 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards GUI Agents: Vision-Language Diffusion Models for GUI Grounding
Mar 27, 2026Autoregressive (AR) vision-language models (VLMs) have long dominated multimodal understanding, reasoning, and graphical user interface (GUI) grounding. Recently, discrete diffusion vision-language models (DVLMs) have shown strong performance in multimodal reasoning, offering bidirectional attention, parallel token generation, and iterative refinement. However, their potential for GUI grounding remains unexplored. In this work, we evaluate whether discrete DVLMs can serve as a viable alternative to AR models for GUI grounding. We adapt LLaDA-V for single-turn action and bounding-box prediction, framing the task as text generation from multimodal input. To better capture the hierarchical structure of bounding-box geometry, we propose a hybrid masking schedule that combines linear and deterministic masking, improving grounding accuracy by up to 6.1 points in Step Success Rate (SSR) over the GUI-adapted LLaDA-V trained with linear masking. Evaluations on four datasets spanning web, desktop, and mobile interfaces show that the adapted diffusion model with hybrid masking consistently outperforms the linear-masked variant and performs competitively with autoregressive counterparts despite limited pretraining. Systematic ablations reveal that increasing diffusion steps, generation length, and block length improves accuracy but also increases latency, with accuracy plateauing beyond a certain number of diffusion steps. Expanding the training data with diverse GUI domains further reduces latency by about 1.3 seconds and improves grounding accuracy by an average of 20 points across benchmarks. These results demonstrate that discrete DVLMs are a promising modeling framework for GUI grounding and represent an important step toward diffusion-based GUI agents.
DocKD: Knowledge Distillation from LLMs for Open-World Document Understanding Models
Oct 04, 2024



Visual document understanding (VDU) is a challenging task that involves understanding documents across various modalities (text and image) and layouts (forms, tables, etc.). This study aims to enhance generalizability of small VDU models by distilling knowledge from LLMs. We identify that directly prompting LLMs often fails to generate informative and useful data. In response, we present a new framework (called DocKD) that enriches the data generation process by integrating external document knowledge. Specifically, we provide an LLM with various document elements like key-value pairs, layouts, and descriptions, to elicit open-ended answers. Our experiments show that DocKD produces high-quality document annotations and surpasses the direct knowledge distillation approach that does not leverage external document knowledge. Moreover, student VDU models trained with solely DocKD-generated data are not only comparable to those trained with human-annotated data on in-domain tasks but also significantly excel them on out-of-domain tasks.
VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding
Jul 17, 2024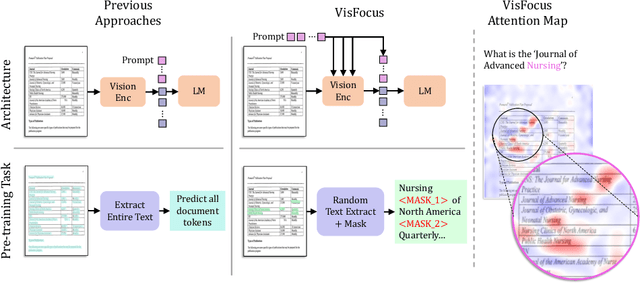
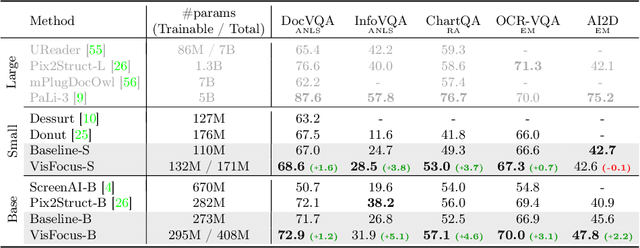
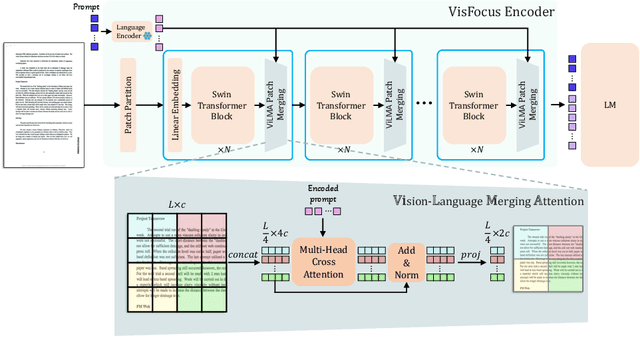

