 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured RAG for Answering Aggregative Questions
Nov 11, 2025Retrieval-Augmented Generation (RAG) has become the dominant approach for answering questions over large corpora. However, current datasets and methods are highly focused on cases where only a small part of the corpus (usually a few paragraphs) is relevant per query, and fail to capture the rich world of aggregative queries. These require gathering information from a large set of documents and reasoning over them. To address this gap, we propose S-RAG, an approach specifically designed for such queries. At ingestion time, S-RAG constructs a structured representation of the corpus; at inference time, it translates natural-language queries into formal queries over said representation. To validate our approach and promote further research in this area, we introduce two new datasets of aggregative queries: HOTELS and WORLD CUP. Experiments with S-RAG on the newly introduced datasets, as well as on a public benchmark, demonstrate that it substantially outperforms both common RAG systems and long-context LLMs.
TabSTAR: A Foundation Tabular Model With Semantically Target-Aware Representations
May 23, 2025While deep learning has achieved remarkable success across many domains, it has historically underperformed on tabular learning tasks, which remain dominated by gradient boosting decision trees (GBDTs). However, recent advancements are paving the way for Tabular Foundation Models, which can leverage real-world knowledge and generalize across diverse datasets, particularly when the data contains free-text. Although incorporating language model capabilities into tabular tasks has been explored, most existing methods utilize static, target-agnostic textual representations, limiting their effectiveness. We introduce TabSTAR: a Foundation Tabular Model with Semantically Target-Aware Representations. TabSTAR is designed to enable transfer learning on tabular data with textual features, with an architecture free of dataset-specific parameters. It unfreezes a pretrained text encoder and takes as input target tokens, which provide the model with the context needed to learn task-specific embeddings. TabSTAR achieves state-of-the-art performance for both medium- and large-sized datasets across known benchmarks of classification tasks with text features, and its pretraining phase exhibits scaling laws in the number of datasets, offering a pathway for further performance improvements.
Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024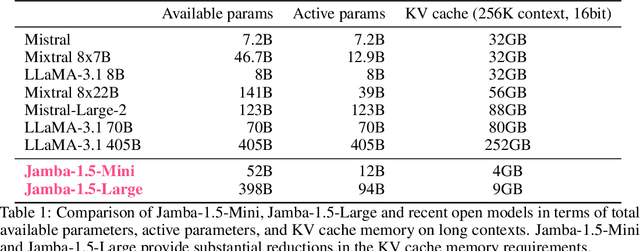
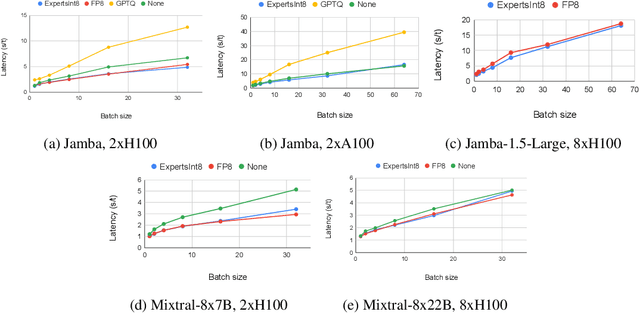
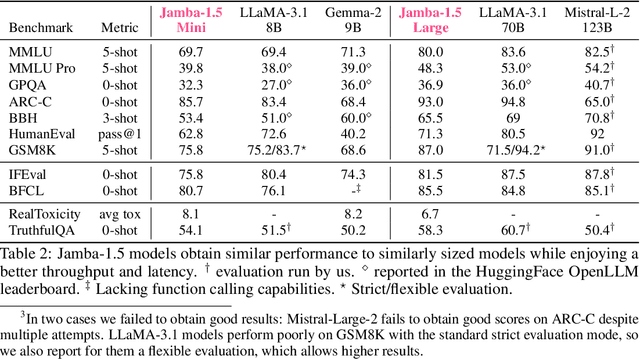
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.