 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Writer Adaptation for Synthetic-to-Real Handwritten Word Recognition
Paper and Code
Sep 18, 2019
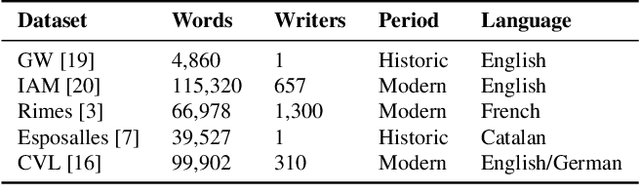
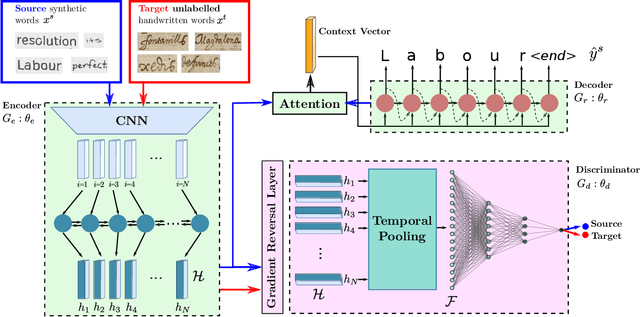
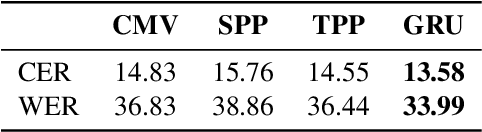
Handwritten Text Recognition (HTR) is still a challenging problem because it must deal with two important difficulties: the variability among writing styles, and the scarcity of labelled data. To alleviate such problems, synthetic data generation and data augmentation are typically used to train HTR systems. However, training with such data produces encouraging but still inaccurate transcriptions in real words. In this paper, we propose an unsupervised writer adaptation approach that is able to automatically adjust a generic handwritten word recognizer, fully trained with synthetic fonts, towards a new incoming writer. We have experimentally validated our proposal using five different datasets, covering several challenges (i) the document source: modern and historic samples, which may involve paper degradation problems; (ii) different handwriting styles: single and multiple writer collections; and (iii) language, which involves different character combinations. Across these challenging collections, we show that our system is able to maintain its performance, thus, it provides a practical and generic approach to deal with new document collections without requiring any expensive and tedious manual annotation step.