 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocVLM: Make Your VLM an Efficient Reader
Dec 11, 2024



Vision-Language Models (VLMs) excel in diverse visual tasks but face challenges in document understanding, which requires fine-grained text processing. While typical visual tasks perform well with low-resolution inputs, reading-intensive applications demand high-resolution, resulting in significant computational overhead. Using OCR-extracted text in VLM prompts partially addresses this issue but underperforms compared to full-resolution counterpart, as it lacks the complete visual context needed for optimal performance. We introduce DocVLM, a method that integrates an OCR-based modality into VLMs to enhance document processing while preserving original weights. Our approach employs an OCR encoder to capture textual content and layout, compressing these into a compact set of learned queries incorporated into the VLM. Comprehensive evaluations across leading VLMs show that DocVLM significantly reduces reliance on high-resolution images for document understanding. In limited-token regimes (448$\times$448), DocVLM with 64 learned queries improves DocVQA results from 56.0% to 86.6% when integrated with InternVL2 and from 84.4% to 91.2% with Qwen2-VL. In LLaVA-OneVision, DocVLM achieves improved results while using 80% less image tokens. The reduced token usage allows processing multiple pages effectively, showing impressive zero-shot results on DUDE and state-of-the-art performance on MP-DocVQA, highlighting DocVLM's potential for applications requiring high-performance and efficiency.
TAP-VL: Text Layout-Aware Pre-training for Enriched Vision-Language Models
Nov 07, 2024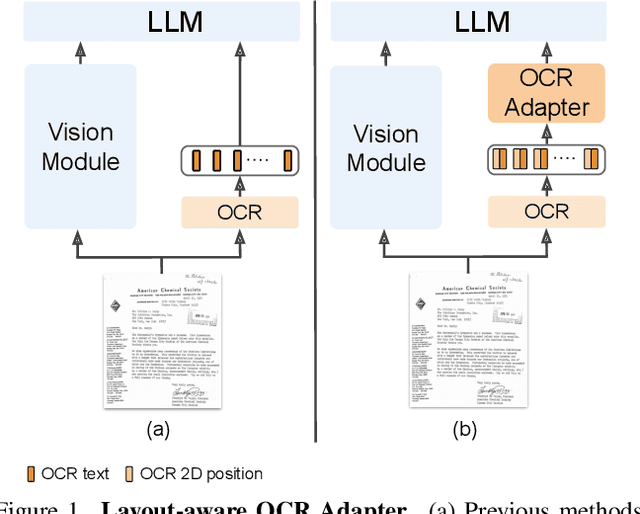
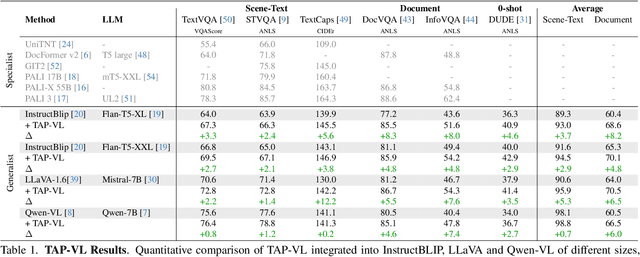
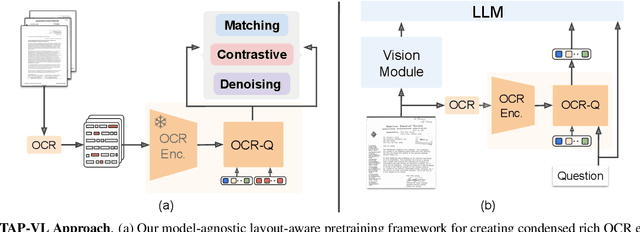
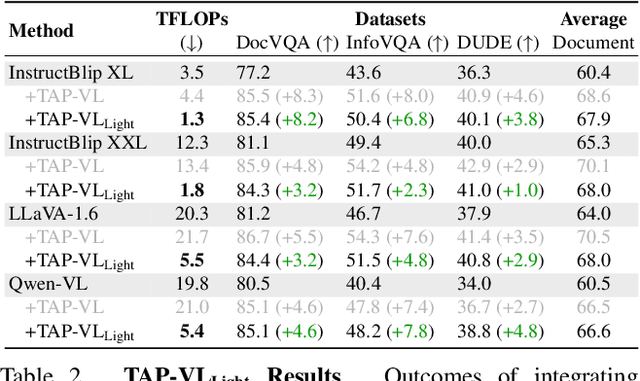
Vision-Language (VL) models have garnered considerable research interest; however, they still face challenges in effectively handling text within images. To address this limitation, researchers have developed two approaches. The first method involves utilizing external Optical Character Recognition (OCR) tools to extract textual information from images, which is then prepended to other textual inputs. The second strategy focuses on employing extremely high-resolution images to improve text recognition capabilities. In this paper, we focus on enhancing the first strategy by introducing a novel method, named TAP-VL, which treats OCR information as a distinct modality and seamlessly integrates it into any VL model. TAP-VL employs a lightweight transformer-based OCR module to receive OCR with layout information, compressing it into a short fixed-length sequence for input into the LLM. Initially, we conduct model-agnostic pretraining of the OCR module on unlabeled documents, followed by its integration into any VL architecture through brief fine-tuning. Extensive experiments demonstrate consistent performance improvements when applying TAP-VL to top-performing VL models, across scene-text and document-based VL benchmarks.
