 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferDoc: A Self-Supervised Transferable Document Representation Learning Model Unifying Vision and Language
Sep 11, 2023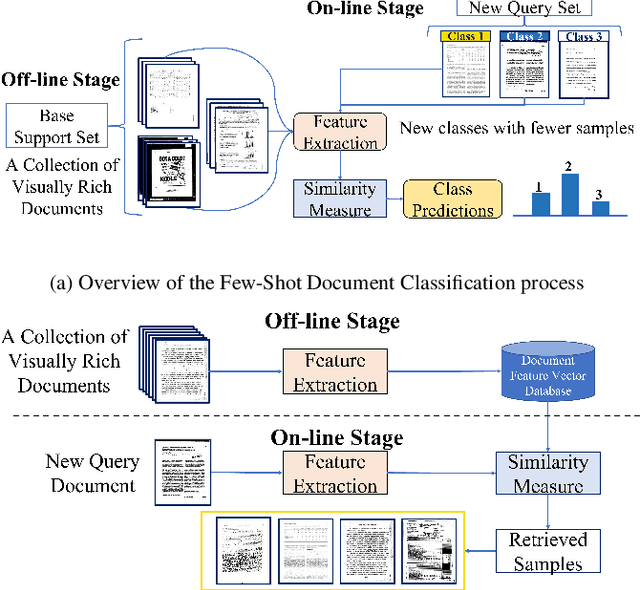
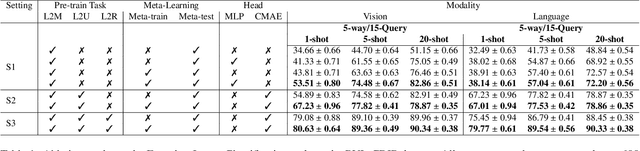
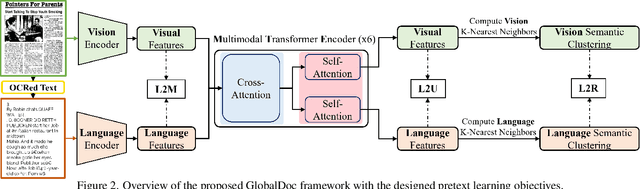

The field of visual document understanding has witnessed a rapid growth in emerging challenges and powerful multi-modal strategies. However, they rely on an extensive amount of document data to learn their pretext objectives in a ``pre-train-then-fine-tune'' paradigm and thus, suffer a significant performance drop in real-world online industrial settings. One major reason is the over-reliance on OCR engines to extract local positional information within a document page. Therefore, this hinders the model's generalizability, flexibility and robustness due to the lack of capturing global information within a document image. We introduce TransferDoc, a cross-modal transformer-based architecture pre-trained in a self-supervised fashion using three novel pretext objectives. TransferDoc learns richer semantic concepts by unifying language and visual representations, which enables the production of more transferable models. Besides, two novel downstream tasks have been introduced for a ``closer-to-real'' industrial evaluation scenario where TransferDoc outperforms other state-of-the-art approaches.
STEP -- Towards Structured Scene-Text Spotting
Sep 05, 2023
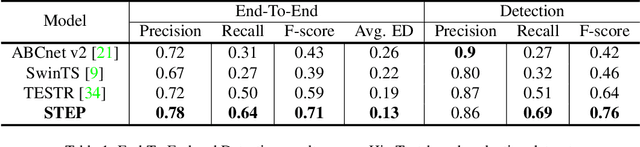
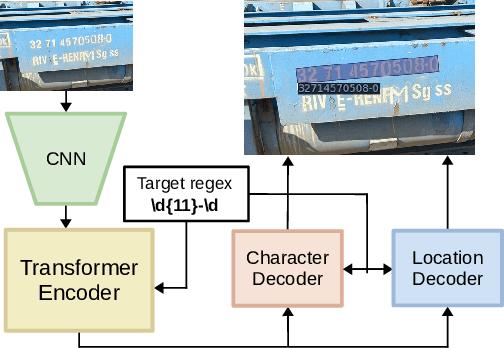
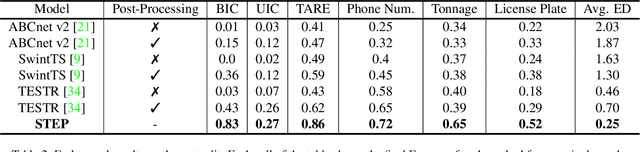
We introduce the structured scene-text spotting task, which requires a scene-text OCR system to spot text in the wild according to a query regular expression. Contrary to generic scene text OCR, structured scene-text spotting seeks to dynamically condition both scene text detection and recognition on user-provided regular expressions. To tackle this task, we propose the Structured TExt sPotter (STEP), a model that exploits the provided text structure to guide the OCR process. STEP is able to deal with regular expressions that contain spaces and it is not bound to detection at the word-level granularity. Our approach enables accurate zero-shot structured text spotting in a wide variety of real-world reading scenarios and is solely trained on publicly available data. To demonstrate the effectiveness of our approach, we introduce a new challenging test dataset that contains several types of out-of-vocabulary structured text, reflecting important reading applications of fields such as prices, dates, serial numbers, license plates etc. We demonstrate that STEP can provide specialised OCR performance on demand in all tested scenarios.
