 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024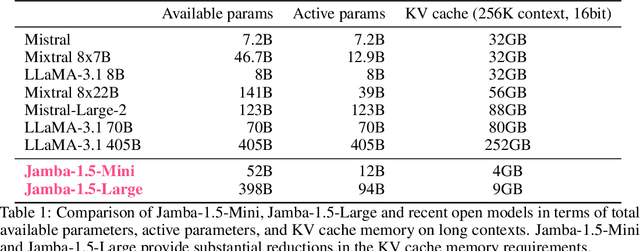
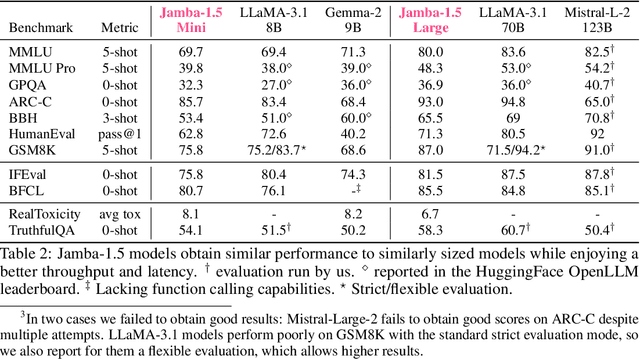
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Generating Benchmarks for Factuality Evaluation of Language Models
Jul 13, 2023

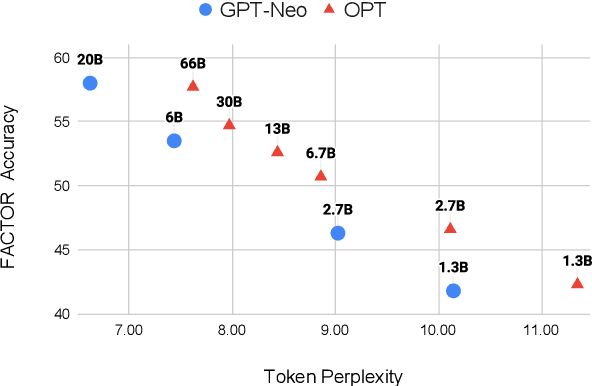
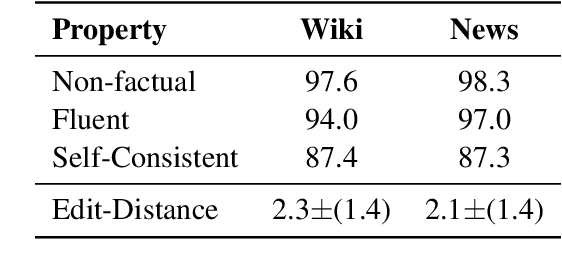
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators. We make our data and code publicly available in https://github.com/AI21Labs/factor.
In-Context Retrieval-Augmented Language Models
Jan 31, 2023Retrieval-Augmented Language Modeling (RALM) methods, that condition a language model (LM) on relevant documents from a grounding corpus during generation, have been shown to significantly improve language modeling while also providing a natural source attribution mechanism. Existing RALM approaches focus on modifying the LM architecture in order to facilitate the incorporation of external information, significantly complicating deployment. This paper proposes an under-explored alternative, which we dub In-Context RALM: leaving the LM architecture unchanged and prepending grounding documents to the input. We show that in-context RALM which uses off-the-shelf general purpose retrievers provides surprisingly large LM gains across model sizes and diverse corpora. We also demonstrate that the document retrieval and ranking mechanism can be specialized to the RALM setting to further boost performance. We conclude that in-context RALM has considerable potential to increase the prevalence of LM grounding, particularly in settings where a pretrained LM must be used without modification or even via API access. To that end, we make our code publicly available.
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
May 01, 2022
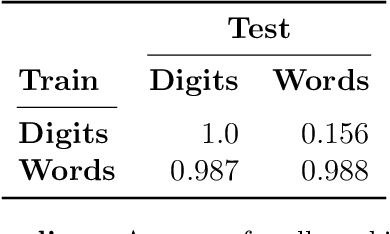