VisFocus: Prompt-Guided Vision Encoders for OCR-Free Dense Document Understanding
Jul 17, 2024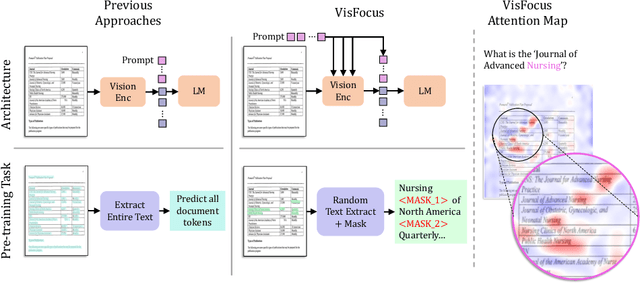
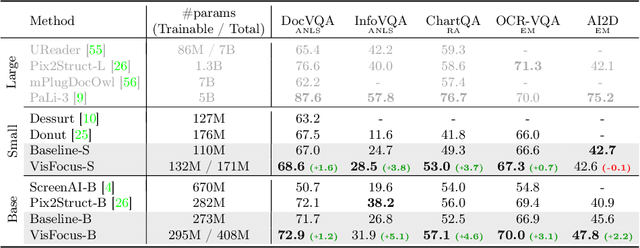
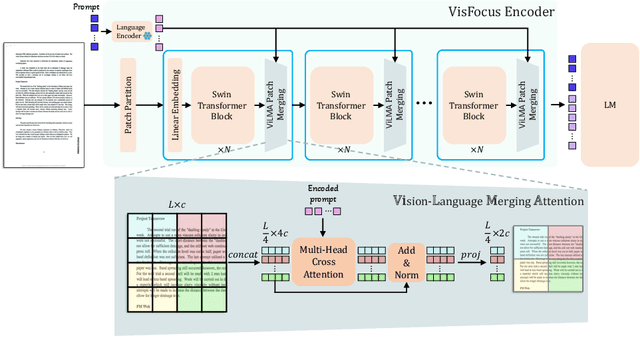

In recent years, notable advancements have been made in the domain of visual document understanding, with the prevailing architecture comprising a cascade of vision and language models. The text component can either be extracted explicitly with the use of external OCR models in OCR-based approaches, or alternatively, the vision model can be endowed with reading capabilities in OCR-free approaches. Typically, the queries to the model are input exclusively to the language component, necessitating the visual features to encompass the entire document. In this paper, we present VisFocus, an OCR-free method designed to better exploit the vision encoder's capacity by coupling it directly with the language prompt. To do so, we replace the down-sampling layers with layers that receive the input prompt and allow highlighting relevant parts of the document, while disregarding others. We pair the architecture enhancements with a novel pre-training task, using language masking on a snippet of the document text fed to the visual encoder in place of the prompt, to empower the model with focusing capabilities. Consequently, VisFocus learns to allocate its attention to text patches pertinent to the provided prompt. Our experiments demonstrate that this prompt-guided visual encoding approach significantly improves performance, achieving state-of-the-art results on various benchmarks.