EAML: Ensemble Self-Attention-based Mutual Learning Network for Document Image Classification
May 11, 2023In the recent past, complex deep neural networks have received huge interest in various document understanding tasks such as document image classification and document retrieval. As many document types have a distinct visual style, learning only visual features with deep CNNs to classify document images have encountered the problem of low inter-class discrimination, and high intra-class structural variations between its categories. In parallel, text-level understanding jointly learned with the corresponding visual properties within a given document image has considerably improved the classification performance in terms of accuracy. In this paper, we design a self-attention-based fusion module that serves as a block in our ensemble trainable network. It allows to simultaneously learn the discriminant features of image and text modalities throughout the training stage. Besides, we encourage mutual learning by transferring the positive knowledge between image and text modalities during the training stage. This constraint is realized by adding a truncated-Kullback-Leibler divergence loss Tr-KLD-Reg as a new regularization term, to the conventional supervised setting. To the best of our knowledge, this is the first time to leverage a mutual learning approach along with a self-attention-based fusion module to perform document image classification. The experimental results illustrate the effectiveness of our approach in terms of accuracy for the single-modal and multi-modal modalities. Thus, the proposed ensemble self-attention-based mutual learning model outperforms the state-of-the-art classification results based on the benchmark RVL-CDIP and Tobacco-3482 datasets.
VLCDoC: Vision-Language Contrastive Pre-Training Model for Cross-Modal Document Classification
May 24, 2022
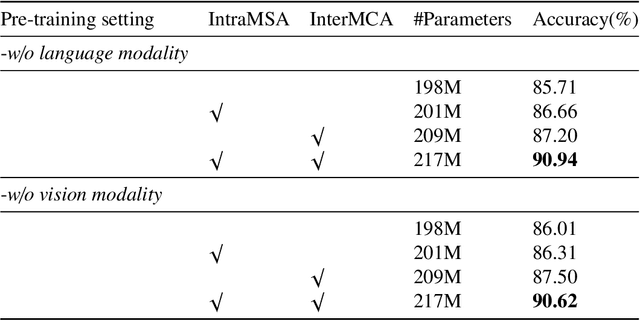
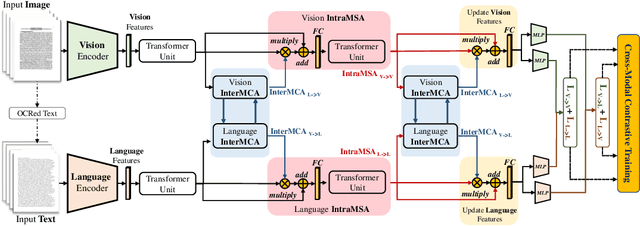
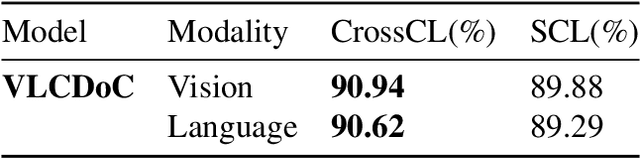
Multimodal learning from document data has achieved great success lately as it allows to pre-train semantically meaningful features as a prior into a learnable downstream approach. In this paper, we approach the document classification problem by learning cross-modal representations through language and vision cues, considering intra- and inter-modality relationships. Instead of merging features from different modalities into a common representation space, the proposed method exploits high-level interactions and learns relevant semantic information from effective attention flows within and across modalities. The proposed learning objective is devised between intra- and inter-modality alignment tasks, where the similarity distribution per task is computed by contracting positive sample pairs while simultaneously contrasting negative ones in the common feature representation space}. Extensive experiments on public document classification datasets demonstrate the effectiveness and the generalization capacity of our model on both low-scale and large-scale datasets.
