 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAN: Composite Appearance Network and a Novel Evaluation Metric for Person Tracking
Paper and Code
Nov 15, 2018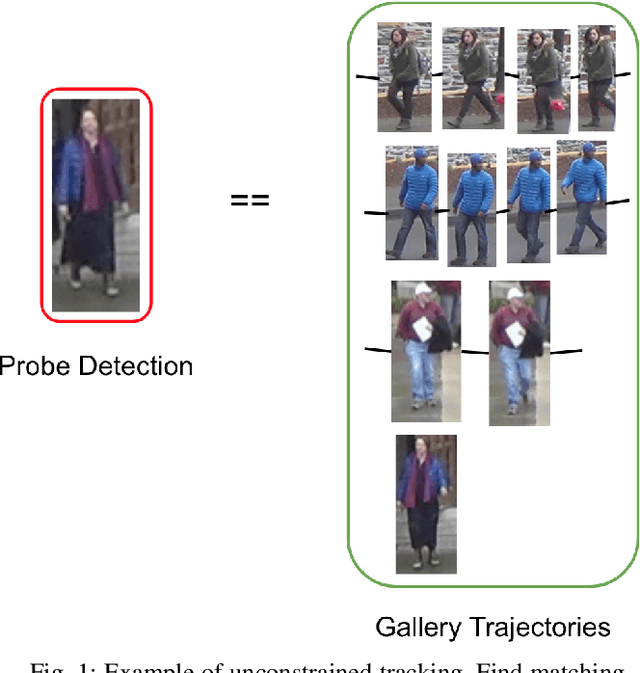
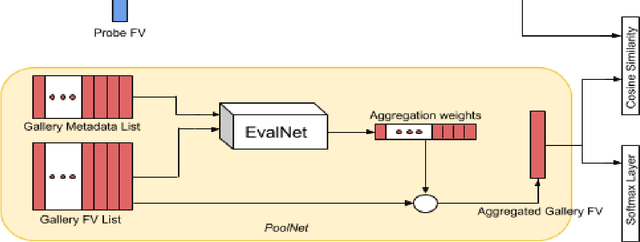
Tracking multiple people across multiple cameras is an open problem. It is typically divided into two tasks: (i) single-camera tracking (SCT) - identify trajectories in the same scene, and (ii) inter-camera tracking (ICT) - identify trajectories across cameras for real surveillance scenes. Many of the existing methods cater to single camera person tracking, while inter-camera tracking still remains a challenge. In this paper, we propose a tracking method which uses motion cues and a feature aggregation network for template-based person re-identification by incorporating metadata such as person bounding box and camera information. We present an architecture called Composite Appearance Network (CAN) to address the above problem. The key structure of this architecture is a network called EvalNet that pays attention to each feature vector independently and learns to weight them based on gradients it receives for the overall template for optimal re-identification performance. We demonstrate the efficiency of our approach with experiments on the challenging and large-scale multi-camera tracking dataset, DukeMTMC, and by comparing results to their baseline approach. We also survey existing tracking measures and present an online error metric called "Inference Error" (IE) that provides a better estimate of tracking/re-identification error, by treating within-camera and inter-camera errors uniformly.