 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly-Injected Deep Support Vector Data Description for Text Outlier Detection
Oct 27, 2021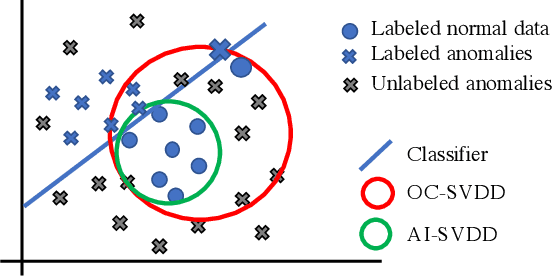
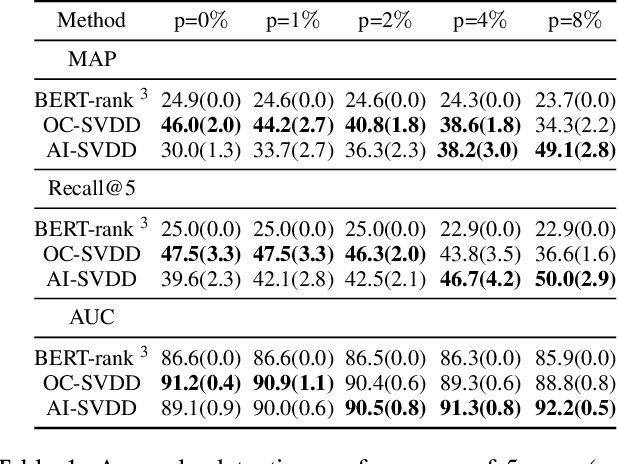
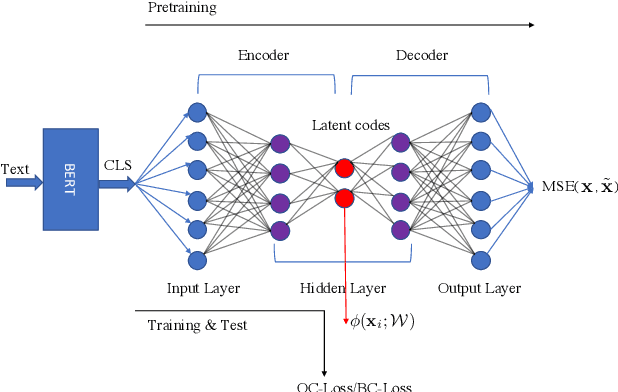
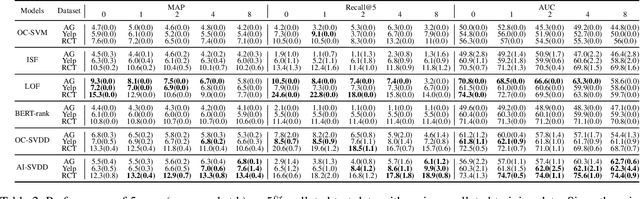
Anomaly detection or outlier detection is a common task in various domains, which has attracted significant research efforts in recent years. Existing works mainly focus on structured data such as numerical or categorical data; however, anomaly detection on unstructured textual data is less attended. In this work, we target the textual anomaly detection problem and propose a deep anomaly-injected support vector data description (AI-SVDD) framework. AI-SVDD not only learns a more compact representation of the data hypersphere but also adopts a small number of known anomalies to increase the discriminative power. To tackle text input, we employ a multilayer perceptron (MLP) network in conjunction with BERT to obtain enriched text representations. We conduct experiments on three text anomaly detection applications with multiple datasets. Experimental results show that the proposed AI-SVDD is promising and outperforms existing works.
