 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElementaryNet: A Non-Strategic Neural Network for Predicting Human Behavior in Normal-Form Games
Mar 07, 2025Models of human behavior in game-theoretic settings often distinguish between strategic behavior, in which a player both reasons about how others will act and best responds to these beliefs, and "level-0" non-strategic behavior, in which they do not respond to explicit beliefs about others. The state of the art for predicting human behavior on unrepeated simultaneous-move games is GameNet, a neural network that learns extremely complex level-0 specifications from data. The current paper makes three contributions. First, it shows that GameNet's level-0 specifications are too powerful, because they are capable of strategic reasoning. Second, it introduces a novel neural network architecture (dubbed ElementaryNet) and proves that it is only capable of nonstrategic behavior. Third, it describes an extensive experimental evaluation of ElementaryNet. Our overall findings are that (1) ElementaryNet dramatically underperforms GameNet when neither model is allowed to explicitly model higher level agents who best-respond to the model's predictions, indicating that good performance on our dataset requires a model capable of strategic reasoning; (2) that the two models achieve statistically indistinguishable performance when such higher-level agents are introduced, meaning that ElementaryNet's restriction to a non-strategic level-0 specification does not degrade model performance; and (3) that this continues to hold even when ElementaryNet is restricted to a set of level-0 building blocks previously introduced in the literature, with only the functional form being learned by the neural network.
STEER-ME: Assessing the Microeconomic Reasoning of Large Language Models
Feb 19, 2025



How should one judge whether a given large language model (LLM) can reliably perform economic reasoning? Most existing LLM benchmarks focus on specific applications and fail to present the model with a rich variety of economic tasks. A notable exception is Raman et al. [2024], who offer an approach for comprehensively benchmarking strategic decision-making; however, this approach fails to address the non-strategic settings prevalent in microeconomics, such as supply-and-demand analysis. We address this gap by taxonomizing microeconomic reasoning into $58$ distinct elements, focusing on the logic of supply and demand, each grounded in up to $10$ distinct domains, $5$ perspectives, and $3$ types. The generation of benchmark data across this combinatorial space is powered by a novel LLM-assisted data generation protocol that we dub auto-STEER, which generates a set of questions by adapting handwritten templates to target new domains and perspectives. Because it offers an automated way of generating fresh questions, auto-STEER mitigates the risk that LLMs will be trained to over-fit evaluation benchmarks; we thus hope that it will serve as a useful tool both for evaluating and fine-tuning models for years to come. We demonstrate the usefulness of our benchmark via a case study on $27$ LLMs, ranging from small open-source models to the current state of the art. We examined each model's ability to solve microeconomic problems across our whole taxonomy and present the results across a range of prompting strategies and scoring metrics.
Understanding Understanding: A Pragmatic Framework Motivated by Large Language Models
Jun 16, 2024Motivated by the rapid ascent of Large Language Models (LLMs) and debates about the extent to which they possess human-level qualities, we propose a framework for testing whether any agent (be it a machine or a human) understands a subject matter. In Turing-test fashion, the framework is based solely on the agent's performance, and specifically on how well it answers questions. Elements of the framework include circumscribing the set of questions (the "scope of understanding"), requiring general competence ("passing grade"), avoiding "ridiculous answers", but still allowing wrong and "I don't know" answers to some questions. Reaching certainty about these conditions requires exhaustive testing of the questions which is impossible for nontrivial scopes, but we show how high confidence can be achieved via random sampling and the application of probabilistic confidence bounds. We also show that accompanying answers with explanations can improve the sample complexity required to achieve acceptable bounds, because an explanation of an answer implies the ability to answer many similar questions. According to our framework, current LLMs cannot be said to understand nontrivial domains, but as the framework provides a practical recipe for testing understanding, it thus also constitutes a tool for building AI agents that do understand.
