 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025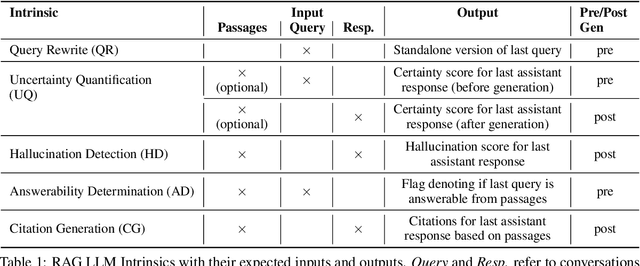
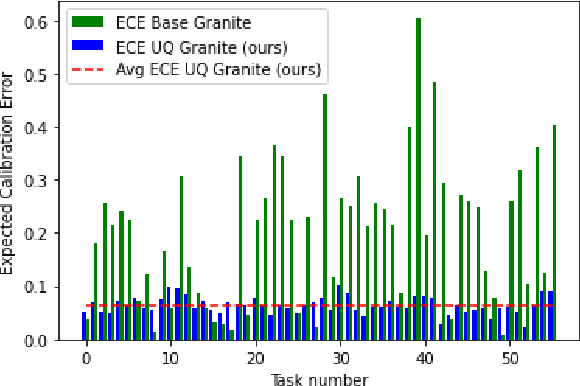

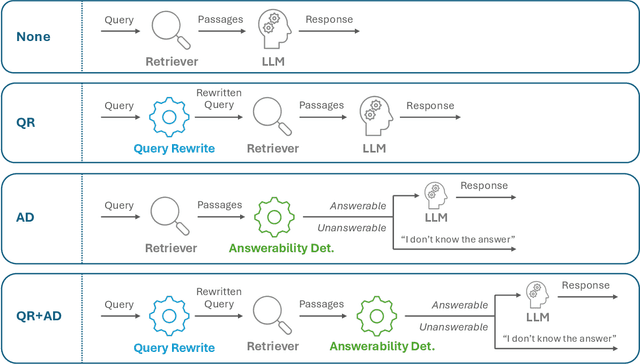
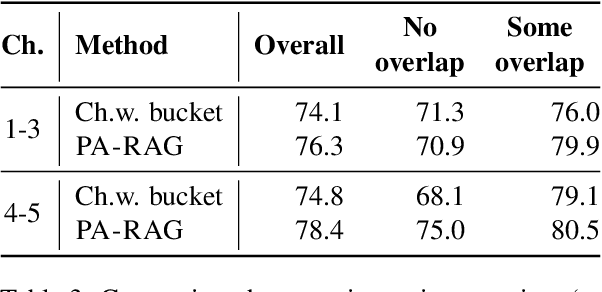
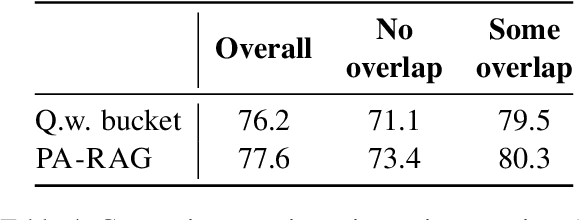
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
Systematic Knowledge Injection into Large Language Models via Diverse Augmentation for Domain-Specific RAG
Feb 12, 2025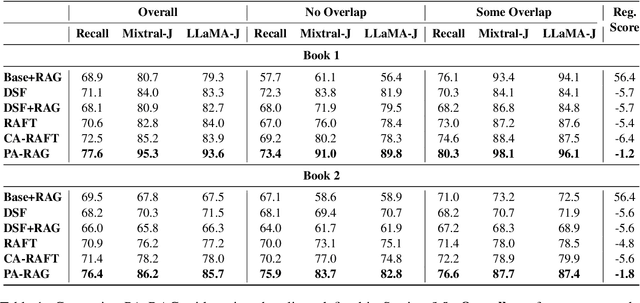

Retrieval-Augmented Generation (RAG) has emerged as a prominent method for incorporating domain knowledge into Large Language Models (LLMs). While RAG enhances response relevance by incorporating retrieved domain knowledge in the context, retrieval errors can still lead to hallucinations and incorrect answers. To recover from retriever failures, domain knowledge is injected by fine-tuning the model to generate the correct response, even in the case of retrieval errors. However, we observe that without systematic knowledge augmentation, fine-tuned LLMs may memorize new information but still fail to extract relevant domain knowledge, leading to poor performance. In this work, we present a novel framework that significantly enhances the fine-tuning process by augmenting the training data in two ways -- context augmentation and knowledge paraphrasing. In context augmentation, we create multiple training samples for a given QA pair by varying the relevance of the retrieved information, teaching the model when to ignore and when to rely on retrieved content. In knowledge paraphrasing, we fine-tune with multiple answers to the same question, enabling LLMs to better internalize specialized knowledge. To mitigate catastrophic forgetting due to fine-tuning, we add a domain-specific identifier to a question and also utilize a replay buffer containing general QA pairs. Experimental results demonstrate the efficacy of our method over existing techniques, achieving up to 10\% relative gain in token-level recall while preserving the LLM's generalization capabilities.
