and Adverse Weather Conditions
Apr 11, 2026Reliable LiDAR perception requires robustness across sensors, environments, and adverse weather. However, existing datasets rarely provide physically consistent observations of the same scene under varying sensor configurations and weather conditions, limiting systematic analysis of domain shifts. This work presents ReaLiTy, a unified physics-informed framework that transforms LiDAR data to match target sensor specifications and weather conditions. The framework integrates physically grounded cues with a learning-based module to generate realistic intensity patterns, while a physics-based weather model introduces consistent geometric and radiometric degradations. Building on this framework, we introduce the LiDAR Adaptation Dataset Suite (LADS), a collection of physically consistent, transformation-ready point clouds with one-to-one correspondence to original datasets. Experiments demonstrate improved cross-domain consistency and realistic weather effects. ReaLiTy and LADS provide a reproducible foundation for studying LiDAR adaptation and simulation-driven perception in intelligent transportation systems.
Simulating Realistic LiDAR Data Under Adverse Weather for Autonomous Vehicles: A Physics-Informed Learning Approach
Apr 01, 2026Accurate LiDAR simulation is crucial for autonomous driving, especially under adverse weather conditions. Existing methods struggle to capture the complex interactions between LiDAR signals and atmospheric phenomena, leading to unrealistic representations. This paper presents a physics-informed learning framework (PICWGAN) for generating realistic LiDAR data under adverse weather conditions. By integrating physicsdriven constraints for modeling signal attenuation and geometryconsistent degradations into a physics-informed learning pipeline, the proposed method reduces the sim-to-real gap. Evaluations on real-world datasets (CADC for snow, Boreas for rain) and the VoxelScape dataset show that our approach closely mimics realworld intensity patterns. Quantitative metrics, including MSE, SSIM, KL divergence, and Wasserstein distance, demonstrate statistically consistent intensity distributions. Additionally, models trained on data enhanced by our framework outperform baselines in downstream 3D object detection, achieving performance comparable to models trained on real-world data. These results highlight the effectiveness of the proposed approach in improving the realism of LiDAR data and enabling robust perception under adverse weather conditions.
NaviDriveVLM: Decoupling High-Level Reasoning and Motion Planning for Autonomous Driving
Mar 09, 2026Vision-language models (VLMs) have emerged as a promising direction for end-to-end autonomous driving (AD) by jointly modeling visual observations, driving context, and language-based reasoning. However, existing VLM-based systems face a trade-off between high-level reasoning and motion planning: large models offer strong semantic understanding but are costly to adapt for precise control, whereas small VLM models can be fine-tuned efficiently but often exhibit weaker reasoning. We propose NaviDriveVLM, a decoupled framework that separates reasoning from action generation using a large-scale Navigator and a lightweight trainable Driver. This design preserves reasoning ability, reduces training cost, and provides an explicit interpretable intermediate representation for downstream planning. Experiments on the nuScenes benchmark show that NaviDriveVLM outperforms large VLM baselines in end-to-end motion planning.
Toward Unified Multimodal Representation Learning for Autonomous Driving
Mar 09, 2026Contrastive Language-Image Pre-training (CLIP) has shown impressive performance in aligning visual and textual representations. Recent studies have extended this paradigm to 3D vision to improve scene understanding for autonomous driving. A common strategy is to employ pairwise cosine similarity between modalities to guide the training of a 3D encoder. However, considering the similarity between individual modality pairs rather than all modalities jointly fails to ensure consistent and unified alignment across the entire multimodal space. In this paper, we propose a Contrastive Tensor Pre-training (CTP) framework that simultaneously aligns multiple modalities in a unified embedding space to enhance end-to-end autonomous driving. Compared with pairwise cosine similarity alignment, our method extends the 2D similarity matrix into a multimodal similarity tensor. Furthermore, we introduce a tensor loss to enable joint contrastive learning across all modalities. For experimental validation of our framework, we construct a text-image-point cloud triplet dataset derived from existing autonomous driving datasets. The results show that our proposed unified multimodal alignment framework achieves favorable performance for both scenarios: (i) aligning a 3D encoder with pretrained CLIP encoders, and (ii) pretraining all encoders from scratch.