Content and Style Aware Generation of Text-line Images for Handwriting Recognition
Apr 12, 2022

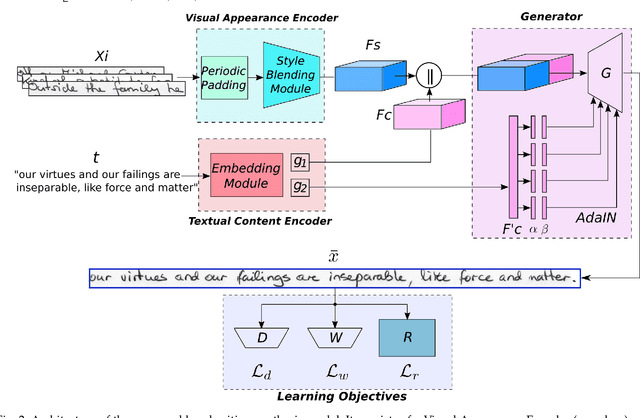
Handwritten Text Recognition has achieved an impressive performance in public benchmarks. However, due to the high inter- and intra-class variability between handwriting styles, such recognizers need to be trained using huge volumes of manually labeled training data. To alleviate this labor-consuming problem, synthetic data produced with TrueType fonts has been often used in the training loop to gain volume and augment the handwriting style variability. However, there is a significant style bias between synthetic and real data which hinders the improvement of recognition performance. To deal with such limitations, we propose a generative method for handwritten text-line images, which is conditioned on both visual appearance and textual content. Our method is able to produce long text-line samples with diverse handwriting styles. Once properly trained, our method can also be adapted to new target data by only accessing unlabeled text-line images to mimic handwritten styles and produce images with any textual content. Extensive experiments have been done on making use of the generated samples to boost Handwritten Text Recognition performance. Both qualitative and quantitative results demonstrate that the proposed approach outperforms the current state of the art.
Multimodal grid features and cell pointers for Scene Text Visual Question Answering
Jun 25, 2020
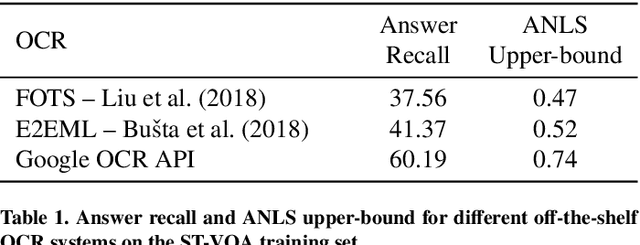
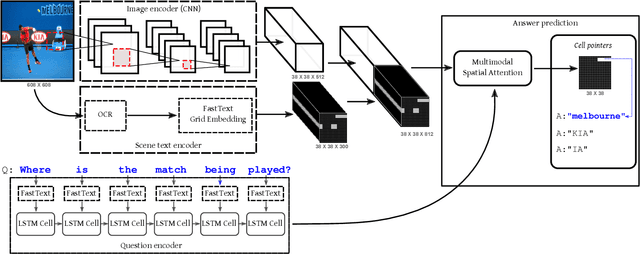
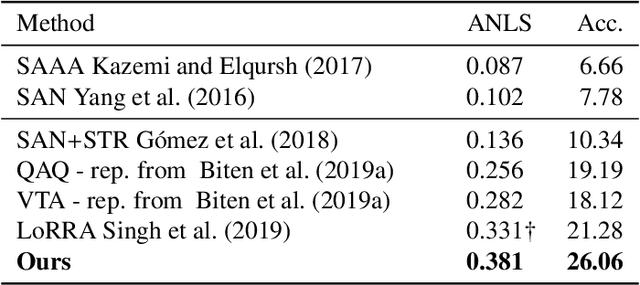
This paper presents a new model for the task of scene text visual question answering, in which questions about a given image can only be answered by reading and understanding scene text that is present in it. The proposed model is based on an attention mechanism that attends to multi-modal features conditioned to the question, allowing it to reason jointly about the textual and visual modalities in the scene. The output weights of this attention module over the grid of multi-modal spatial features are interpreted as the probability that a certain spatial location of the image contains the answer text the to the given question. Our experiments demonstrate competitive performance in two standard datasets. Furthermore, this paper provides a novel analysis of the ST-VQA dataset based on a human performance study.