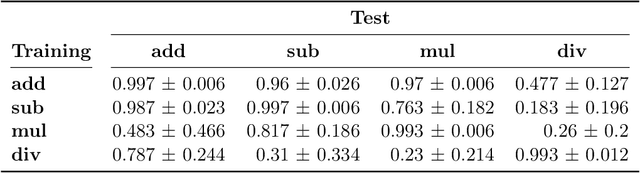
Huge language models (LMs) have ushered in a new era for AI, serving as a gateway to natural-language-based knowledge tasks. Although an essential element of modern AI, LMs are also inherently limited in a number of ways. We discuss these limitations and how they can be avoided by adopting a systems approach. Conceptualizing the challenge as one that involves knowledge and reasoning in addition to linguistic processing, we define a flexible architecture with multiple neural models, complemented by discrete knowledge and reasoning modules. We describe this neuro-symbolic architecture, dubbed the Modular Reasoning, Knowledge and Language (MRKL, pronounced "miracle") system, some of the technical challenges in implementing it, and Jurassic-X, AI21 Labs' MRKL system implementation.
Standing on the Shoulders of Giant Frozen Language Models
Apr 21, 2022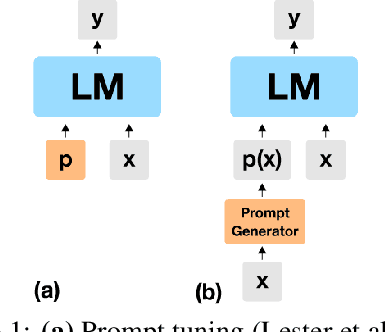
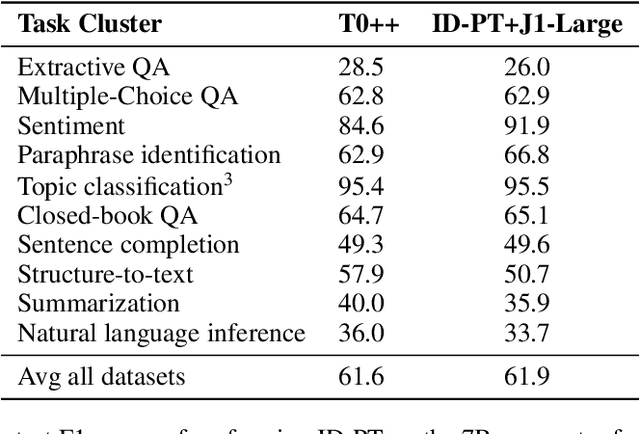
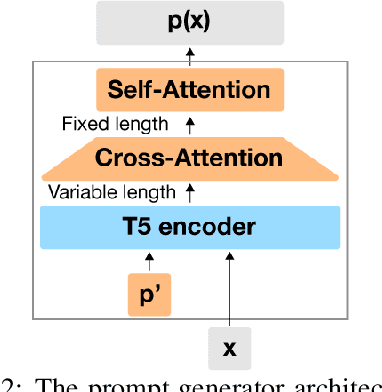

Huge pretrained language models (LMs) have demonstrated surprisingly good zero-shot capabilities on a wide variety of tasks. This gives rise to the appealing vision of a single, versatile model with a wide range of functionalities across disparate applications. However, current leading techniques for leveraging a "frozen" LM -- i.e., leaving its weights untouched -- still often underperform fine-tuning approaches which modify these weights in a task-dependent way. Those, in turn, suffer forgetfulness and compromise versatility, suggesting a tradeoff between performance and versatility. The main message of this paper is that current frozen-model techniques such as prompt tuning are only the tip of the iceberg, and more powerful methods for leveraging frozen LMs can do just as well as fine tuning in challenging domains without sacrificing the underlying model's versatility. To demonstrate this, we introduce three novel methods for leveraging frozen models: input-dependent prompt tuning, frozen readers, and recursive LMs, each of which vastly improves on current frozen-model approaches. Indeed, some of our methods even outperform fine-tuning approaches in domains currently dominated by the latter. The computational cost of each method is higher than that of existing frozen model methods, but still negligible relative to a single pass through a huge frozen LM. Each of these methods constitutes a meaningful contribution in its own right, but by presenting these contributions together we aim to convince the reader of a broader message that goes beyond the details of any given method: that frozen models have untapped potential and that fine-tuning is often unnecessary.
Value-based Search in Execution Space for Mapping Instructions to Programs
Nov 02, 2018

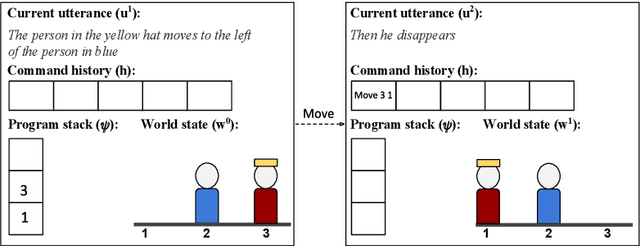

Training models to map natural language instructions to programs given target world supervision only requires searching for good programs at training time. Search is commonly done using beam search in the space of partial programs or program trees, but as the length of the instructions grows finding a good program becomes difficult. In this work, we propose a search algorithm that uses the target world state, known at training time, to train a critic network that predicts the expected reward of every search state. We then score search states on the beam by interpolating their expected reward with the likelihood of programs represented by the search state. Moreover, we search not in the space of programs but in a more compressed state of program executions, augmented with recent entities and actions. On the SCONE dataset, we show that our algorithm dramatically improves performance on all three domains compared to standard beam search and other baselines.