 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence Index Report 2025
Apr 08, 2025Welcome to the eighth edition of the AI Index report. The 2025 Index is our most comprehensive to date and arrives at an important moment, as AI's influence across society, the economy, and global governance continues to intensify. New in this year's report are in-depth analyses of the evolving landscape of AI hardware, novel estimates of inference costs, and new analyses of AI publication and patenting trends. We also introduce fresh data on corporate adoption of responsible AI practices, along with expanded coverage of AI's growing role in science and medicine. Since its founding in 2017 as an offshoot of the One Hundred Year Study of Artificial Intelligence, the AI Index has been committed to equipping policymakers, journalists, executives, researchers, and the public with accurate, rigorously validated, and globally sourced data. Our mission has always been to help these stakeholders make better-informed decisions about the development and deployment of AI. In a world where AI is discussed everywhere - from boardrooms to kitchen tables - this mission has never been more essential. The AI Index continues to lead in tracking and interpreting the most critical trends shaping the field - from the shifting geopolitical landscape and the rapid evolution of underlying technologies, to AI's expanding role in business, policymaking, and public life. Longitudinal tracking remains at the heart of our mission. In a domain advancing at breakneck speed, the Index provides essential context - helping us understand where AI stands today, how it got here, and where it may be headed next. Recognized globally as one of the most authoritative resources on artificial intelligence, the AI Index has been cited in major media outlets such as The New York Times, Bloomberg, and The Guardian; referenced in hundreds of academic papers; and used by policymakers and government agencies around the world.
Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024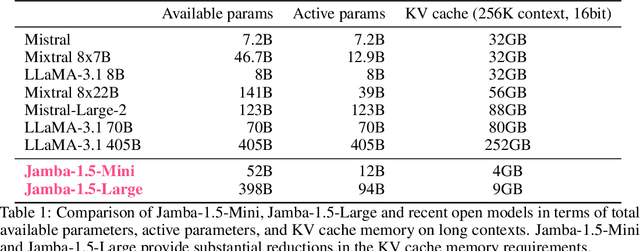
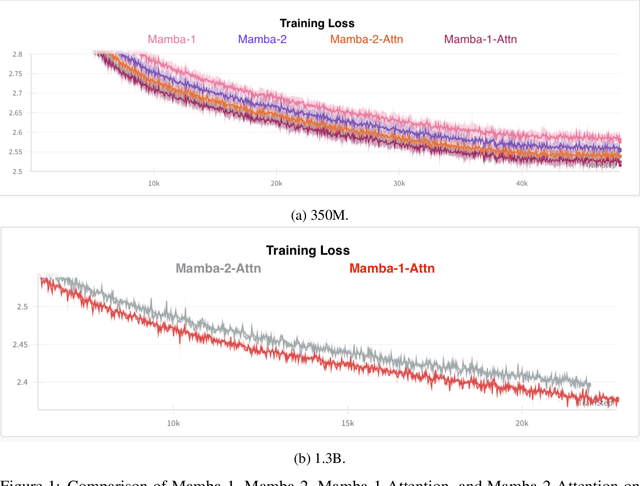
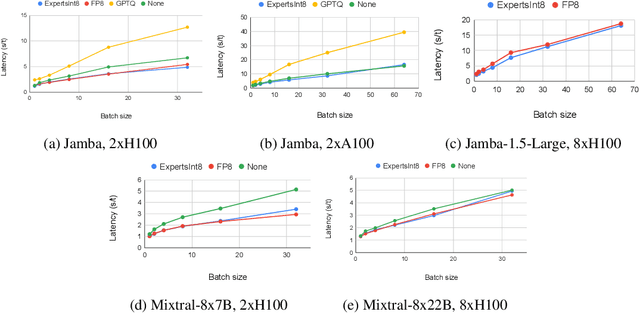
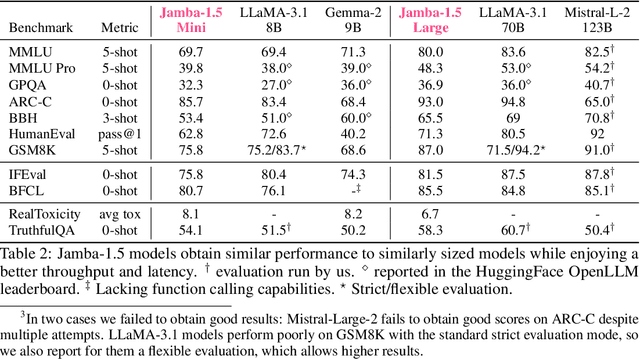
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Understanding Understanding: A Pragmatic Framework Motivated by Large Language Models
Jun 16, 2024Motivated by the rapid ascent of Large Language Models (LLMs) and debates about the extent to which they possess human-level qualities, we propose a framework for testing whether any agent (be it a machine or a human) understands a subject matter. In Turing-test fashion, the framework is based solely on the agent's performance, and specifically on how well it answers questions. Elements of the framework include circumscribing the set of questions (the "scope of understanding"), requiring general competence ("passing grade"), avoiding "ridiculous answers", but still allowing wrong and "I don't know" answers to some questions. Reaching certainty about these conditions requires exhaustive testing of the questions which is impossible for nontrivial scopes, but we show how high confidence can be achieved via random sampling and the application of probabilistic confidence bounds. We also show that accompanying answers with explanations can improve the sample complexity required to achieve acceptable bounds, because an explanation of an answer implies the ability to answer many similar questions. According to our framework, current LLMs cannot be said to understand nontrivial domains, but as the framework provides a practical recipe for testing understanding, it thus also constitutes a tool for building AI agents that do understand.