Point Virtual Transformer
Feb 04, 2026LiDAR-based 3D object detectors often struggle to detect far-field objects due to the sparsity of point clouds at long ranges, which limits the availability of reliable geometric cues. To address this, prior approaches augment LiDAR data with depth-completed virtual points derived from RGB images; however, directly incorporating all virtual points leads to increased computational cost and introduces challenges in effectively fusing real and virtual information. We present Point Virtual Transformer (PointViT), a transformer-based 3D object detection framework that jointly reasons over raw LiDAR points and selectively sampled virtual points. The framework examines multiple fusion strategies, ranging from early point-level fusion to BEV-based gated fusion, and analyses their trade-offs in terms of accuracy and efficiency. The fused point cloud is voxelized and encoded using sparse convolutions to form a BEV representation, from which a compact set of high-confidence object queries is initialised and refined through a transformer-based context aggregation module. Experiments on the KITTI benchmark report 91.16% 3D AP, 95.94% BEV AP, and 99.36% AP on the KITTI 2D detection benchmark for the Car class.
CAtCh: Cognitive Assessment through Cookie Thief
Jun 07, 2025Several machine learning algorithms have been developed for the prediction of Alzheimer's disease and related dementia (ADRD) from spontaneous speech. However, none of these algorithms have been translated for the prediction of broader cognitive impairment (CI), which in some cases is a precursor and risk factor of ADRD. In this paper, we evaluated several speech-based open-source methods originally proposed for the prediction of ADRD, as well as methods from multimodal sentiment analysis for the task of predicting CI from patient audio recordings. Results demonstrated that multimodal methods outperformed unimodal ones for CI prediction, and that acoustics-based approaches performed better than linguistics-based ones. Specifically, interpretable acoustic features relating to affect and prosody were found to significantly outperform BERT-based linguistic features and interpretable linguistic features, respectively. All the code developed for this study is available at https://github.com/JTColonel/catch.
Learning Autonomy: Off-Road Navigation Enhanced by Human Input
Feb 26, 2025In the area of autonomous driving, navigating off-road terrains presents a unique set of challenges, from unpredictable surfaces like grass and dirt to unexpected obstacles such as bushes and puddles. In this work, we present a novel learning-based local planner that addresses these challenges by directly capturing human driving nuances from real-world demonstrations using only a monocular camera. The key features of our planner are its ability to navigate in challenging off-road environments with various terrain types and its fast learning capabilities. By utilizing minimal human demonstration data (5-10 mins), it quickly learns to navigate in a wide array of off-road conditions. The local planner significantly reduces the real world data required to learn human driving preferences. This allows the planner to apply learned behaviors to real-world scenarios without the need for manual fine-tuning, demonstrating quick adjustment and adaptability in off-road autonomous driving technology.
