 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocFormerv2: Local Features for Document Understanding
Jun 02, 2023



We propose DocFormerv2, a multi-modal transformer for Visual Document Understanding (VDU). The VDU domain entails understanding documents (beyond mere OCR predictions) e.g., extracting information from a form, VQA for documents and other tasks. VDU is challenging as it needs a model to make sense of multiple modalities (visual, language and spatial) to make a prediction. Our approach, termed DocFormerv2 is an encoder-decoder transformer which takes as input - vision, language and spatial features. DocFormerv2 is pre-trained with unsupervised tasks employed asymmetrically i.e., two novel document tasks on encoder and one on the auto-regressive decoder. The unsupervised tasks have been carefully designed to ensure that the pre-training encourages local-feature alignment between multiple modalities. DocFormerv2 when evaluated on nine datasets shows state-of-the-art performance over strong baselines e.g. TabFact (4.3%), InfoVQA (1.4%), FUNSD (1%). Furthermore, to show generalization capabilities, on three VQA tasks involving scene-text, Doc- Formerv2 outperforms previous comparably-sized models and even does better than much larger models (such as GIT2, PaLi and Flamingo) on some tasks. Extensive ablations show that due to its pre-training, DocFormerv2 understands multiple modalities better than prior-art in VDU.
Anomaly-Injected Deep Support Vector Data Description for Text Outlier Detection
Oct 27, 2021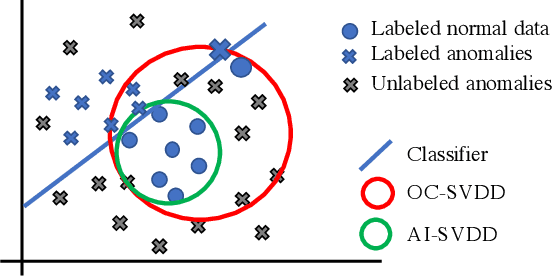
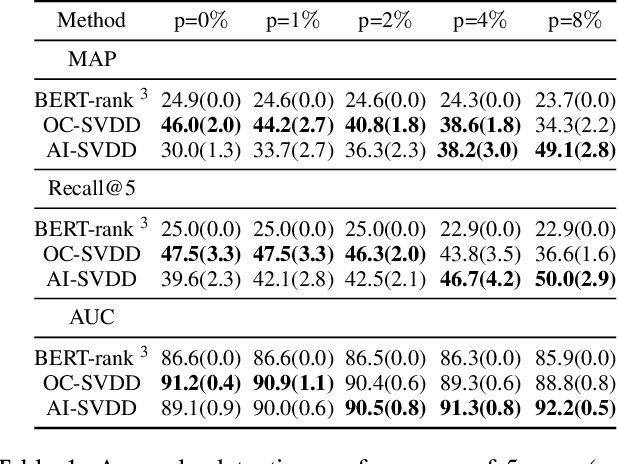
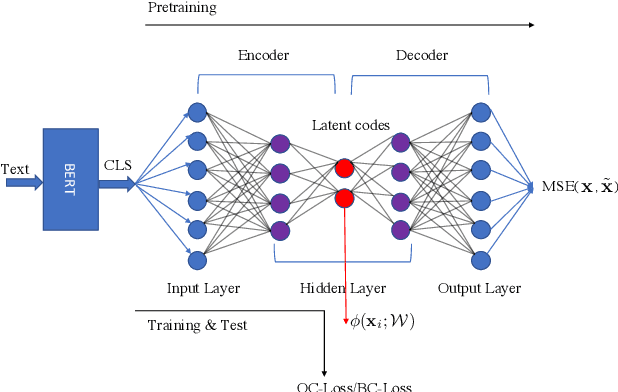
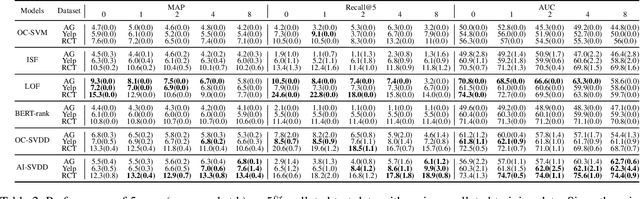
Anomaly detection or outlier detection is a common task in various domains, which has attracted significant research efforts in recent years. Existing works mainly focus on structured data such as numerical or categorical data; however, anomaly detection on unstructured textual data is less attended. In this work, we target the textual anomaly detection problem and propose a deep anomaly-injected support vector data description (AI-SVDD) framework. AI-SVDD not only learns a more compact representation of the data hypersphere but also adopts a small number of known anomalies to increase the discriminative power. To tackle text input, we employ a multilayer perceptron (MLP) network in conjunction with BERT to obtain enriched text representations. We conduct experiments on three text anomaly detection applications with multiple datasets. Experimental results show that the proposed AI-SVDD is promising and outperforms existing works.
Putting Words in BERT's Mouth: Navigating Contextualized Vector Spaces with Pseudowords
Oct 04, 2021



