 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP -- Towards Structured Scene-Text Spotting
Sep 05, 2023We introduce the structured scene-text spotting task, which requires a scene-text OCR system to spot text in the wild according to a query regular expression. Contrary to generic scene text OCR, structured scene-text spotting seeks to dynamically condition both scene text detection and recognition on user-provided regular expressions. To tackle this task, we propose the Structured TExt sPotter (STEP), a model that exploits the provided text structure to guide the OCR process. STEP is able to deal with regular expressions that contain spaces and it is not bound to detection at the word-level granularity. Our approach enables accurate zero-shot structured text spotting in a wide variety of real-world reading scenarios and is solely trained on publicly available data. To demonstrate the effectiveness of our approach, we introduce a new challenging test dataset that contains several types of out-of-vocabulary structured text, reflecting important reading applications of fields such as prices, dates, serial numbers, license plates etc. We demonstrate that STEP can provide specialised OCR performance on demand in all tested scenarios.
Out-of-Vocabulary Challenge Report
Sep 14, 2022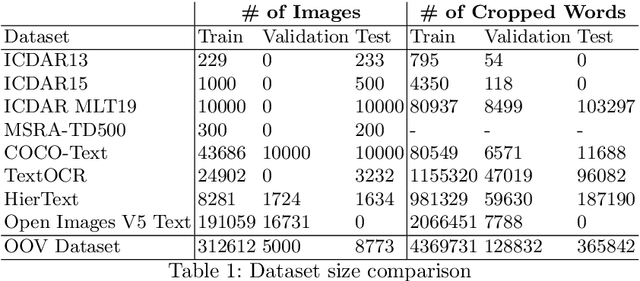
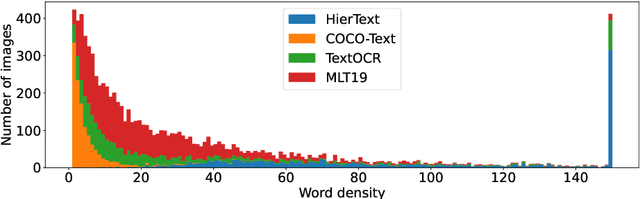

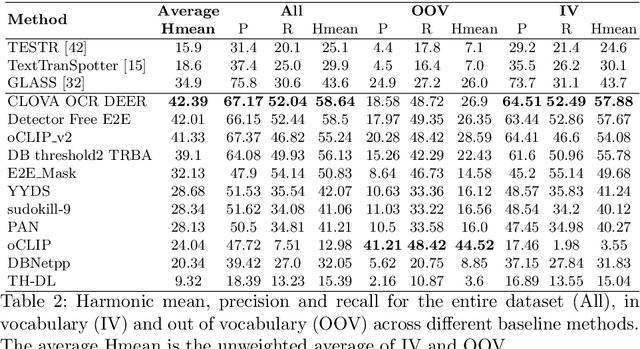
This paper presents final results of the Out-Of-Vocabulary 2022 (OOV) challenge. The OOV contest introduces an important aspect that is not commonly studied by Optical Character Recognition (OCR) models, namely, the recognition of unseen scene text instances at training time. The competition compiles a collection of public scene text datasets comprising of 326,385 images with 4,864,405 scene text instances, thus covering a wide range of data distributions. A new and independent validation and test set is formed with scene text instances that are out of vocabulary at training time. The competition was structured in two tasks, end-to-end and cropped scene text recognition respectively. A thorough analysis of results from baselines and different participants is presented. Interestingly, current state-of-the-art models show a significant performance gap under the newly studied setting. We conclude that the OOV dataset proposed in this challenge will be an essential area to be explored in order to develop scene text models that achieve more robust and generalized predictions.