In recent years, notable advancements have been made in the domain of visual document understanding, with the prevailing architecture comprising a cascade of vision and language models. The text component can either be extracted explicitly with the use of external OCR models in OCR-based approaches, or alternatively, the vision model can be endowed with reading capabilities in OCR-free approaches. Typically, the queries to the model are input exclusively to the language component, necessitating the visual features to encompass the entire document. In this paper, we present VisFocus, an OCR-free method designed to better exploit the vision encoder's capacity by coupling it directly with the language prompt. To do so, we replace the down-sampling layers with layers that receive the input prompt and allow highlighting relevant parts of the document, while disregarding others. We pair the architecture enhancements with a novel pre-training task, using language masking on a snippet of the document text fed to the visual encoder in place of the prompt, to empower the model with focusing capabilities. Consequently, VisFocus learns to allocate its attention to text patches pertinent to the provided prompt. Our experiments demonstrate that this prompt-guided visual encoding approach significantly improves performance, achieving state-of-the-art results on various benchmarks.
RAVEN: Multitask Retrieval Augmented Vision-Language Learning
Jun 27, 2024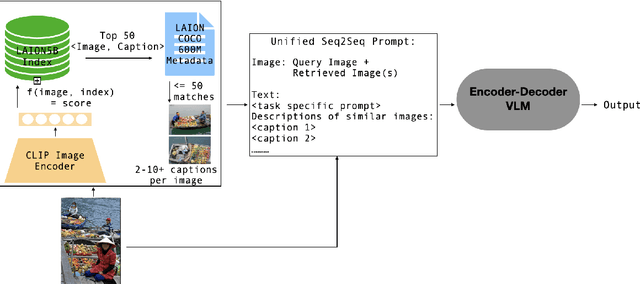
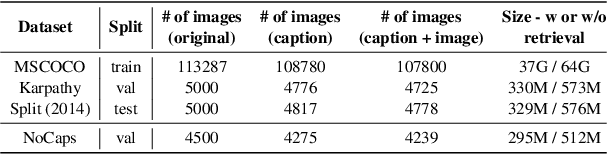
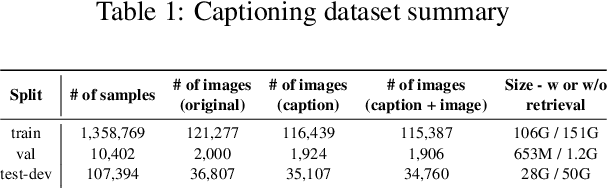

The scaling of large language models to encode all the world's knowledge in model parameters is unsustainable and has exacerbated resource barriers. Retrieval-Augmented Generation (RAG) presents a potential solution, yet its application to vision-language models (VLMs) is under explored. Existing methods focus on models designed for single tasks. Furthermore, they're limited by the need for resource intensive pre training, additional parameter requirements, unaddressed modality prioritization and lack of clear benefit over non-retrieval baselines. This paper introduces RAVEN, a multitask retrieval augmented VLM framework that enhances base VLMs through efficient, task specific fine-tuning. By integrating retrieval augmented samples without the need for additional retrieval-specific parameters, we show that the model acquires retrieval properties that are effective across multiple tasks. Our results and extensive ablations across retrieved modalities for the image captioning and VQA tasks indicate significant performance improvements compared to non retrieved baselines +1 CIDEr on MSCOCO, +4 CIDEr on NoCaps and nearly a +3\% accuracy on specific VQA question types. This underscores the efficacy of applying RAG approaches to VLMs, marking a stride toward more efficient and accessible multimodal learning.
Enhancing Vision-Language Pre-training with Rich Supervisions
Mar 05, 2024