We present a method for exploring regions around individual points in a contextualized vector space (particularly, BERT space), as a way to investigate how these regions correspond to word senses. By inducing a contextualized "pseudoword" as a stand-in for a static embedding in the input layer, and then performing masked prediction of a word in the sentence, we are able to investigate the geometry of the BERT-space in a controlled manner around individual instances. Using our method on a set of carefully constructed sentences targeting ambiguous English words, we find substantial regularity in the contextualized space, with regions that correspond to distinct word senses; but between these regions there are occasionally "sense voids" -- regions that do not correspond to any intelligible sense.
A Closer Look at How Fine-tuning Changes BERT
Jun 27, 2021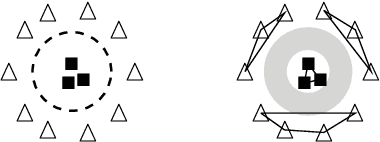


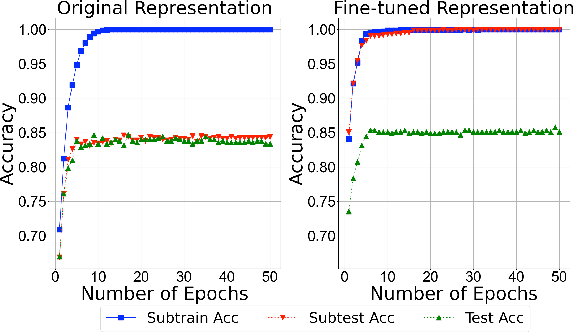
Given the prevalence of pre-trained contextualized representations in today's NLP, there have been several efforts to understand what information such representations contain. A common strategy to use such representations is to fine-tune them for an end task. However, how fine-tuning for a task changes the underlying space is less studied. In this work, we study the English BERT family and use two probing techniques to analyze how fine-tuning changes the space. Our experiments reveal that fine-tuning improves performance because it pushes points associated with a label away from other labels. By comparing the representations before and after fine-tuning, we also discover that fine-tuning does not change the representations arbitrarily; instead, it adjusts the representations to downstream tasks while preserving the original structure. Finally, using carefully constructed experiments, we show that fine-tuning can encode training sets in a representation, suggesting an overfitting problem of a new kind.
DirectProbe: Studying Representations without Classifiers
Apr 13, 2021