M3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Jun 12, 2024
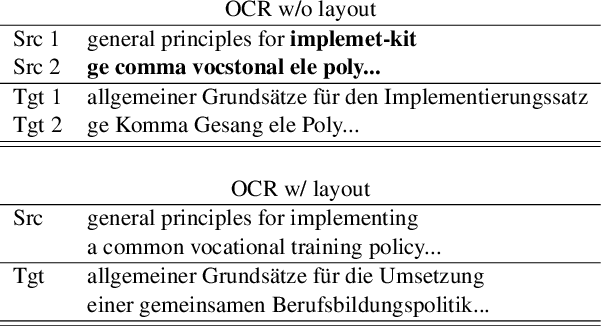

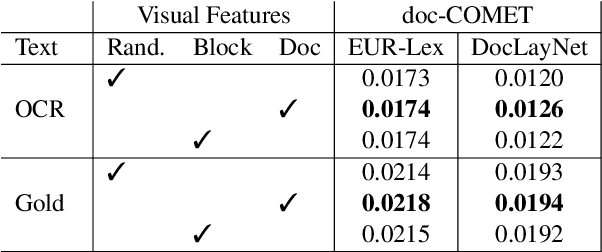
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.
Question Aware Vision Transformer for Multimodal Reasoning
Feb 08, 2024


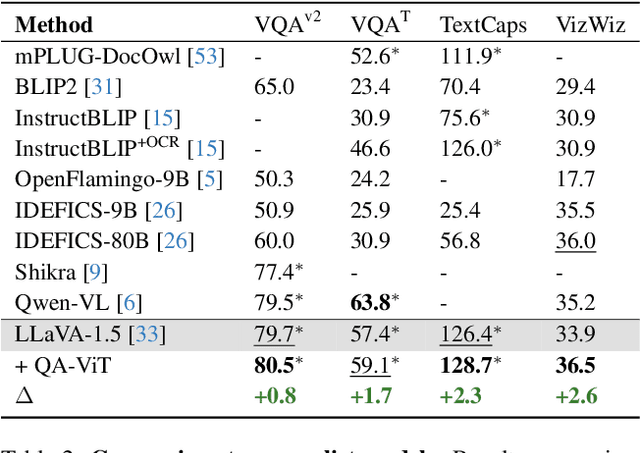
Vision-Language (VL) models have gained significant research focus, enabling remarkable advances in multimodal reasoning. These architectures typically comprise a vision encoder, a Large Language Model (LLM), and a projection module that aligns visual features with the LLM's representation space. Despite their success, a critical limitation persists: the vision encoding process remains decoupled from user queries, often in the form of image-related questions. Consequently, the resulting visual features may not be optimally attuned to the query-specific elements of the image. To address this, we introduce QA-ViT, a Question Aware Vision Transformer approach for multimodal reasoning, which embeds question awareness directly within the vision encoder. This integration results in dynamic visual features focusing on relevant image aspects to the posed question. QA-ViT is model-agnostic and can be incorporated efficiently into any VL architecture. Extensive experiments demonstrate the effectiveness of applying our method to various multimodal architectures, leading to consistent improvement across diverse tasks and showcasing its potential for enhancing visual and scene-text understanding.
GRAM: Global Reasoning for Multi-Page VQA
Jan 07, 2024


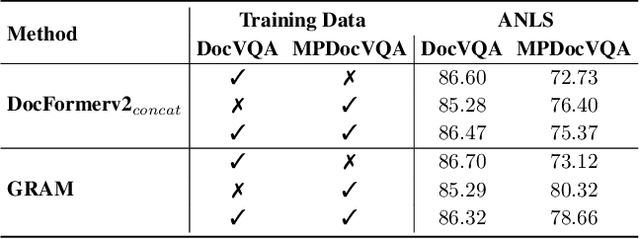
The increasing use of transformer-based large language models brings forward the challenge of processing long sequences. In document visual question answering (DocVQA), leading methods focus on the single-page setting, while documents can span hundreds of pages. We present GRAM, a method that seamlessly extends pre-trained single-page models to the multi-page setting, without requiring computationally-heavy pretraining. To do so, we leverage a single-page encoder for local page-level understanding, and enhance it with document-level designated layers and learnable tokens, facilitating the flow of information across pages for global reasoning. To enforce our model to utilize the newly introduced document-level tokens, we propose a tailored bias adaptation method. For additional computational savings during decoding, we introduce an optional compression stage using our C-Former model, which reduces the encoded sequence length, thereby allowing a tradeoff between quality and latency. Extensive experiments showcase GRAM's state-of-the-art performance on the benchmarks for multi-page DocVQA, demonstrating the effectiveness of our approach.
