 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVIR: Adaptive Visual In-Document Retrieval for Efficient Multi-Page Document Question Answering
Jan 17, 2026Multi-page Document Visual Question Answering (MP-DocVQA) remains challenging because long documents not only strain computational resources but also reduce the effectiveness of the attention mechanism in large vision-language models (LVLMs). We tackle these issues with an Adaptive Visual In-document Retrieval (AVIR) framework. A lightweight retrieval model first scores each page for question relevance. Pages are then clustered according to the score distribution to adaptively select relevant content. The clustered pages are screened again by Top-K to keep the context compact. However, for short documents, clustering reliability decreases, so we use a relevance probability threshold to select pages. The selected pages alone are fed to a frozen LVLM for answer generation, eliminating the need for model fine-tuning. The proposed AVIR framework reduces the average page count required for question answering by 70%, while achieving an ANLS of 84.58% on the MP-DocVQA dataset-surpassing previous methods with significantly lower computational cost. The effectiveness of the proposed AVIR is also verified on the SlideVQA and DUDE benchmarks. The code is available at https://github.com/Li-yachuan/AVIR.
LLM-Driven Medical Document Analysis: Enhancing Trustworthy Pathology and Differential Diagnosis
Jun 24, 2025Medical document analysis plays a crucial role in extracting essential clinical insights from unstructured healthcare records, supporting critical tasks such as differential diagnosis. Determining the most probable condition among overlapping symptoms requires precise evaluation and deep medical expertise. While recent advancements in large language models (LLMs) have significantly enhanced performance in medical document analysis, privacy concerns related to sensitive patient data limit the use of online LLMs services in clinical settings. To address these challenges, we propose a trustworthy medical document analysis platform that fine-tunes a LLaMA-v3 using low-rank adaptation, specifically optimized for differential diagnosis tasks. Our approach utilizes DDXPlus, the largest benchmark dataset for differential diagnosis, and demonstrates superior performance in pathology prediction and variable-length differential diagnosis compared to existing methods. The developed web-based platform allows users to submit their own unstructured medical documents and receive accurate, explainable diagnostic results. By incorporating advanced explainability techniques, the system ensures transparent and reliable predictions, fostering user trust and confidence. Extensive evaluations confirm that the proposed method surpasses current state-of-the-art models in predictive accuracy while offering practical utility in clinical settings. This work addresses the urgent need for reliable, explainable, and privacy-preserving artificial intelligence solutions, representing a significant advancement in intelligent medical document analysis for real-world healthcare applications. The code can be found at \href{https://github.com/leitro/Differential-Diagnosis-LoRA}{https://github.com/leitro/Differential-Diagnosis-LoRA}.
xLSTM-ECG: Multi-label ECG Classification via Feature Fusion with xLSTM
Apr 14, 2025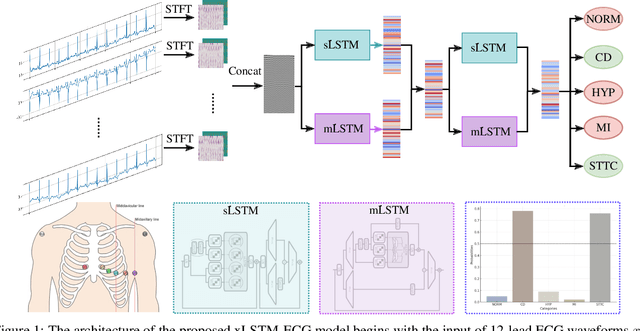
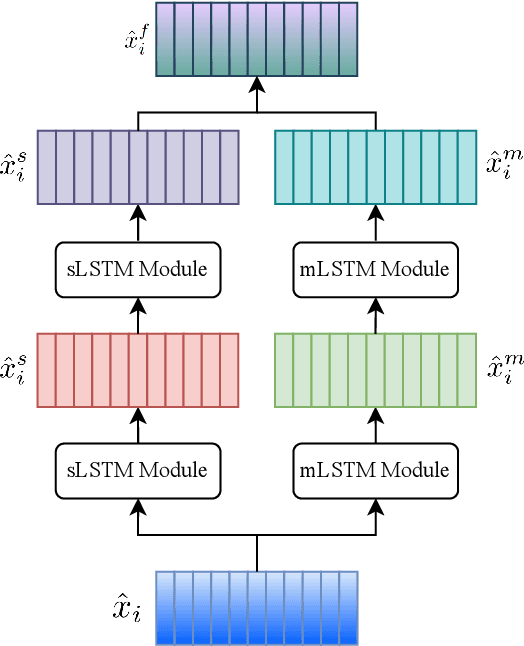