Selective Self-to-Supervised Fine-Tuning for Generalization in Large Language Models
Feb 12, 2025Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-to-Supervised Fine-Tuning (S3FT), a fine-tuning approach that achieves better performance than the standard supervised fine-tuning (SFT) while improving generalization. S3FT leverages the existence of multiple valid responses to a query. By utilizing the model's correct responses, S3FT reduces model specialization during the fine-tuning stage. S3FT first identifies the correct model responses from the training set by deploying an appropriate judge. Then, it fine-tunes the model using the correct model responses and the gold response (or its paraphrase) for the remaining samples. The effectiveness of S3FT is demonstrated through experiments on mathematical reasoning, Python programming and reading comprehension tasks. The results show that standard SFT can lead to an average performance drop of up to $4.4$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, S3FT reduces this drop by half, i.e. $2.5$, indicating better generalization capabilities than SFT while performing significantly better on the fine-tuning tasks.
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
Sep 07, 2024
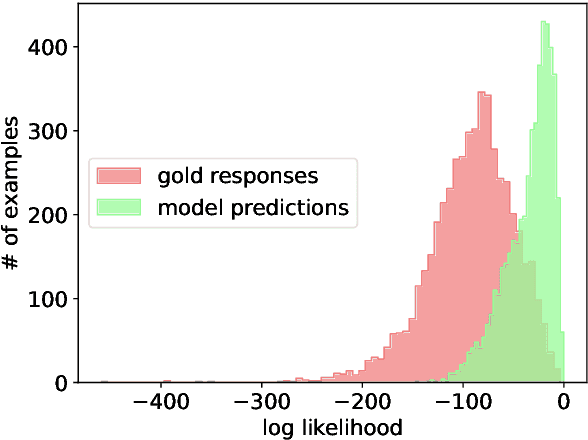
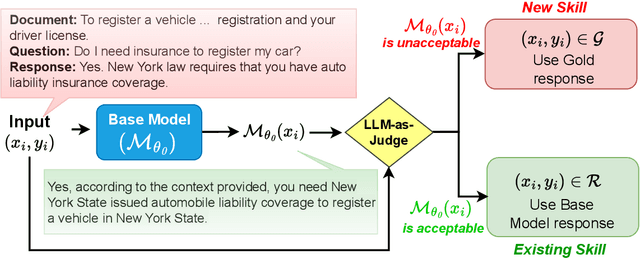
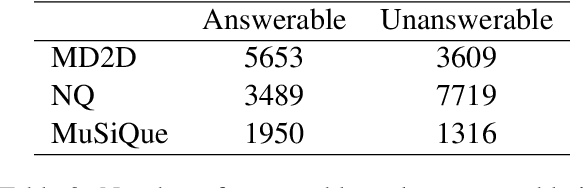
Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.