Utilitarian Algorithm Configuration for Infinite Parameter Spaces
May 28, 2024

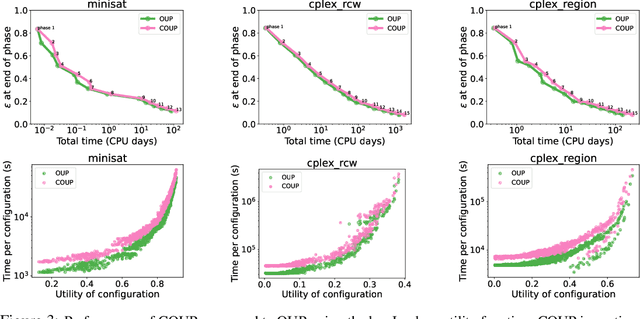

Utilitarian algorithm configuration is a general-purpose technique for automatically searching the parameter space of a given algorithm to optimize its performance, as measured by a given utility function, on a given set of inputs. Recently introduced utilitarian configuration procedures offer optimality guarantees about the returned parameterization while provably adapting to the hardness of the underlying problem. However, the applicability of these approaches is severely limited by the fact that they only search a finite, relatively small set of parameters. They cannot effectively search the configuration space of algorithms with continuous or uncountable parameters. In this paper we introduce a new procedure, which we dub COUP (Continuous, Optimistic Utilitarian Procrastination). COUP is designed to search infinite parameter spaces efficiently to find good configurations quickly. Furthermore, COUP maintains the theoretical benefits of previous utilitarian configuration procedures when applied to finite parameter spaces but is significantly faster, both provably and experimentally.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.
Understanding Iterative Combinatorial Auction Designs via Multi-Agent Reinforcement Learning
Feb 29, 2024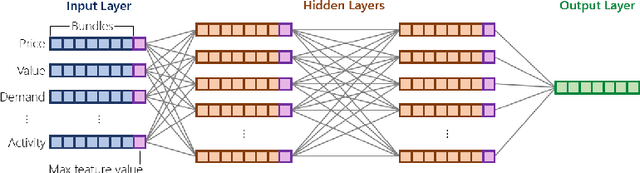
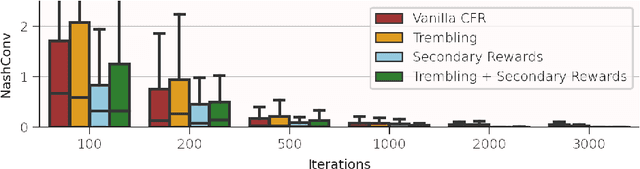
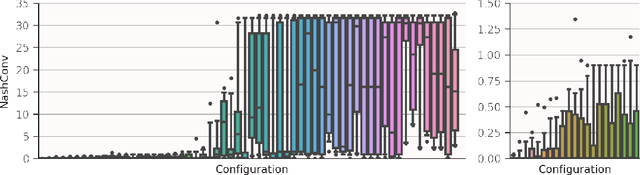
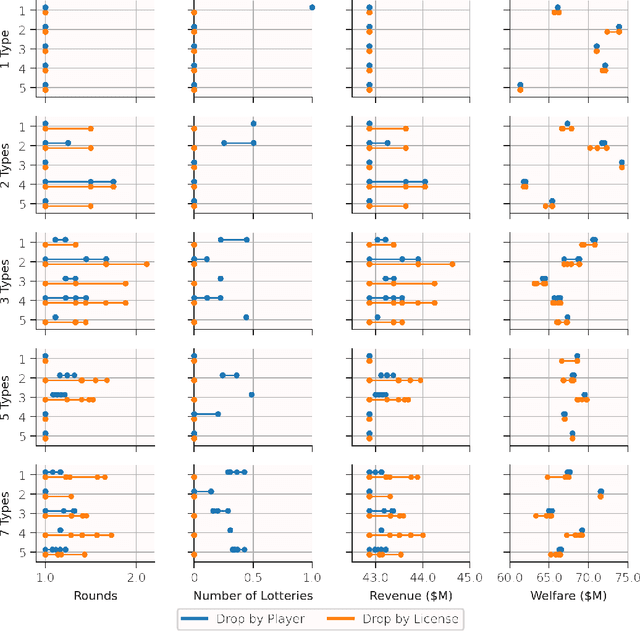
Iterative combinatorial auctions are widely used in high stakes settings such as spectrum auctions. Such auctions can be hard to understand analytically, making it difficult for bidders to determine how to behave and for designers to optimize auction rules to ensure desirable outcomes such as high revenue or welfare. In this paper, we investigate whether multi-agent reinforcement learning (MARL) algorithms can be used to understand iterative combinatorial auctions, given that these algorithms have recently shown empirical success in several other domains. We find that MARL can indeed benefit auction analysis, but that deploying it effectively is nontrivial. We begin by describing modelling decisions that keep the resulting game tractable without sacrificing important features such as imperfect information or asymmetry between bidders. We also discuss how to navigate pitfalls of various MARL algorithms, how to overcome challenges in verifying convergence, and how to generate and interpret multiple equilibria. We illustrate the promise of our resulting approach by using it to evaluate a specific rule change to a clock auction, finding substantially different auction outcomes due to complex changes in bidders' behavior.