Pay Attention to What You Read: Non-recurrent Handwritten Text-Line Recognition
May 26, 2020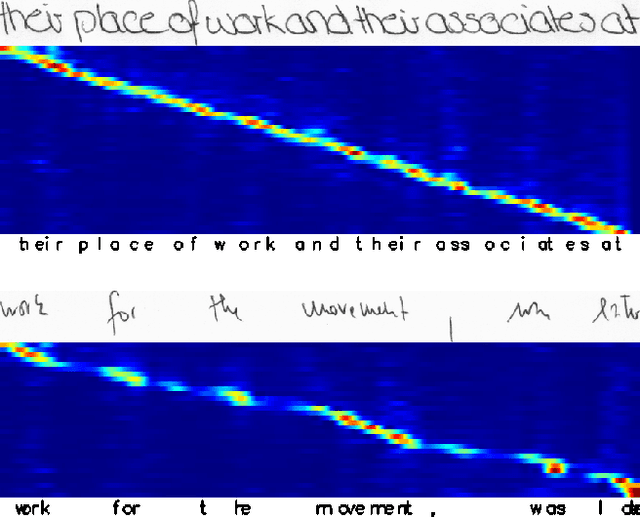
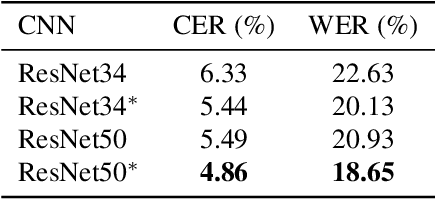
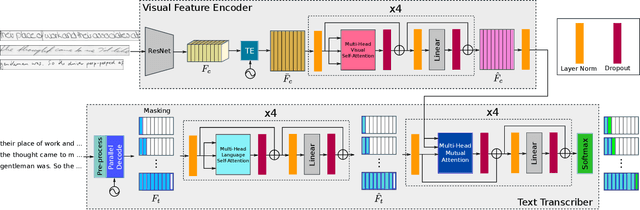

The advent of recurrent neural networks for handwriting recognition marked an important milestone reaching impressive recognition accuracies despite the great variability that we observe across different writing styles. Sequential architectures are a perfect fit to model text lines, not only because of the inherent temporal aspect of text, but also to learn probability distributions over sequences of characters and words. However, using such recurrent paradigms comes at a cost at training stage, since their sequential pipelines prevent parallelization. In this work, we introduce a non-recurrent approach to recognize handwritten text by the use of transformer models. We propose a novel method that bypasses any recurrence. By using multi-head self-attention layers both at the visual and textual stages, we are able to tackle character recognition as well as to learn language-related dependencies of the character sequences to be decoded. Our model is unconstrained to any predefined vocabulary, being able to recognize out-of-vocabulary words, i.e. words that do not appear in the training vocabulary. We significantly advance over prior art and demonstrate that satisfactory recognition accuracies are yielded even in few-shot learning scenarios.
GANwriting: Content-Conditioned Generation of Styled Handwritten Word Images
Mar 05, 2020

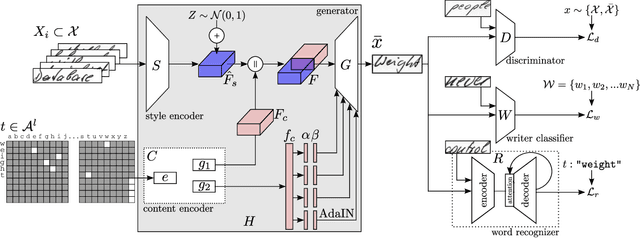

Although current image generation methods have reached impressive quality levels, they are still unable to produce plausible yet diverse images of handwritten words. On the contrary, when writing by hand, a great variability is observed across different writers, and even when analyzing words scribbled by the same individual, involuntary variations are conspicuous. In this work, we take a step closer to producing realistic and varied artificially rendered handwritten words. We propose a novel method that is able to produce credible handwritten word images by conditioning the generative process with both calligraphic style features and textual content. Our generator is guided by three complementary learning objectives: to produce realistic images, to imitate a certain handwriting style and to convey a specific textual content. Our model is unconstrained to any predefined vocabulary, being able to render whatever input word. Given a sample writer, it is also able to mimic its calligraphic features in a few-shot setup. We significantly advance over prior art and demonstrate with qualitative, quantitative and human-based evaluations the realistic aspect of our synthetically produced images.