Few shot chain-of-thought driven reasoning to prompt LLMs for open ended medical question answering
Mar 07, 2024



Large Language models (LLMs) have demonstrated significant potential in transforming healthcare by automating tasks such as clinical documentation, information retrieval, and decision support. In this aspect, carefully engineered prompts have emerged as a powerful tool for using LLMs for medical scenarios, e.g., patient clinical scenarios. In this paper, we propose a modified version of the MedQA-USMLE dataset, which is subjective, to mimic real-life clinical scenarios. We explore the Chain of Thought (CoT) reasoning based on subjective response generation for the modified MedQA-USMLE dataset with appropriate LM-driven forward reasoning for correct responses to the medical questions. Keeping in mind the importance of response verification in the medical setting, we utilize a reward training mechanism whereby the language model also provides an appropriate verified response for a particular response to a clinical question. In this regard, we also include human-in-the-loop for different evaluation aspects. We develop better in-contrast learning strategies by modifying the 5-shot-codex-CoT-prompt from arXiv:2207.08143 for the subjective MedQA dataset and developing our incremental-reasoning prompt. Our evaluations show that the incremental reasoning prompt performs better than the modified codex prompt in certain scenarios. We also show that greedy decoding with the incremental reasoning method performs better than other strategies, such as prompt chaining and eliminative reasoning.
BRAIn: Bayesian Reward-conditioned Amortized Inference for natural language generation from feedback
Feb 04, 2024



Following the success of Proximal Policy Optimization (PPO) for Reinforcement Learning from Human Feedback (RLHF), new techniques such as Sequence Likelihood Calibration (SLiC) and Direct Policy Optimization (DPO) have been proposed that are offline in nature and use rewards in an indirect manner. These techniques, in particular DPO, have recently become the tools of choice for LLM alignment due to their scalability and performance. However, they leave behind important features of the PPO approach. Methods such as SLiC or RRHF make use of the Reward Model (RM) only for ranking/preference, losing fine-grained information and ignoring the parametric form of the RM (eg., Bradley-Terry, Plackett-Luce), while methods such as DPO do not use even a separate reward model. In this work, we propose a novel approach, named BRAIn, that re-introduces the RM as part of a distribution matching approach.BRAIn considers the LLM distribution conditioned on the assumption of output goodness and applies Bayes theorem to derive an intractable posterior distribution where the RM is explicitly represented. BRAIn then distills this posterior into an amortized inference network through self-normalized importance sampling, leading to a scalable offline algorithm that significantly outperforms prior art in summarization and AntropicHH tasks. BRAIn also has interesting connections to PPO and DPO for specific RM choices.
Pointwise Mutual Information Based Metric and Decoding Strategy for Faithful Generation in Document Grounded Dialogs
May 20, 2023



A major concern in using deep learning based generative models for document-grounded dialogs is the potential generation of responses that are not \textit{faithful} to the underlying document. Existing automated metrics used for evaluating the faithfulness of response with respect to the grounding document measure the degree of similarity between the generated response and the document's content. However, these automated metrics are far from being well aligned with human judgments. Therefore, to improve the measurement of faithfulness, we propose a new metric that utilizes (Conditional) Point-wise Mutual Information (PMI) between the generated response and the source document, conditioned on the dialogue. PMI quantifies the extent to which the document influences the generated response -- with a higher PMI indicating a more faithful response. We build upon this idea to create a new decoding technique that incorporates PMI into the response generation process to predict more faithful responses. Our experiments on the BEGIN benchmark demonstrate an improved correlation of our metric with human evaluation. We also show that our decoding technique is effective in generating more faithful responses when compared to standard decoding techniques on a set of publicly available document-grounded dialog datasets.