We propose Strongly Supervised pre-training with ScreenShots (S4) - a novel pre-training paradigm for Vision-Language Models using data from large-scale web screenshot rendering. Using web screenshots unlocks a treasure trove of visual and textual cues that are not present in using image-text pairs. In S4, we leverage the inherent tree-structured hierarchy of HTML elements and the spatial localization to carefully design 10 pre-training tasks with large scale annotated data. These tasks resemble downstream tasks across different domains and the annotations are cheap to obtain. We demonstrate that, compared to current screenshot pre-training objectives, our innovative pre-training method significantly enhances performance of image-to-text model in nine varied and popular downstream tasks - up to 76.1% improvements on Table Detection, and at least 1% on Widget Captioning.
DEED: Dynamic Early Exit on Decoder for Accelerating Encoder-Decoder Transformer Models
Nov 15, 2023Encoder-decoder transformer models have achieved great success on various vision-language (VL) tasks, but they suffer from high inference latency. Typically, the decoder takes up most of the latency because of the auto-regressive decoding. To accelerate the inference, we propose an approach of performing Dynamic Early Exit on Decoder (DEED). We build a multi-exit encoder-decoder transformer model which is trained with deep supervision so that each of its decoder layers is capable of generating plausible predictions. In addition, we leverage simple yet practical techniques, including shared generation head and adaptation modules, to keep accuracy when exiting at shallow decoder layers. Based on the multi-exit model, we perform step-level dynamic early exit during inference, where the model may decide to use fewer decoder layers based on its confidence of the current layer at each individual decoding step. Considering different number of decoder layers may be used at different decoding steps, we compute deeper-layer decoder features of previous decoding steps just-in-time, which ensures the features from different decoding steps are semantically aligned. We evaluate our approach with two state-of-the-art encoder-decoder transformer models on various VL tasks. We show our approach can reduce overall inference latency by 30%-60% with comparable or even higher accuracy compared to baselines.
Multiple-Question Multiple-Answer Text-VQA
Nov 15, 2023



We present Multiple-Question Multiple-Answer (MQMA), a novel approach to do text-VQA in encoder-decoder transformer models. The text-VQA task requires a model to answer a question by understanding multi-modal content: text (typically from OCR) and an associated image. To the best of our knowledge, almost all previous approaches for text-VQA process a single question and its associated content to predict a single answer. In order to answer multiple questions from the same image, each question and content are fed into the model multiple times. In contrast, our proposed MQMA approach takes multiple questions and content as input at the encoder and predicts multiple answers at the decoder in an auto-regressive manner at the same time. We make several novel architectural modifications to standard encoder-decoder transformers to support MQMA. We also propose a novel MQMA denoising pre-training task which is designed to teach the model to align and delineate multiple questions and content with associated answers. MQMA pre-trained model achieves state-of-the-art results on multiple text-VQA datasets, each with strong baselines. Specifically, on OCR-VQA (+2.5%), TextVQA (+1.4%), ST-VQA (+0.6%), DocVQA (+1.1%) absolute improvements over the previous state-of-the-art approaches.
A Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023



Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
DocFormerv2: Local Features for Document Understanding
Jun 02, 2023



We propose DocFormerv2, a multi-modal transformer for Visual Document Understanding (VDU). The VDU domain entails understanding documents (beyond mere OCR predictions) e.g., extracting information from a form, VQA for documents and other tasks. VDU is challenging as it needs a model to make sense of multiple modalities (visual, language and spatial) to make a prediction. Our approach, termed DocFormerv2 is an encoder-decoder transformer which takes as input - vision, language and spatial features. DocFormerv2 is pre-trained with unsupervised tasks employed asymmetrically i.e., two novel document tasks on encoder and one on the auto-regressive decoder. The unsupervised tasks have been carefully designed to ensure that the pre-training encourages local-feature alignment between multiple modalities. DocFormerv2 when evaluated on nine datasets shows state-of-the-art performance over strong baselines e.g. TabFact (4.3%), InfoVQA (1.4%), FUNSD (1%). Furthermore, to show generalization capabilities, on three VQA tasks involving scene-text, Doc- Formerv2 outperforms previous comparably-sized models and even does better than much larger models (such as GIT2, PaLi and Flamingo) on some tasks. Extensive ablations show that due to its pre-training, DocFormerv2 understands multiple modalities better than prior-art in VDU.
SimCon Loss with Multiple Views for Text Supervised Semantic Segmentation
Feb 07, 2023



Learning to segment images purely by relying on the image-text alignment from web data can lead to sub-optimal performance due to noise in the data. The noise comes from the samples where the associated text does not correlate with the image's visual content. Instead of purely relying on the alignment from the noisy data, this paper proposes a novel loss function termed SimCon, which accounts for intra-modal similarities to determine the appropriate set of positive samples to align. Further, using multiple views of the image (created synthetically) for training and combining the SimCon loss with it makes the training more robust. This version of the loss is termed MV-SimCon. The empirical results demonstrate that using the proposed loss function leads to consistent improvements on zero-shot, text supervised semantic segmentation and outperforms state-of-the-art by $+3.0\%$, $+3.3\%$ and $+6.9\%$ on PASCAL VOC, PASCAL Context and MSCOCO, respectively. With test time augmentations, we set a new record by improving these results further to $58.7\%$, $26.6\%$, and $33.3\%$ on PASCAL VOC, PASCAL Context, and MSCOCO, respectively. In addition, using the proposed loss function leads to robust training and faster convergence.