 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024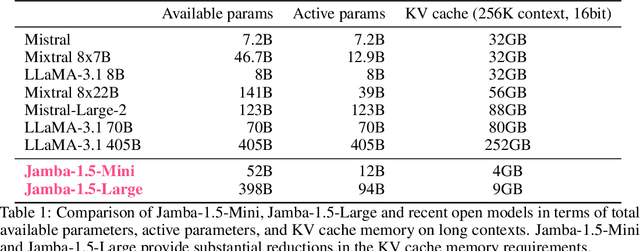
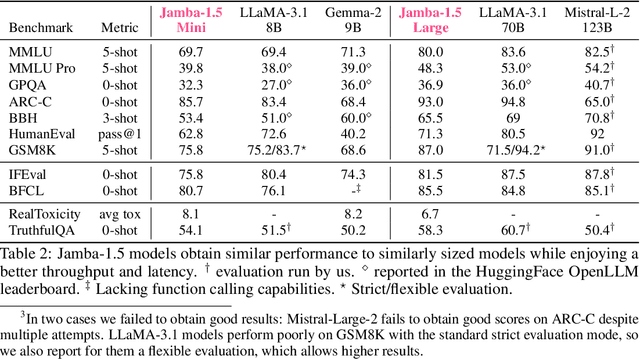
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Exemplar Guided Active Learning
Nov 02, 2020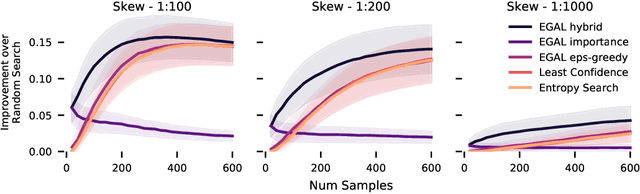
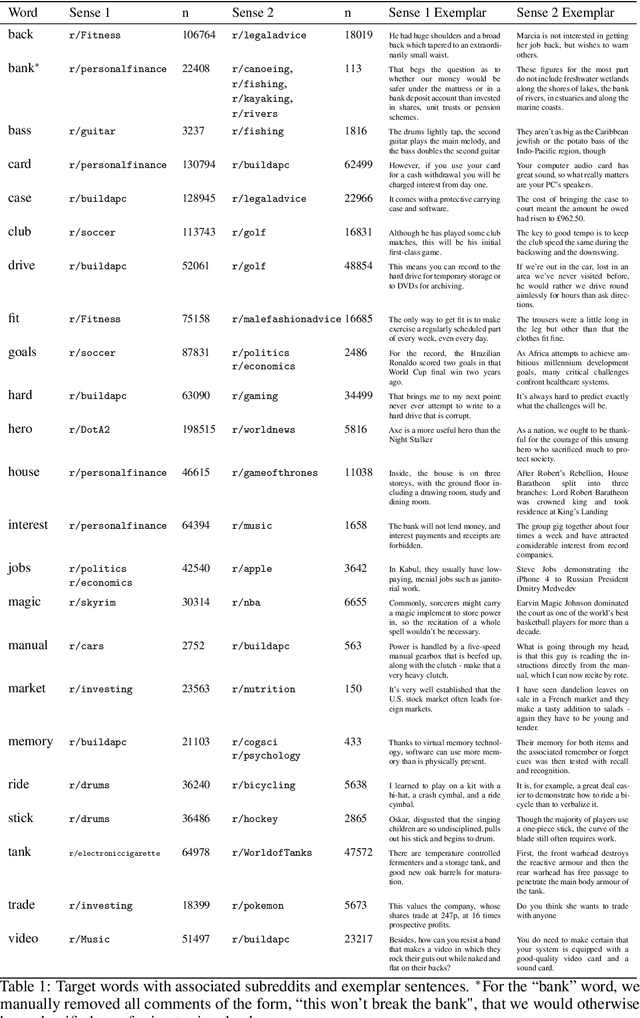
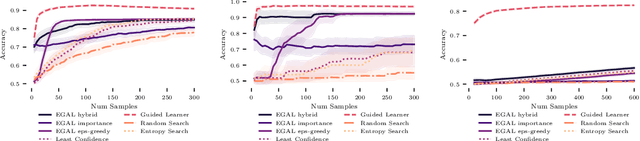
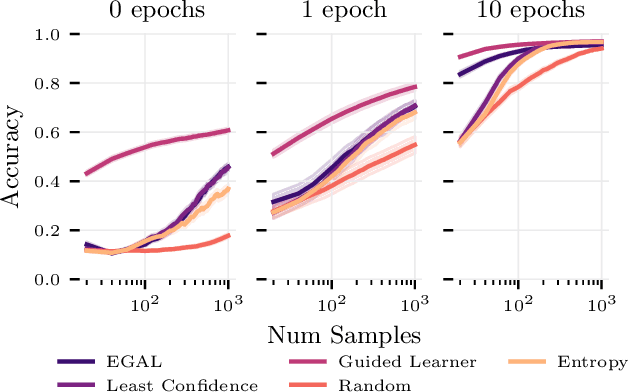
We consider the problem of wisely using a limited budget to label a small subset of a large unlabeled dataset. We are motivated by the NLP problem of word sense disambiguation. For any word, we have a set of candidate labels from a knowledge base, but the label set is not necessarily representative of what occurs in the data: there may exist labels in the knowledge base that very rarely occur in the corpus because the sense is rare in modern English; and conversely there may exist true labels that do not exist in our knowledge base. Our aim is to obtain a classifier that performs as well as possible on examples of each "common class" that occurs with frequency above a given threshold in the unlabeled set while annotating as few examples as possible from "rare classes" whose labels occur with less than this frequency. The challenge is that we are not informed which labels are common and which are rare, and the true label distribution may exhibit extreme skew. We describe an active learning approach that (1) explicitly