A Solver-Free Framework for Scalable Learning in Neural ILP Architectures
Oct 17, 2022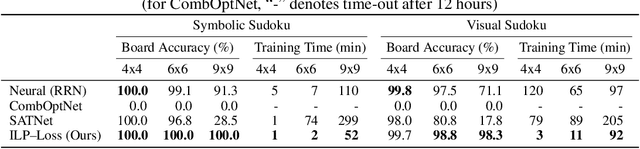
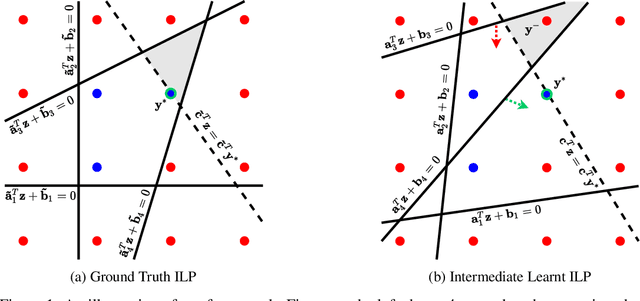
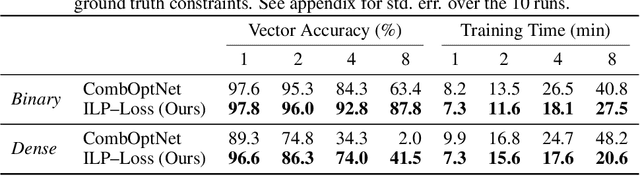

There is a recent focus on designing architectures that have an Integer Linear Programming (ILP) layer within a neural model (referred to as Neural ILP in this paper). Neural ILP architectures are suitable for pure reasoning tasks that require data-driven constraint learning or for tasks requiring both perception (neural) and reasoning (ILP). A recent SOTA approach for end-to-end training of Neural ILP explicitly defines gradients through the ILP black box (Paulus et al. 2021) - this trains extremely slowly, owing to a call to the underlying ILP solver for every training data point in a minibatch. In response, we present an alternative training strategy that is solver-free, i.e., does not call the ILP solver at all at training time. Neural ILP has a set of trainable hyperplanes (for cost and constraints in ILP), together representing a polyhedron. Our key idea is that the training loss should impose that the final polyhedron separates the positives (all constraints satisfied) from the negatives (at least one violated constraint or a suboptimal cost value), via a soft-margin formulation. While positive example(s) are provided as part of the training data, we devise novel techniques for generating negative samples. Our solution is flexible enough to handle equality as well as inequality constraints. Experiments on several problems, both perceptual as well as symbolic, which require learning the constraints of an ILP, show that our approach has superior performance and scales much better compared to purely neural baselines and other state-of-the-art models that require solver-based training. In particular, we are able to obtain excellent performance in 9 x 9 symbolic and visual sudoku, to which the other Neural ILP solver is not able to scale.
Matching Papers and Reviewers at Large Conferences
Mar 02, 2022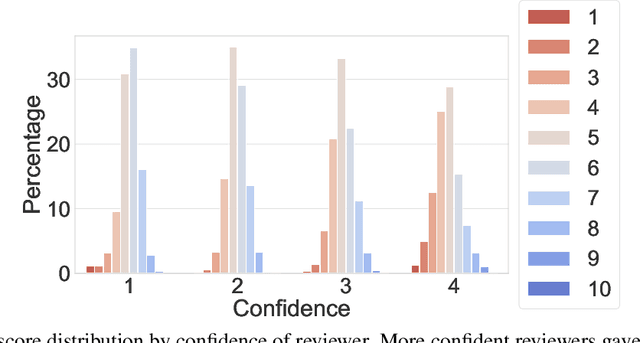

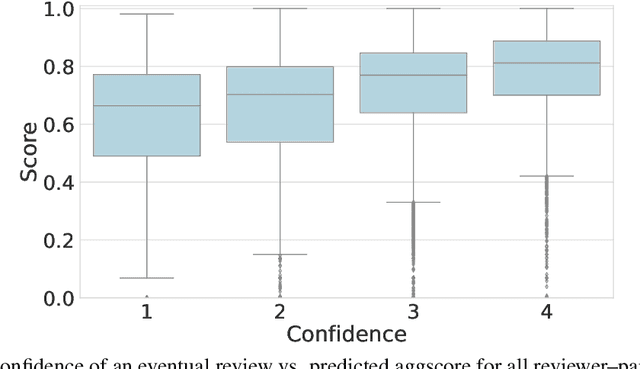

This paper studies a novel reviewer-paper matching approach that was recently deployed in the 35th AAAI Conference on Artificial Intelligence (AAAI 2021), and has since been adopted by other conferences including AAAI 2022 and ICML 2022. This approach has three main elements: (1) collecting and processing input data to identify problematic matches and generate reviewer-paper scores; (2) formulating and solving an optimization problem to find good reviewer-paper matchings; and (3) the introduction of a novel, two-phase reviewing process that shifted reviewing resources away from papers likely to be rejected and towards papers closer to the decision boundary. This paper also describes an evaluation of these innovations based on an extensive post-hoc analysis on real data -- including a comparison with the matching algorithm used in AAAI's previous (2020) iteration -- and supplements this with additional numerical experimentation.