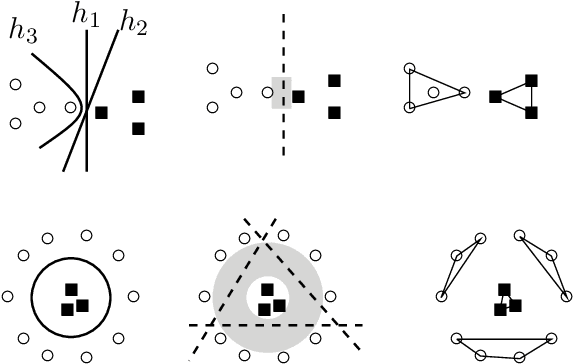

Understanding how linguistic structures are encoded in contextualized embedding could help explain their impressive performance across NLP@. Existing approaches for probing them usually call for training classifiers and use the accuracy, mutual information, or complexity as a proxy for the representation's goodness. In this work, we argue that doing so can be unreliable because different representations may need different classifiers. We develop a heuristic, DirectProbe, that directly studies the geometry of a representation by building upon the notion of a version space for a task. Experiments with several linguistic tasks and contextualized embeddings show that, even without training classifiers, DirectProbe can shine light into how an embedding space represents labels, and also anticipate classifier performance for the representation.
A Simple Global Neural Discourse Parser
Sep 08, 2020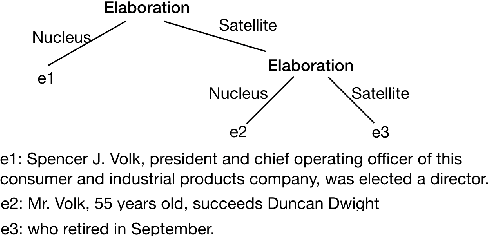
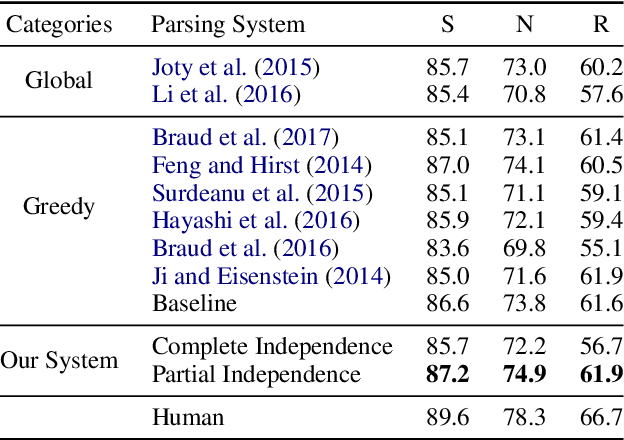
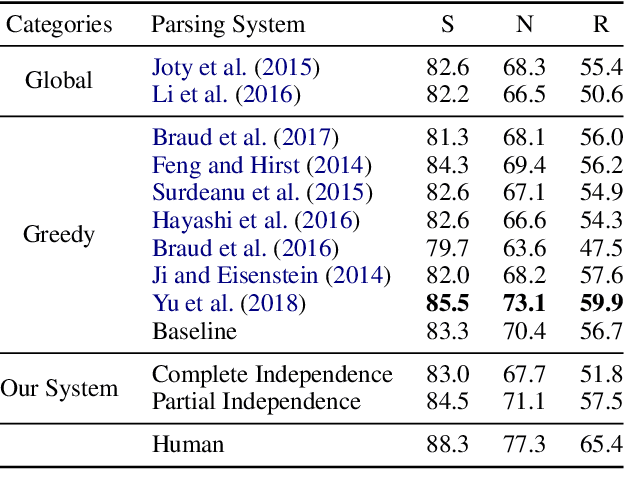
Discourse parsing is largely dominated by greedy parsers with manually-designed features, while global parsing is rare due to its computational expense. In this paper, we propose a simple chart-based neural discourse parser that does not require any manually-crafted features and is based on learned span representations only. To overcome the computational challenge, we propose an independence assumption between the label assigned to a node in the tree and the splitting point that separates its children, which results in tractable decoding. We empirically demonstrate that our model achieves the best performance among global parsers, and comparable performance to state-of-art greedy parsers, using only learned span representations.
On the Limits of Learning to Actively Learn Semantic Representations
Oct 05, 2019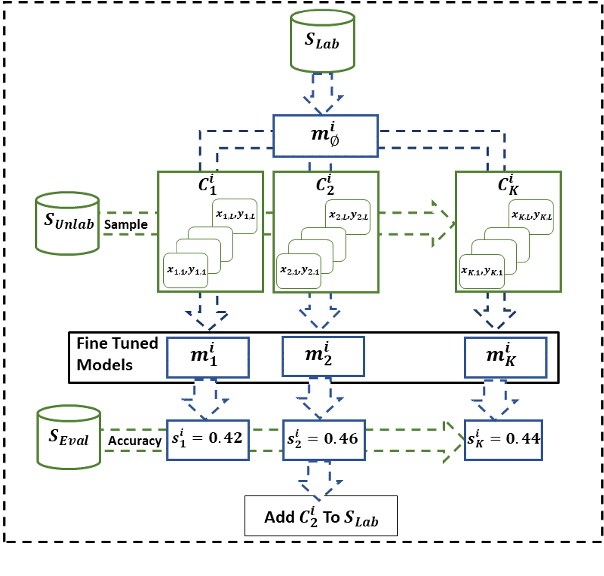

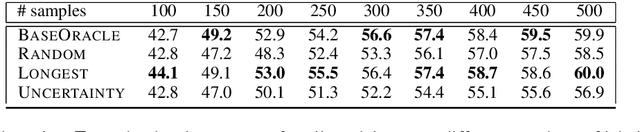
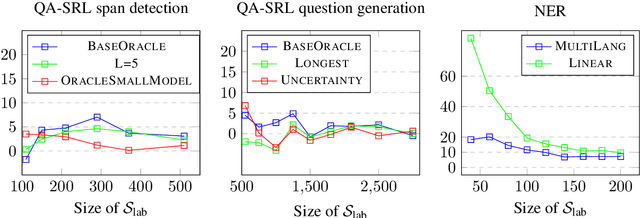
One of the goals of natural language understanding is to develop models that map sentences into meaning representations. However, training such models requires expensive annotation of complex structures, which hinders their adoption. Learning to actively-learn (LTAL) is a recent paradigm for reducing the amount of labeled data by learning a policy that selects which samples should be labeled. In this work, we examine LTAL for learning semantic representations, such as QA-SRL. We show that even an oracle policy that is allowed to pick examples that maximize performance on the test set (and constitutes an upper bound on the potential of LTAL), does not substantially improve performance compared to a random policy. We investigate factors that could explain this finding and show that a distinguishing characteristic of successful applications of LTAL is the interaction between optimization and the oracle policy selection process. In successful applications of LTAL, the examples selected by the oracle policy do not substantially depend on the optimization procedure, while in our setup the stochastic nature of optimization strongly affects the examples selected by the oracle. We conclude that the current applicability of LTAL for improving data efficiency in learning semantic meaning representations is limited.