searches for rare classes by leveraging the contextual embedding spaces provided by modern language models, and (2) incorporates a stopping rule that ignores classes once we prove that they occur below our target threshold with high probability. We prove that our algorithm only costs logarithmically more than a hypothetical approach that knows all true label frequencies and show experimentally that incorporating automated search can significantly reduce the number of samples needed to reach target accuracy levels.
Technical Report: Auxiliary Tuning and its Application to Conditional Text Generation
Jun 30, 2020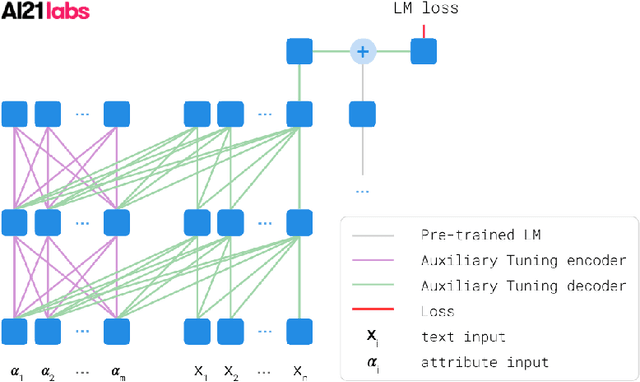

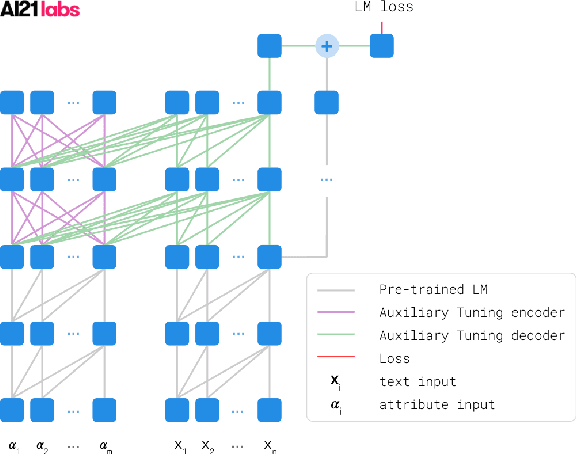
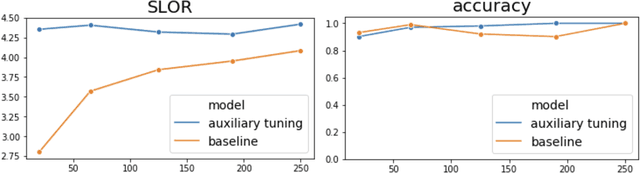
We introduce a simple and efficient method, called Auxiliary Tuning, for adapting a pre-trained Language Model to a novel task; we demonstrate this approach on the task of conditional text generation. Our approach supplements the original pre-trained model with an auxiliary model that shifts the output distribution according to the target task. The auxiliary model is trained by adding its logits to the pre-trained model logits and maximizing the likelihood of the target task output. Our method imposes no constraints on the auxiliary architecture. In particular, the auxiliary model can ingest additional input relevant to the target task, independently from the pre-trained