Neural Models for Output-Space Invariance in Combinatorial Problems
Feb 07, 2022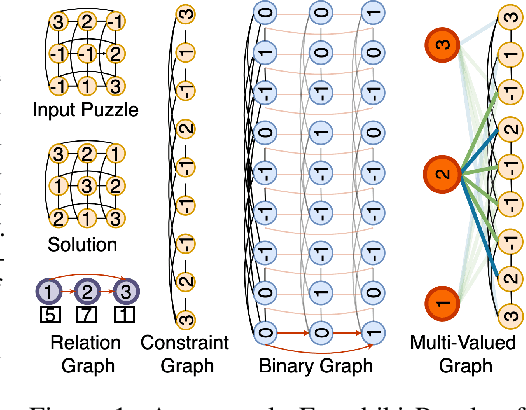
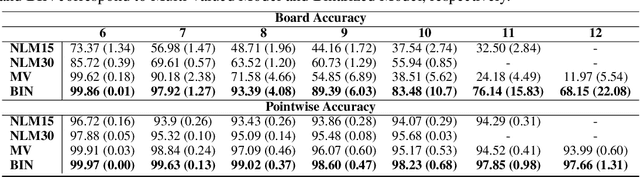
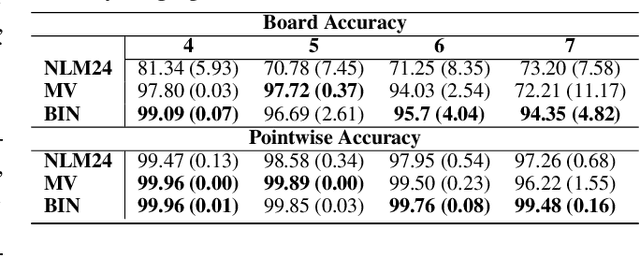
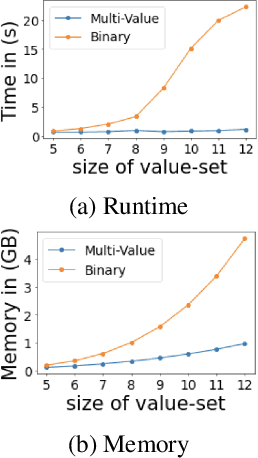
Recently many neural models have been proposed to solve combinatorial puzzles by implicitly learning underlying constraints using their solved instances, such as sudoku or graph coloring (GCP). One drawback of the proposed architectures, which are often based on Graph Neural Networks (GNN), is that they cannot generalize across the size of the output space from which variables are assigned a value, for example, set of colors in a GCP, or board-size in sudoku. We call the output space for the variables as 'value-set'. While many works have demonstrated generalization of GNNs across graph size, there has been no study on how to design a GNN for achieving value-set invariance for problems that come from the same domain. For example, learning to solve 16 x 16 sudoku after being trained on only 9 x 9 sudokus. In this work, we propose novel methods to extend GNN based architectures to achieve value-set invariance. Specifically, our model builds on recently proposed Recurrent Relational Networks. Our first approach exploits the graph-size invariance of GNNs by converting a multi-class node classification problem into a binary node classification problem. Our second approach works directly with multiple classes by adding multiple nodes corresponding to the values in the value-set, and then connecting variable nodes to value nodes depending on the problem initialization. Our experimental evaluation on three different combinatorial problems demonstrates that both our models perform well on our novel problem, compared to a generic neural reasoner. Between two of our models, we observe an inherent trade-off: while the binarized model gives better performance when trained on smaller value-sets, multi-valued model is much more memory efficient, resulting in improved performance when trained on larger value-sets, where binarized model fails to train.