Rationality Report Cards: Assessing the Economic Rationality of Large Language Models
Feb 14, 2024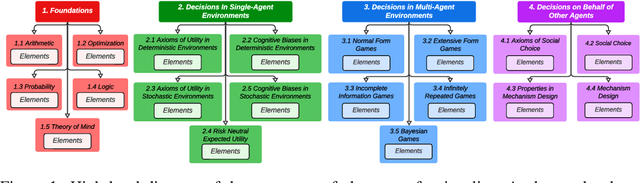
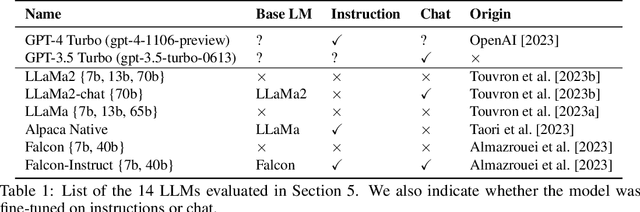

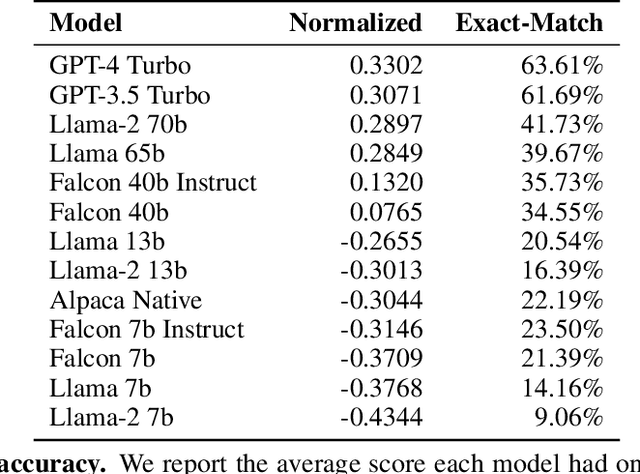
There is increasing interest in using LLMs as decision-making "agents." Doing so includes many degrees of freedom: which model should be used; how should it be prompted; should it be asked to introspect, conduct chain-of-thought reasoning, etc? Settling these questions -- and more broadly, determining whether an LLM agent is reliable enough to be trusted -- requires a methodology for assessing such an agent's economic rationality. In this paper, we provide one. We begin by surveying the economic literature on rational decision making, taxonomizing a large set of fine-grained "elements" that an agent should exhibit, along with dependencies between them. We then propose a benchmark distribution that quantitatively scores an LLMs performance on these elements and, combined with a user-provided rubric, produces a "rationality report card." Finally, we describe the results of a large-scale empirical experiment with 14 different LLMs, characterizing the both current state of the art and the impact of different model sizes on models' ability to exhibit rational behavior.