Towards Models that Can See and Read
Jan 18, 2023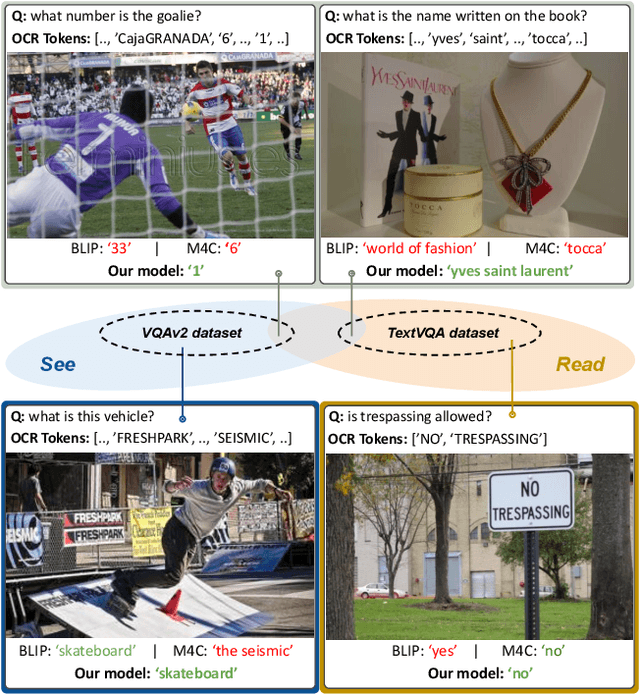
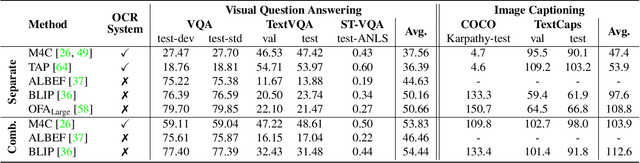
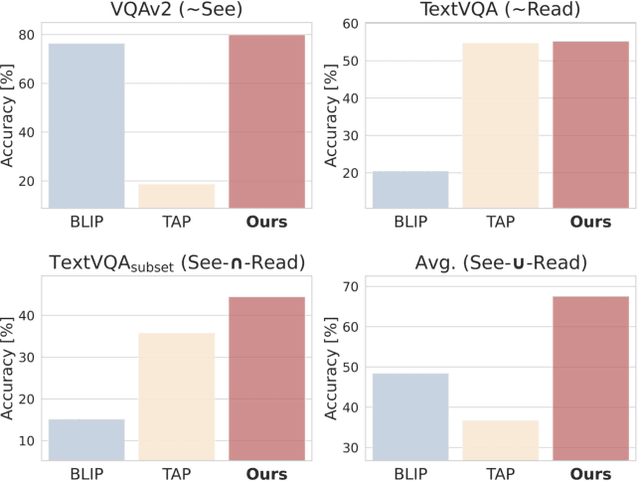

Visual Question Answering (VQA) and Image Captioning (CAP), which are among the most popular vision-language tasks, have analogous scene-text versions that require reasoning from the text in the image. Despite the obvious resemblance between them, the two are treated independently, yielding task-specific methods that can either see or read, but not both. In this work, we conduct an in-depth analysis of this phenomenon and propose UniTNT, a Unified Text-Non-Text approach, which grants existing multimodal architectures scene-text understanding capabilities. Specifically, we treat scene-text information as an additional modality, fusing it with any pretrained encoder-decoder-based architecture via designated modules. Thorough experiments reveal that UniTNT leads to the first single model that successfully handles both task types. Moreover, we show that scene-text understanding capabilities can boost vision-language models' performance on VQA and CAP by up to 3.49% and 0.7 CIDEr, respectively.