model's input. Furthermore, mixing the models at the logits level provides a natural probabilistic interpretation of the method. Our method achieved similar results to training from scratch for several different tasks, while using significantly fewer resources for training; we share a specific example of text generation conditioned on keywords.
SenseBERT: Driving Some Sense into BERT
Aug 15, 2019

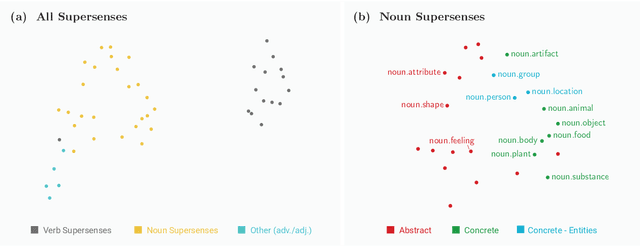
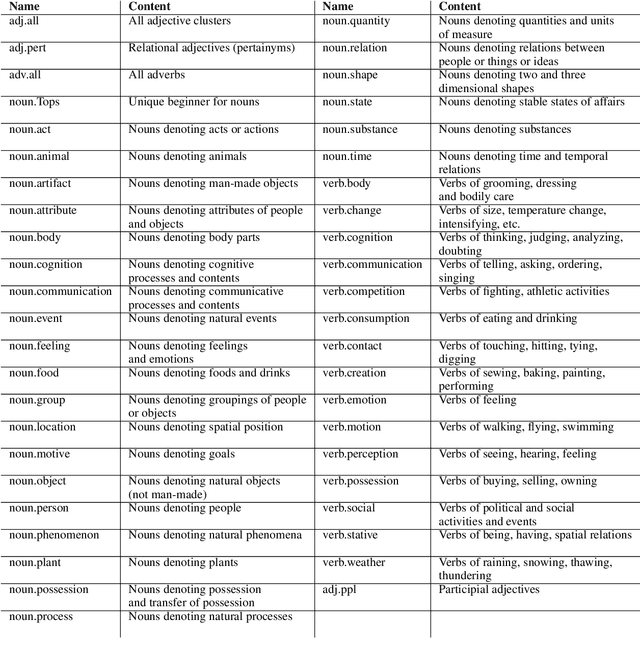
Self-supervision techniques have allowed neural language models to advance the frontier in Natural Language Understanding. However, existing self-supervision techniques operate at the word-form level, which serves as a surrogate for the underlying semantic content. This paper proposes a method to employ self-supervision directly at the word-sense level. Our model, named SenseBERT, is pre-trained to predict not only the masked words but also their WordNet supersenses. Accordingly, we attain a lexical-semantic level language model, without the use of human annotation. SenseBERT achieves significantly improved lexical understanding, as we demonstrate by experimenting on SemEval, and by attaining a state of the art result on the Word in Context (WiC) task. Our approach is extendable to other linguistic signals, which can be similarly integrated into the pre-training process, leading to increasingly semantically informed language models.