Artificial Intelligence Index Report 2024
May 29, 2024The 2024 Index is our most comprehensive to date and arrives at an important moment when AI's influence on society has never been more pronounced. This year, we have broadened our scope to more extensively cover essential trends such as technical advancements in AI, public perceptions of the technology, and the geopolitical dynamics surrounding its development. Featuring more original data than ever before, this edition introduces new estimates on AI training costs, detailed analyses of the responsible AI landscape, and an entirely new chapter dedicated to AI's impact on science and medicine. The AI Index report tracks, collates, distills, and visualizes data related to artificial intelligence (AI). Our mission is to provide unbiased, rigorously vetted, broadly sourced data in order for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The AI Index is recognized globally as one of the most credible and authoritative sources for data and insights on artificial intelligence. Previous editions have been cited in major newspapers, including the The New York Times, Bloomberg, and The Guardian, have amassed hundreds of academic citations, and been referenced by high-level policymakers in the United States, the United Kingdom, and the European Union, among other places. This year's edition surpasses all previous ones in size, scale, and scope, reflecting the growing significance that AI is coming to hold in all of our lives.
Jamba: A Hybrid Transformer-Mamba Language Model
Mar 28, 2024



We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
Artificial Intelligence Index Report 2023
Oct 05, 2023Welcome to the sixth edition of the AI Index Report. This year, the report introduces more original data than any previous edition, including a new chapter on AI public opinion, a more thorough technical performance chapter, original analysis about large language and multimodal models, detailed trends in global AI legislation records, a study of the environmental impact of AI systems, and more. The AI Index Report tracks, collates, distills, and visualizes data related to artificial intelligence. Our mission is to provide unbiased, rigorously vetted, broadly sourced data in order for policymakers, researchers, executives, journalists, and the general public to develop a more thorough and nuanced understanding of the complex field of AI. The report aims to be the world's most credible and authoritative source for data and insights about AI.
Generating Benchmarks for Factuality Evaluation of Language Models
Jul 13, 2023

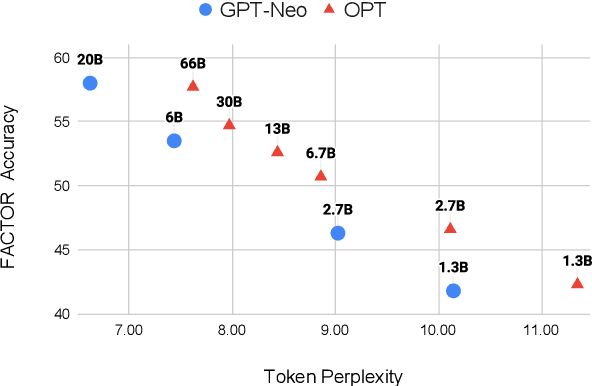
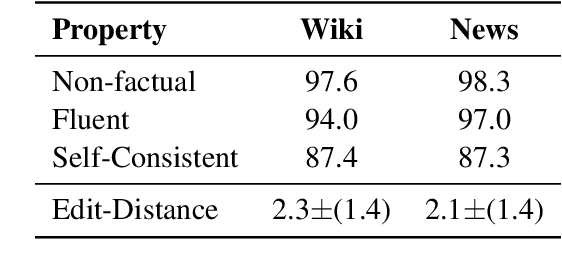
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators. We make our data and code publicly available in https://github.com/AI21Labs/factor.
Human or Not? A Gamified Approach to the Turing Test
May 31, 2023



We present "Human or Not?", an online game inspired by the Turing test, that measures the capability of AI chatbots to mimic humans in dialog, and of humans to tell bots from other humans. Over the course of a month, the game was played by over 1.5 million users who engaged in anonymous two-minute chat sessions with either another human or an AI language model which was prompted to behave like humans. The task of the players was to correctly guess whether they spoke to a person or to an AI. This largest scale Turing-style test conducted to date revealed some interesting facts. For example, overall users guessed the identity of their partners correctly in only 68% of the games. In the subset of the games in which users faced an AI bot, users had even lower correct guess rates of 60% (that is, not much higher than chance). This white paper details the development, deployment, and results of this unique experiment. While this experiment calls for many extensions and refinements, these findings already begin to shed light on the inevitable near future which will commingle humans and AI.