CLIPTER: Looking at the Bigger Picture in Scene Text Recognition
Jan 18, 2023
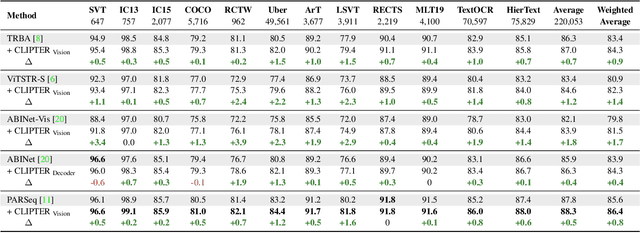
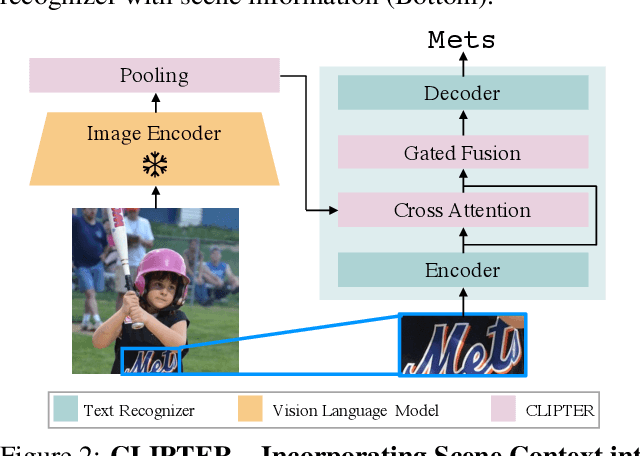

Understanding the scene is often essential for reading text in real-world scenarios. However, current scene text recognizers operate on cropped text images, unaware of the bigger picture. In this work, we harness the representative power of recent vision-language models, such as CLIP, to provide the crop-based recognizer with scene, image-level information. Specifically, we obtain a rich representation of the entire image and fuse it with the recognizer word-level features via cross-attention. Moreover, a gated mechanism is introduced that gradually shifts to the context-enriched representation, enabling simply fine-tuning a pretrained recognizer. We implement our model-agnostic framework, named CLIPTER - CLIP Text Recognition, on several leading text recognizers and demonstrate consistent performance gains, achieving state-of-the-art results over multiple benchmarks. Furthermore, an in-depth analysis reveals improved robustness to out-of-vocabulary words and enhanced generalization in low-data regimes.
Out-of-Vocabulary Challenge Report
Sep 14, 2022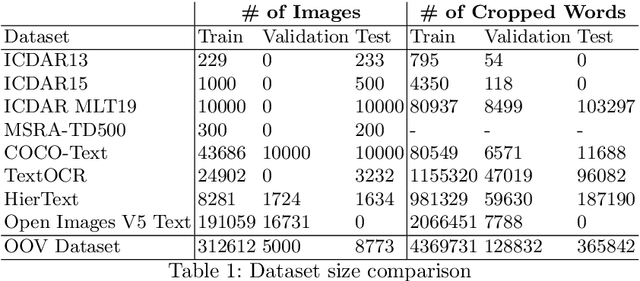
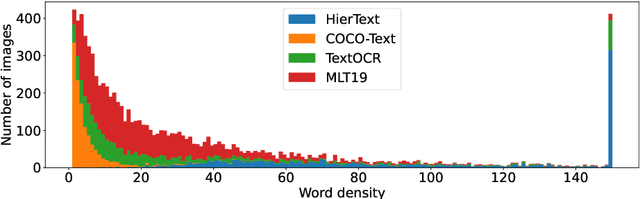

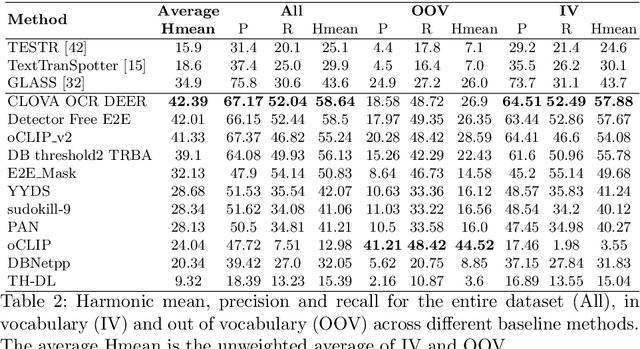
This paper presents final results of the Out-Of-Vocabulary 2022 (OOV) challenge. The OOV contest introduces an important aspect that is not commonly studied by Optical Character Recognition (OCR) models, namely, the recognition of unseen scene text instances at training time. The competition compiles a collection of public scene text datasets comprising of 326,385 images with 4,864,405 scene text instances, thus covering a wide range of data distributions. A new and independent validation and test set is formed with scene text instances that are out of vocabulary at training time. The competition was structured in two tasks, end-to-end and cropped scene text recognition respectively. A thorough analysis of results from baselines and different participants is presented. Interestingly, current state-of-the-art models show a significant performance gap under the newly studied setting. We conclude that the OOV dataset proposed in this challenge will be an essential area to be explored in order to develop scene text models that achieve more robust and generalized predictions.