Multiplex Graph Neural Network for Extractive Text Summarization
Sep 09, 2021
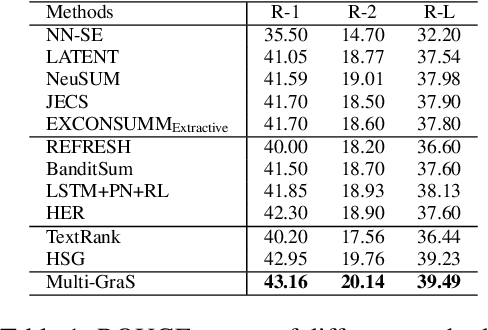

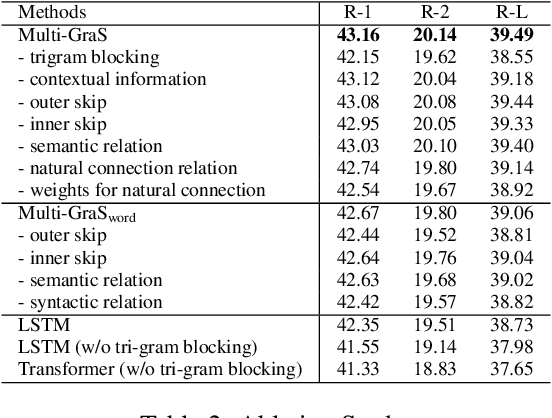
Extractive text summarization aims at extracting the most representative sentences from a given document as its summary. To extract a good summary from a long text document, sentence embedding plays an important role. Recent studies have leveraged graph neural networks to capture the inter-sentential relationship (e.g., the discourse graph) to learn contextual sentence embedding. However, those approaches neither consider multiple types of inter-sentential relationships (e.g., semantic similarity & natural connection), nor model intra-sentential relationships (e.g, semantic & syntactic relationship among words). To address these problems, we propose a novel Multiplex Graph Convolutional Network (Multi-GCN) to jointly model different types of relationships among sentences and words. Based on Multi-GCN, we propose a Multiplex Graph Summarization (Multi-GraS) model for extractive text summarization. Finally, we evaluate the proposed models on the CNN/DailyMail benchmark dataset to demonstrate the effectiveness of our method.
Commonsense Evidence Generation and Injection in Reading Comprehension
May 11, 2020
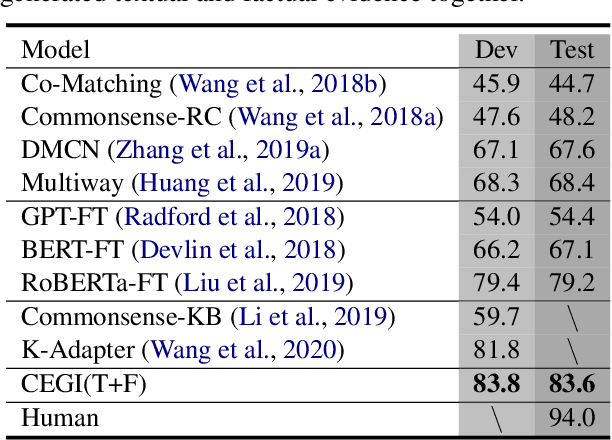

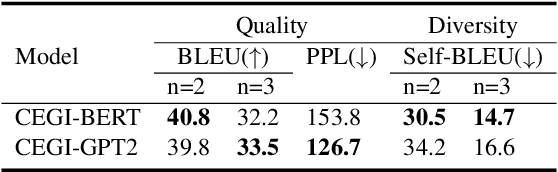
Human tackle reading comprehension not only based on the given context itself but often rely on the commonsense beyond. To empower the machine with commonsense reasoning, in this paper, we propose a Commonsense Evidence Generation and Injection framework in reading comprehension, named CEGI. The framework injects two kinds of auxiliary commonsense evidence into comprehensive reading to equip the machine with the ability of rational thinking. Specifically, we build two evidence generators: the first generator aims to generate textual evidence via a language model; the other generator aims to extract factual evidence (automatically aligned text-triples) from a commonsense knowledge graph after graph completion. Those evidences incorporate contextual commonsense and serve as the additional inputs to the model. Thereafter, we propose a deep contextual encoder to extract semantic relationships among the paragraph, question, option, and evidence. Finally, we employ a capsule network to extract different linguistic units (word and phrase) from the relations, and dynamically predict the optimal option based on the extracted units. Experiments on the CosmosQA dataset demonstrate that the proposed CEGI model outperforms the current state-of-the-art approaches and achieves the accuracy (83.6%) on the leaderboard.
