 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured RAG for Answering Aggregative Questions
Nov 11, 2025Retrieval-Augmented Generation (RAG) has become the dominant approach for answering questions over large corpora. However, current datasets and methods are highly focused on cases where only a small part of the corpus (usually a few paragraphs) is relevant per query, and fail to capture the rich world of aggregative queries. These require gathering information from a large set of documents and reasoning over them. To address this gap, we propose S-RAG, an approach specifically designed for such queries. At ingestion time, S-RAG constructs a structured representation of the corpus; at inference time, it translates natural-language queries into formal queries over said representation. To validate our approach and promote further research in this area, we introduce two new datasets of aggregative queries: HOTELS and WORLD CUP. Experiments with S-RAG on the newly introduced datasets, as well as on a public benchmark, demonstrate that it substantially outperforms both common RAG systems and long-context LLMs.
A Simple Global Neural Discourse Parser
Sep 08, 2020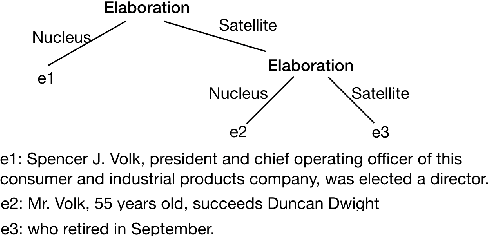
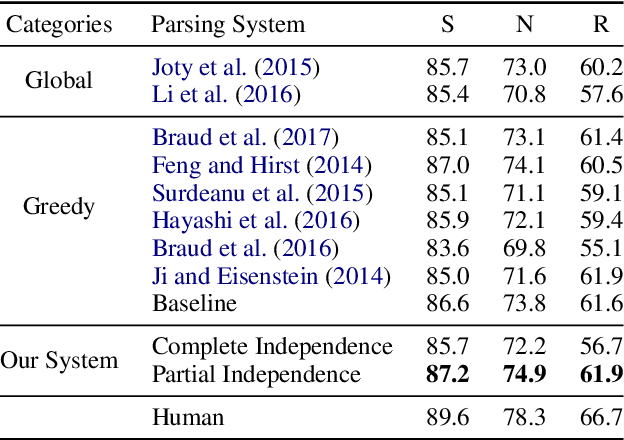
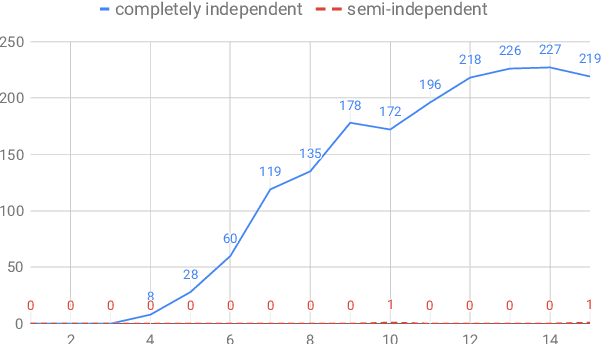
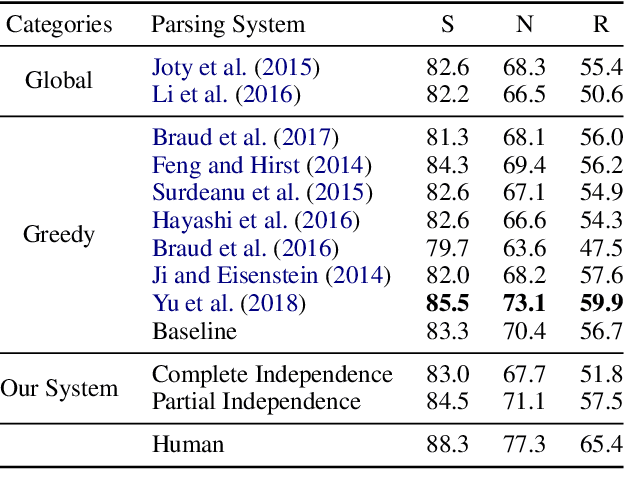
Discourse parsing is largely dominated by greedy parsers with manually-designed features, while global parsing is rare due to its computational expense. In this paper, we propose a simple chart-based neural discourse parser that does not require any manually-crafted features and is based on learned span representations only. To overcome the computational challenge, we propose an independence assumption between the label assigned to a node in the tree and the splitting point that separates its children, which results in tractable decoding. We empirically demonstrate that our model achieves the best performance among global parsers, and comparable performance to state-of-art greedy parsers, using only learned span representations.