Cardiovascular diseases (CVDs) remain the leading cause of mortality worldwide, highlighting the critical need for efficient and accurate diagnostic tools. Electrocardiograms (ECGs) are indispensable in diagnosing various heart conditions; however, their manual interpretation is time-consuming and error-prone. In this paper, we propose xLSTM-ECG, a novel approach that leverages an extended Long Short-Term Memory (xLSTM) network for multi-label classification of ECG signals, using the PTB-XL dataset. To the best of our knowledge, this work represents the first design and application of xLSTM modules specifically adapted for multi-label ECG classification. Our method employs a Short-Time Fourier Transform (STFT) to convert time-series ECG waveforms into the frequency domain, thereby enhancing feature extraction. The xLSTM architecture is specifically tailored to address the complexities of 12-lead ECG recordings by capturing both local and global signal features. Comprehensive experiments on the PTB-XL dataset reveal that our model achieves strong multi-label classification performance, while additional tests on the Georgia 12-Lead dataset underscore its robustness and efficiency. This approach significantly improves ECG classification accuracy, thereby advancing clinical diagnostics and patient care. The code will be publicly available upon acceptance.
Mixture of Group Experts for Learning Invariant Representations
Apr 12, 2025Sparsely activated Mixture-of-Experts (MoE) models effectively increase the number of parameters while maintaining consistent computational costs per token. However, vanilla MoE models often suffer from limited diversity and specialization among experts, constraining their performance and scalability, especially as the number of experts increases. In this paper, we present a novel perspective on vanilla MoE with top-$k$ routing inspired by sparse representation. This allows us to bridge established theoretical insights from sparse representation into MoE models. Building on this foundation, we propose a group sparse regularization approach for the input of top-$k$ routing, termed Mixture of Group Experts (MoGE). MoGE indirectly regularizes experts by imposing structural constraints on the routing inputs, while preserving the original MoE architecture. Furthermore, we organize the routing input into a 2D topographic map, spatially grouping neighboring elements. This structure enables MoGE to capture representations invariant to minor transformations, thereby significantly enhancing expert diversity and specialization. Comprehensive evaluations across various Transformer models for image classification and language modeling tasks demonstrate that MoGE substantially outperforms its MoE counterpart, with minimal additional memory and computation overhead. Our approach provides a simple yet effective solution to scale the number of experts and reduce redundancy among them. The source code is included in the supplementary material and will be publicly released.
Preserving Privacy Without Compromising Accuracy: Machine Unlearning for Handwritten Text Recognition
Apr 11, 2025



Handwritten Text Recognition (HTR) is essential for document analysis and digitization. However, handwritten data often contains user-identifiable information, such as unique handwriting styles and personal lexicon choices, which can compromise privacy and erode trust in AI services. Legislation like the ``right to be forgotten'' underscores the necessity for methods that can expunge sensitive information from trained models. Machine unlearning addresses this by selectively removing specific data from models without necessitating complete retraining. Yet, it frequently encounters a privacy-accuracy tradeoff, where safeguarding privacy leads to diminished model performance. In this paper, we introduce a novel two-stage unlearning strategy for a multi-head transformer-based HTR model, integrating pruning and random labeling. Our proposed method utilizes a writer classification head both as an indicator and a trigger for unlearning, while maintaining the efficacy of the recognition head. To our knowledge, this represents the first comprehensive exploration of machine unlearning within HTR tasks. We further employ Membership Inference Attacks (MIA) to evaluate the effectiveness of unlearning user-identifiable information. Extensive experiments demonstrate that our approach effectively preserves privacy while maintaining model accuracy, paving the way for new research directions in the document analysis community. Our code will be publicly available upon acceptance.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
GRIF-DM: Generation of Rich Impression Fonts using Diffusion Models
Aug 14, 2024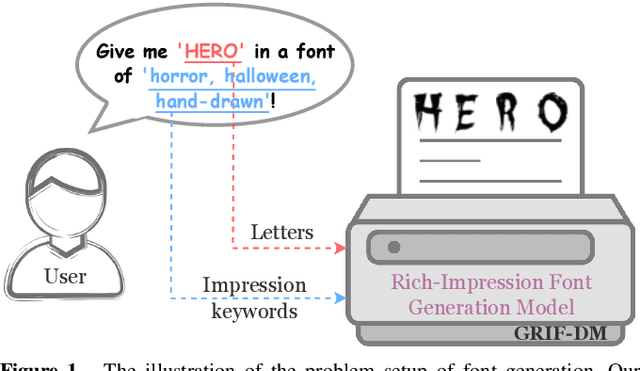
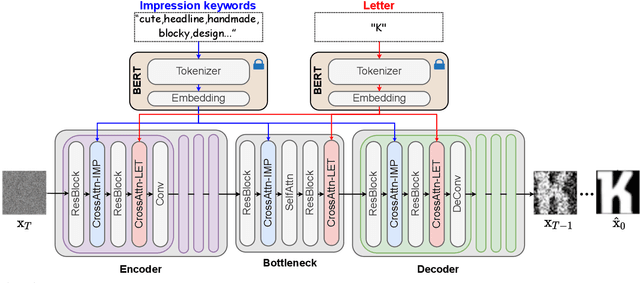