Candidate Fusion: Integrating Language Modelling into a Sequence-to-Sequence Handwritten Word Recognition Architecture
Dec 21, 2019

Sequence-to-sequence models have recently become very popular for tackling handwritten word recognition problems. However, how to effectively integrate an external language model into such recognizer is still a challenging problem. The main challenge faced when training a language model is to deal with the language model corpus which is usually different to the one used for training the handwritten word recognition system. Thus, the bias between both word corpora leads to incorrectness on the transcriptions, providing similar or even worse performances on the recognition task. In this work, we introduce Candidate Fusion, a novel way to integrate an external language model to a sequence-to-sequence architecture. Moreover, it provides suggestions from an external language knowledge, as a new input to the sequence-to-sequence recognizer. Hence, Candidate Fusion provides two improvements. On the one hand, the sequence-to-sequence recognizer has the flexibility not only to combine the information from itself and the language model, but also to choose the importance of the information provided by the language model. On the other hand, the external language model has the ability to adapt itself to the training corpus and even learn the most commonly errors produced from the recognizer. Finally, by conducting comprehensive experiments, the Candidate Fusion proves to outperform the state-of-the-art language models for handwritten word recognition tasks.
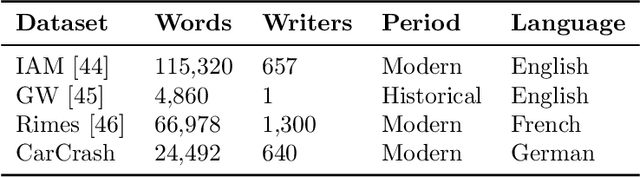
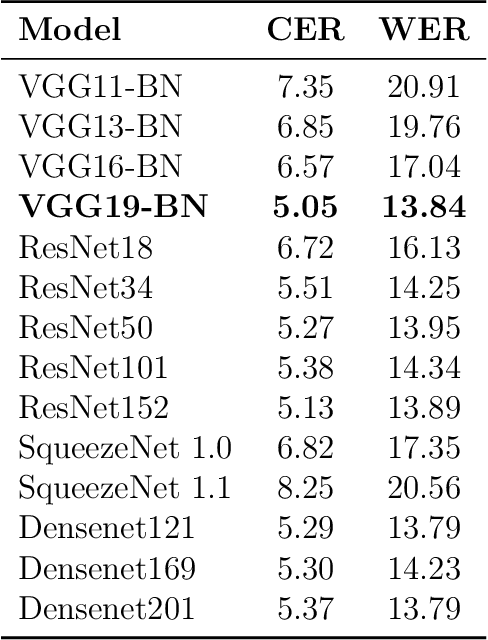
Unsupervised Writer Adaptation for Synthetic-to-Real Handwritten Word Recognition
Sep 18, 2019
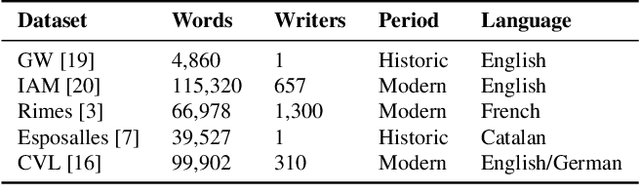
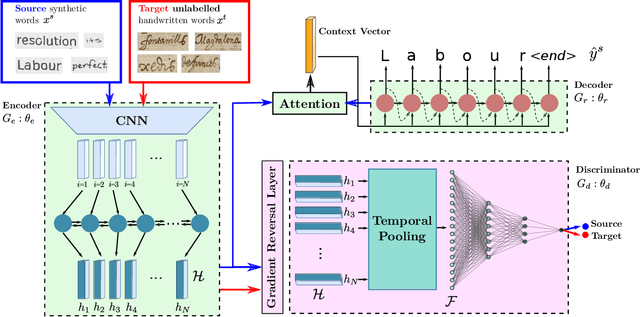
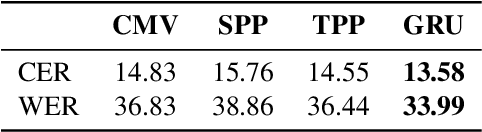
Handwritten Text Recognition (HTR) is still a challenging problem because it must deal with two important difficulties: the variability among writing styles, and the scarcity of labelled data. To alleviate such problems, synthetic data generation and data augmentation are typically used to train HTR systems. However, training with such data produces encouraging but still inaccurate transcriptions in real words. In this paper, we propose an unsupervised writer adaptation approach that is able to automatically adjust a generic handwritten word recognizer, fully trained with synthetic fonts, towards a new incoming writer. We have experimentally validated our proposal using five different datasets, covering several challenges (i) the document source: modern and historic samples, which may involve paper degradation problems; (ii) different handwriting styles: single and multiple writer collections; and (iii) language, which involves different character combinations. Across these challenging collections, we show that our system is able to maintain its performance, thus, it provides a practical and generic approach to deal with new document collections without requiring any expensive and tedious manual annotation step.