On the Limits of Learning to Actively Learn Semantic Representations
Oct 05, 2019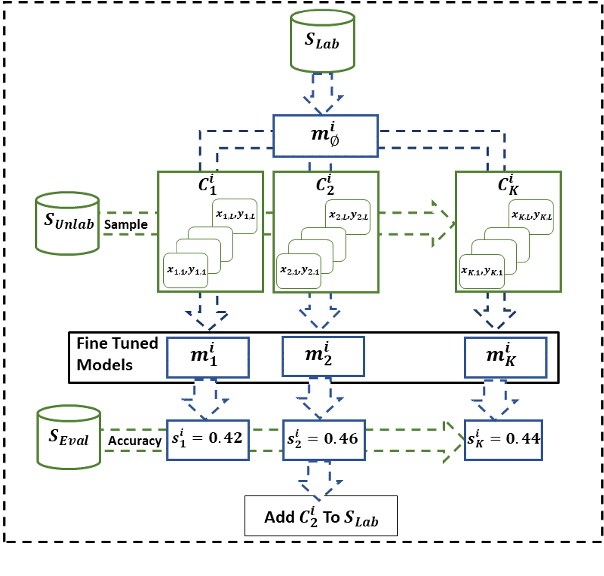

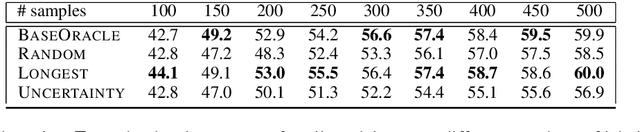
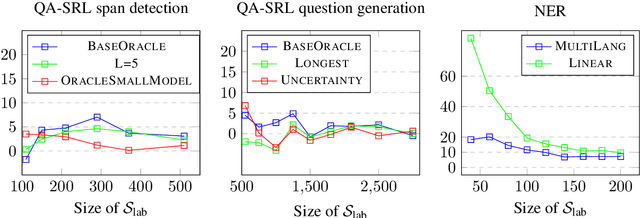
One of the goals of natural language understanding is to develop models that map sentences into meaning representations. However, training such models requires expensive annotation of complex structures, which hinders their adoption. Learning to actively-learn (LTAL) is a recent paradigm for reducing the amount of labeled data by learning a policy that selects which samples should be labeled. In this work, we examine LTAL for learning semantic representations, such as QA-SRL. We show that even an oracle policy that is allowed to pick examples that maximize performance on the test set (and constitutes an upper bound on the potential of LTAL), does not substantially improve performance compared to a random policy. We investigate factors that could explain this finding and show that a distinguishing characteristic of successful applications of LTAL is the interaction between optimization and the oracle policy selection process. In successful applications of LTAL, the examples selected by the oracle policy do not substantially depend on the optimization procedure, while in our setup the stochastic nature of optimization strongly affects the examples selected by the oracle. We conclude that the current applicability of LTAL for improving data efficiency in learning semantic meaning representations is limited.
Text Segmentation as a Supervised Learning Task
Mar 25, 2018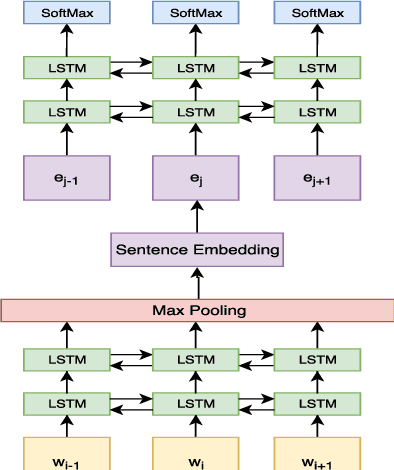
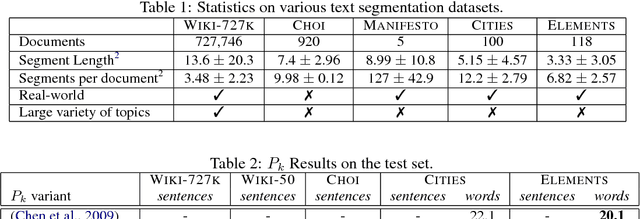
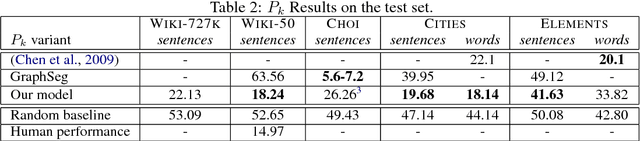
Text segmentation, the task of dividing a document into contiguous segments based on its semantic structure, is a longstanding challenge in language understanding. Previous work on text segmentation focused on unsupervised methods such as clustering or graph search, due to the paucity in labeled data. In this work, we formulate text segmentation as a supervised learning problem, and present a large new dataset for text segmentation that is automatically extracted and labeled from Wikipedia. Moreover, we develop a segmentation model based on this dataset and show that it generalizes well to unseen natural text.