In-Context Retrieval-Augmented Language Models
Jan 31, 2023Retrieval-Augmented Language Modeling (RALM) methods, that condition a language model (LM) on relevant documents from a grounding corpus during generation, have been shown to significantly improve language modeling while also providing a natural source attribution mechanism. Existing RALM approaches focus on modifying the LM architecture in order to facilitate the incorporation of external information, significantly complicating deployment. This paper proposes an under-explored alternative, which we dub In-Context RALM: leaving the LM architecture unchanged and prepending grounding documents to the input. We show that in-context RALM which uses off-the-shelf general purpose retrievers provides surprisingly large LM gains across model sizes and diverse corpora. We also demonstrate that the document retrieval and ranking mechanism can be specialized to the RALM setting to further boost performance. We conclude that in-context RALM has considerable potential to increase the prevalence of LM grounding, particularly in settings where a pretrained LM must be used without modification or even via API access. To that end, we make our code publicly available.
Parallel Context Windows Improve In-Context Learning of Large Language Models
Dec 21, 2022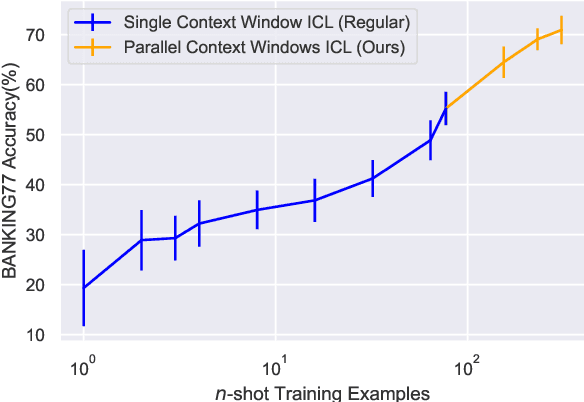
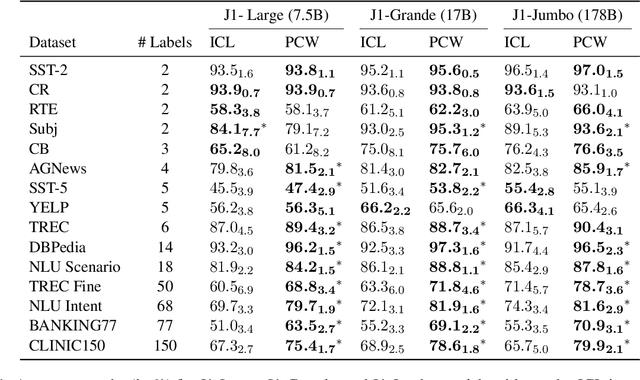
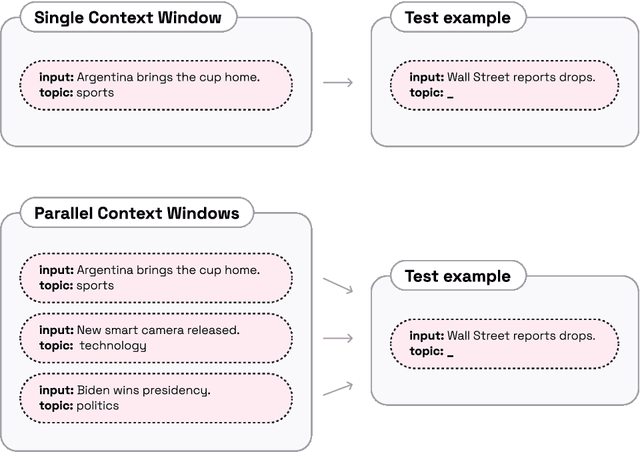
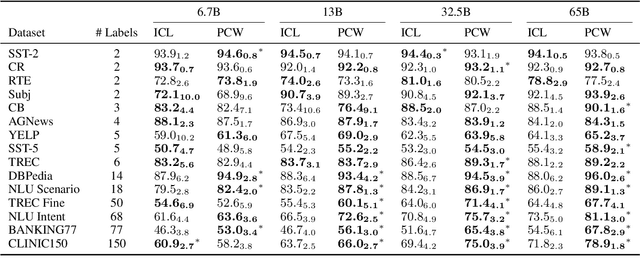
For applications that require processing large amounts of text at inference time, Large Language Models (LLMs) are handicapped by their limited context windows, which are typically 2048 tokens. In-context learning, an emergent phenomenon in LLMs in sizes above a certain parameter threshold, constitutes one significant example because it can only leverage training examples that fit into the context window. Existing efforts to address the context window limitation involve training specialized architectures, which tend to be smaller than the sizes in which in-context learning manifests due to the memory footprint of processing long texts. We present Parallel Context Windows (PCW), a method that alleviates the context window restriction for any off-the-shelf LLM without further training. The key to the approach is to carve a long context into chunks (``windows'') that fit within the architecture, restrict the attention mechanism to apply only within each window, and re-use the positional embeddings among the windows. We test the PCW approach on in-context learning with models that range in size between 750 million and 178 billion parameters, and show substantial improvements for tasks with diverse input and output spaces. Our results motivate further investigation of Parallel Context Windows as a method for applying off-the-shelf LLMs in other settings that require long text sequences.