 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Multilingual Benchmark for Document Image Classification
Oct 25, 2023



Document image classification is different from plain-text document classification and consists of classifying a document by understanding the content and structure of documents such as forms, emails, and other such documents. We show that the only existing dataset for this task (Lewis et al., 2006) has several limitations and we introduce two newly curated multilingual datasets WIKI-DOC and MULTIEURLEX-DOC that overcome these limitations. We further undertake a comprehensive study of popular visually-rich document understanding or Document AI models in previously untested setting in document image classification such as 1) multi-label classification, and 2) zero-shot cross-lingual transfer setup. Experimental results show limitations of multilingual Document AI models on cross-lingual transfer across typologically distant languages. Our datasets and findings open the door for future research into improving Document AI models.
DocFormerv2: Local Features for Document Understanding
Jun 02, 2023



We propose DocFormerv2, a multi-modal transformer for Visual Document Understanding (VDU). The VDU domain entails understanding documents (beyond mere OCR predictions) e.g., extracting information from a form, VQA for documents and other tasks. VDU is challenging as it needs a model to make sense of multiple modalities (visual, language and spatial) to make a prediction. Our approach, termed DocFormerv2 is an encoder-decoder transformer which takes as input - vision, language and spatial features. DocFormerv2 is pre-trained with unsupervised tasks employed asymmetrically i.e., two novel document tasks on encoder and one on the auto-regressive decoder. The unsupervised tasks have been carefully designed to ensure that the pre-training encourages local-feature alignment between multiple modalities. DocFormerv2 when evaluated on nine datasets shows state-of-the-art performance over strong baselines e.g. TabFact (4.3%), InfoVQA (1.4%), FUNSD (1%). Furthermore, to show generalization capabilities, on three VQA tasks involving scene-text, Doc- Formerv2 outperforms previous comparably-sized models and even does better than much larger models (such as GIT2, PaLi and Flamingo) on some tasks. Extensive ablations show that due to its pre-training, DocFormerv2 understands multiple modalities better than prior-art in VDU.
CAN: Composite Appearance Network and a Novel Evaluation Metric for Person Tracking
Nov 15, 2018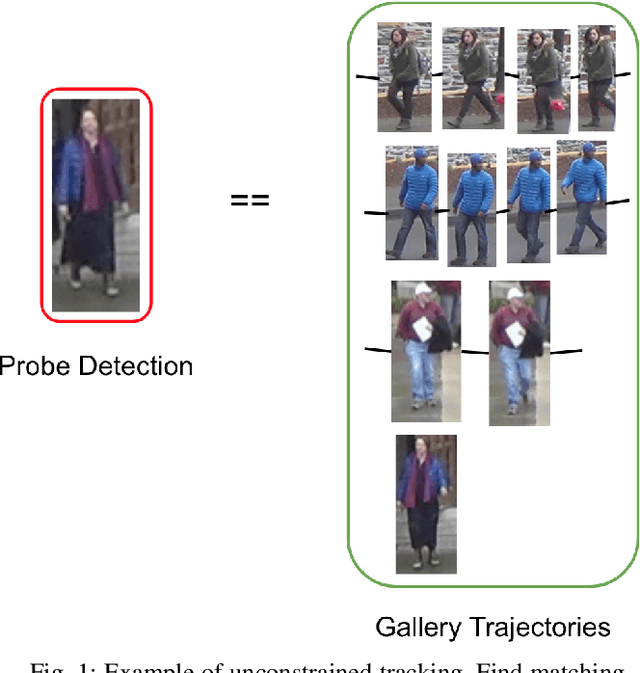
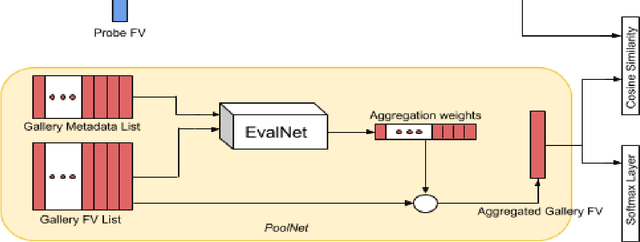
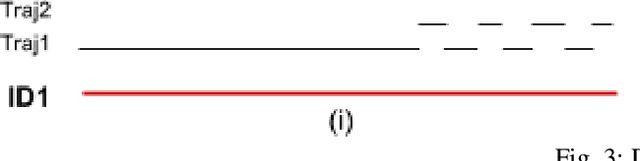
Tracking multiple people across multiple cameras is an open problem. It is typically divided into two tasks: (i) single-camera tracking (SCT) - identify trajectories in the same scene, and (ii) inter-camera tracking (ICT) - identify trajectories across cameras for real surveillance scenes. Many of the existing methods cater to single camera person tracking, while inter-camera tracking still remains a challenge. In this paper, we propose a tracking method which uses motion cues and a feature aggregation network for template-based person re-identification by incorporating metadata such as person bounding box and camera information. We present an architecture called Composite Appearance Network (CAN) to address the above problem. The key structure of this architecture is a network called EvalNet that pays attention to each feature vector independently and learns to weight them based on gradients it receives for the overall template for optimal re-identification performance. We demonstrate the efficiency of our approach with experiments on the challenging and large-scale multi-camera tracking dataset, DukeMTMC, and by comparing results to their baseline approach. We also survey existing tracking measures and present an online error metric called "Inference Error" (IE) that provides a better estimate of tracking/re-identification error, by treating within-camera and inter-camera errors uniformly.