Multimodal Semi-Supervised Learning for Text Recognition
May 08, 2022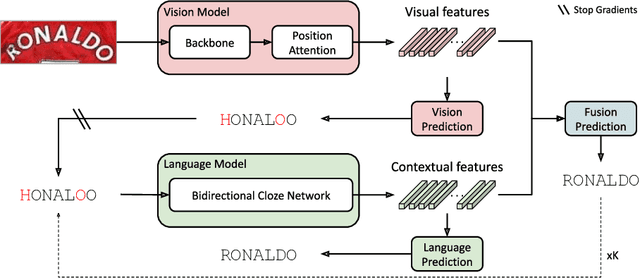
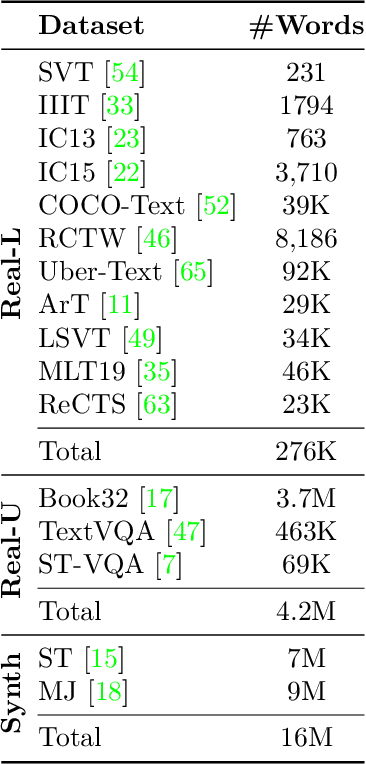
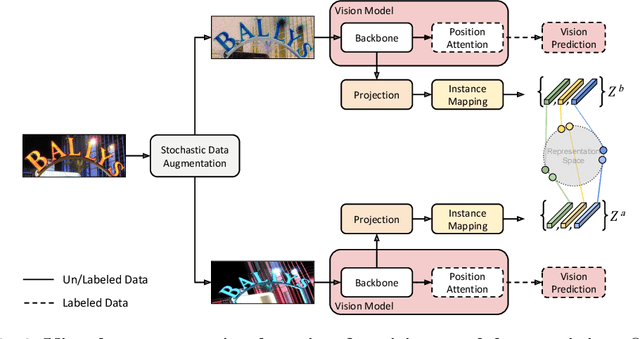
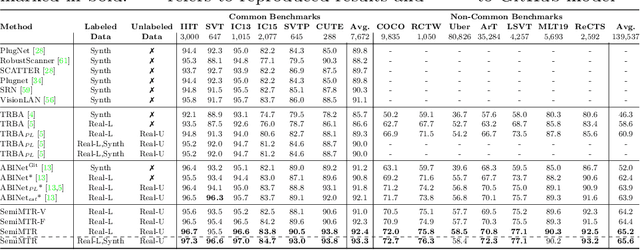
Until recently, the number of public real-world text images was insufficient for training scene text recognizers. Therefore, most modern training methods rely on synthetic data and operate in a fully supervised manner. Nevertheless, the amount of public real-world text images has increased significantly lately, including a great deal of unlabeled data. Leveraging these resources requires semi-supervised approaches; however, the few existing methods do not account for vision-language multimodality structure and therefore suboptimal for state-of-the-art multimodal architectures. To bridge this gap, we present semi-supervised learning for multimodal text recognizers (SemiMTR) that leverages unlabeled data at each modality training phase. Notably, our method refrains from extra training stages and maintains the current three-stage multimodal training procedure. Our algorithm starts by pretraining the vision model through a single-stage training that unifies self-supervised learning with supervised training. More specifically, we extend an existing visual representation learning algorithm and propose the first contrastive-based method for scene text recognition. After pretraining the language model on a text corpus, we fine-tune the entire network via a sequential, character-level, consistency regularization between weakly and strongly augmented views of text images. In a novel setup, consistency is enforced on each modality separately. Extensive experiments validate that our method outperforms the current training schemes and achieves state-of-the-art results on multiple scene text recognition benchmarks.