Systematic Knowledge Injection into Large Language Models via Diverse Augmentation for Domain-Specific RAG
Feb 12, 2025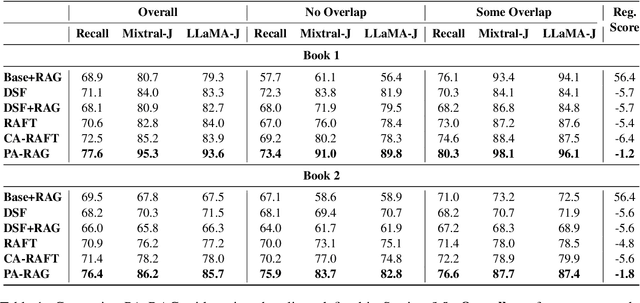

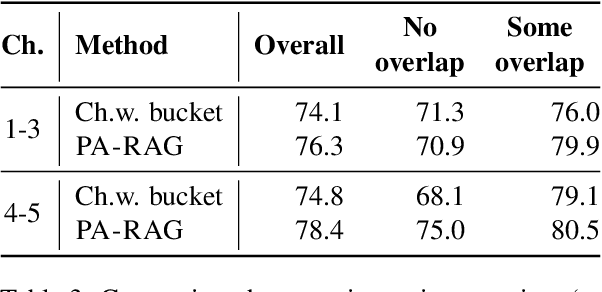
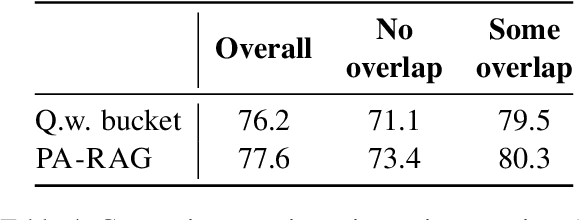
Retrieval-Augmented Generation (RAG) has emerged as a prominent method for incorporating domain knowledge into Large Language Models (LLMs). While RAG enhances response relevance by incorporating retrieved domain knowledge in the context, retrieval errors can still lead to hallucinations and incorrect answers. To recover from retriever failures, domain knowledge is injected by fine-tuning the model to generate the correct response, even in the case of retrieval errors. However, we observe that without systematic knowledge augmentation, fine-tuned LLMs may memorize new information but still fail to extract relevant domain knowledge, leading to poor performance. In this work, we present a novel framework that significantly enhances the fine-tuning process by augmenting the training data in two ways -- context augmentation and knowledge paraphrasing. In context augmentation, we create multiple training samples for a given QA pair by varying the relevance of the retrieved information, teaching the model when to ignore and when to rely on retrieved content. In knowledge paraphrasing, we fine-tune with multiple answers to the same question, enabling LLMs to better internalize specialized knowledge. To mitigate catastrophic forgetting due to fine-tuning, we add a domain-specific identifier to a question and also utilize a replay buffer containing general QA pairs. Experimental results demonstrate the efficacy of our method over existing techniques, achieving up to 10\% relative gain in token-level recall while preserving the LLM's generalization capabilities.
Longitudinal Ensemble Integration for sequential classification with multimodal data
Nov 08, 2024



Effectively modeling multimodal longitudinal data is a pressing need in various application areas, especially biomedicine. Despite this, few approaches exist in the literature for this problem, with most not adequately taking into account the multimodality of the data. In this study, we developed multiple configurations of a novel multimodal and longitudinal learning framework, Longitudinal Ensemble Integration (LEI), for sequential classification. We evaluated LEI's performance, and compared it against existing approaches, for the early detection of dementia, which is among the most studied multimodal sequential classification tasks. LEI outperformed these approaches due to its use of intermediate base predictions arising from the individual data modalities, which enabled their better integration over time. LEI's design also enabled the identification of features that were consistently important across time for the effective prediction of dementia-related diagnoses. Overall, our work demonstrates the potential of LEI for sequential classification from longitudinal multimodal data.
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
Sep 07, 2024
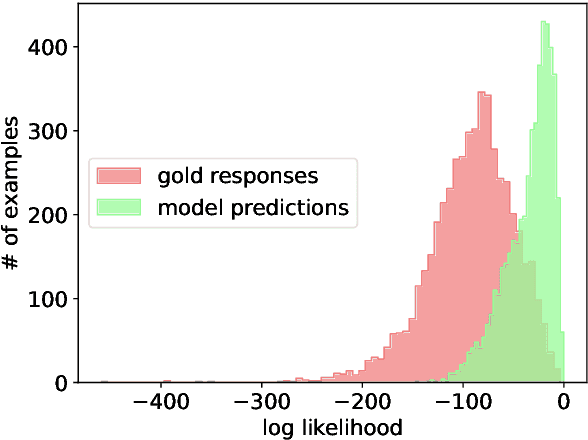
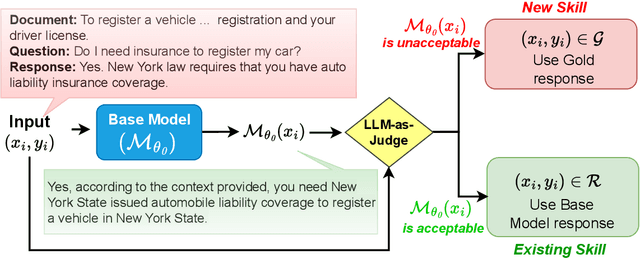
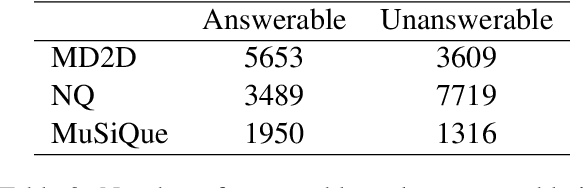
Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.