Utilitarian Algorithm Configuration
Oct 31, 2023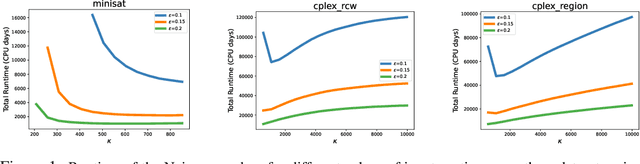

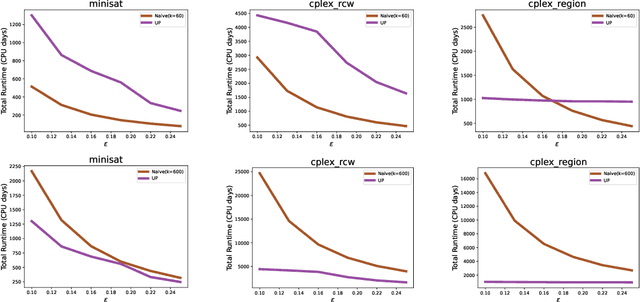
We present the first nontrivial procedure for configuring heuristic algorithms to maximize the utility provided to their end users while also offering theoretical guarantees about performance. Existing procedures seek configurations that minimize expected runtime. However, very recent theoretical work argues that expected runtime minimization fails to capture algorithm designers' preferences. Here we show that the utilitarian objective also confers significant algorithmic benefits. Intuitively, this is because mean runtime is dominated by extremely long runs even when they are incredibly rare; indeed, even when an algorithm never gives rise to such long runs, configuration procedures that provably minimize mean runtime must perform a huge number of experiments to demonstrate this fact. In contrast, utility is bounded and monotonically decreasing in runtime, allowing for meaningful empirical bounds on a configuration's performance. This paper builds on this idea to describe effective and theoretically sound configuration procedures. We prove upper bounds on the runtime of these procedures that are similar to theoretical lower bounds, while also demonstrating their performance empirically.
Generating Benchmarks for Factuality Evaluation of Language Models
Jul 13, 2023

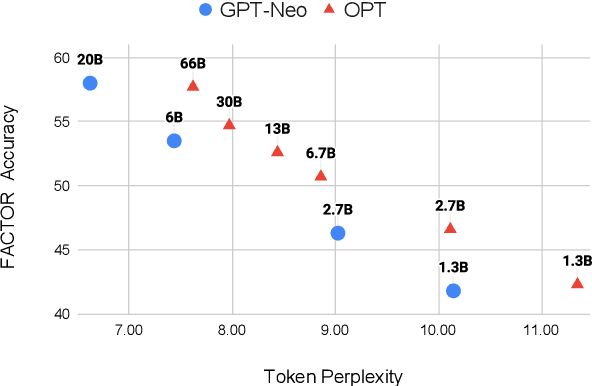
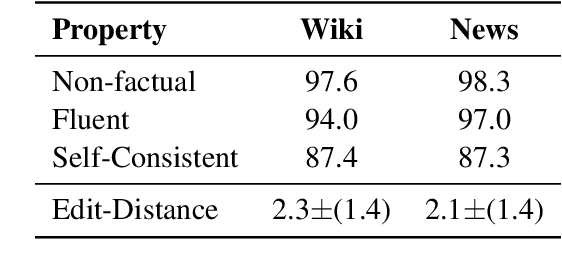
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators. We make our data and code publicly available in https://github.com/AI21Labs/factor.
Loss Functions for Behavioral Game Theory
Jun 07, 2023Behavioral game theorists all use experimental data to evaluate predictive models of human behavior. However, they differ greatly in their choice of loss function for these evaluations, with error rate, negative log-likelihood, cross-entropy, Brier score, and L2 error all being common choices. We attempt to offer a principled answer to the question of which loss functions make sense for this task, formalizing desiderata that we argue loss functions should satisfy. We construct a family of loss functions, which we dub "diagonal bounded Bregman divergences", that satisfy all of these axioms and includes the squared L2 error. In fact, the squared L2 error is the only acceptable loss that is relatively commonly used in practice; we thus recommend its continued use to behavioral game theorists.