Weakly-supervised Dictionary Learning
Feb 05, 2018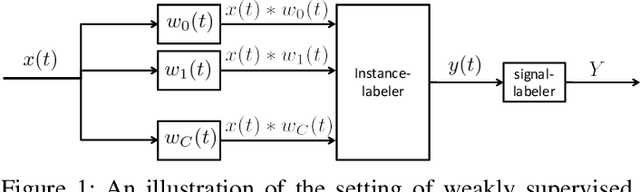

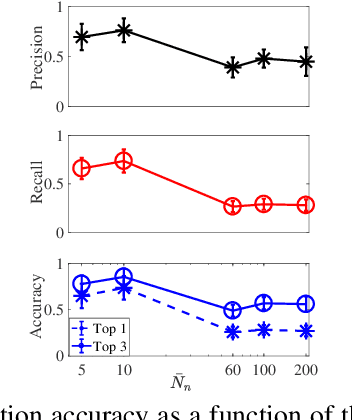
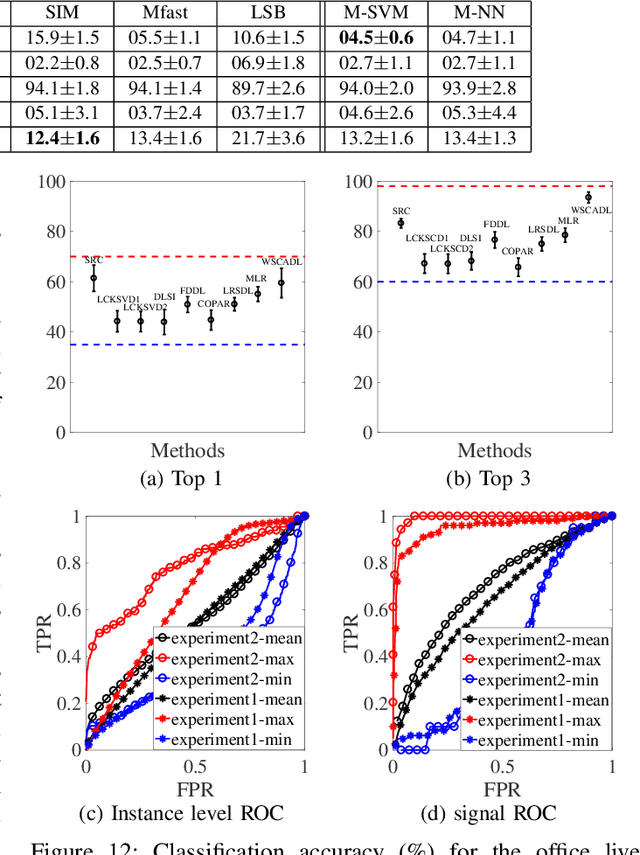
We present a probabilistic modeling and inference framework for discriminative analysis dictionary learning under a weak supervision setting. Dictionary learning approaches have been widely used for tasks such as low-level signal denoising and restoration as well as high-level classification tasks, which can be applied to audio and image analysis. Synthesis dictionary learning aims at jointly learning a dictionary and corresponding sparse coefficients to provide accurate data representation. This approach is useful for denoising and signal restoration, but may lead to sub-optimal classification performance. By contrast, analysis dictionary learning provides a transform that maps data to a sparse discriminative representation suitable for classification. We consider the problem of analysis dictionary learning for time-series data under a weak supervision setting in which signals are assigned with a global label instead of an instantaneous label signal. We propose a discriminative probabilistic model that incorporates both label information and sparsity constraints on the underlying latent instantaneous label signal using cardinality control. We present the expectation maximization (EM) procedure for maximum likelihood estimation (MLE) of the proposed model. To facilitate a computationally efficient E-step, we propose both a chain and a novel tree graph reformulation of the graphical model. The performance of the proposed model is demonstrated on both synthetic and real-world data.