Fonts are integral to creative endeavors, design processes, and artistic productions. The appropriate selection of a font can significantly enhance artwork and endow advertisements with a higher level of expressivity. Despite the availability of numerous diverse font designs online, traditional retrieval-based methods for font selection are increasingly being supplanted by generation-based approaches. These newer methods offer enhanced flexibility, catering to specific user preferences and capturing unique stylistic impressions. However, current impression font techniques based on Generative Adversarial Networks (GANs) necessitate the utilization of multiple auxiliary losses to provide guidance during generation. Furthermore, these methods commonly employ weighted summation for the fusion of impression-related keywords. This leads to generic vectors with the addition of more impression keywords, ultimately lacking in detail generation capacity. In this paper, we introduce a diffusion-based method, termed \ourmethod, to generate fonts that vividly embody specific impressions, utilizing an input consisting of a single letter and a set of descriptive impression keywords. The core innovation of \ourmethod lies in the development of dual cross-attention modules, which process the characteristics of the letters and impression keywords independently but synergistically, ensuring effective integration of both types of information. Our experimental results, conducted on the MyFonts dataset, affirm that this method is capable of producing realistic, vibrant, and high-fidelity fonts that are closely aligned with user specifications. This confirms the potential of our approach to revolutionize font generation by accommodating a broad spectrum of user-driven design requirements. Our code is publicly available at \url{https://github.com/leitro/GRIF-DM}.
Machine Unlearning for Document Classification
Apr 29, 2024



Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten" has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at \url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Multi-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
Apr 29, 2024

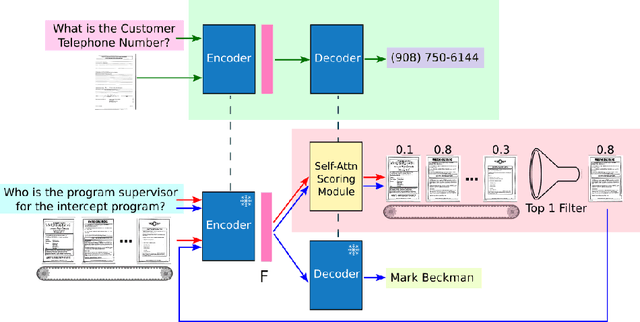
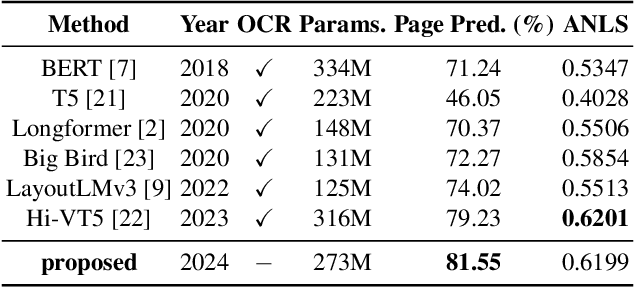
Documents are 2-dimensional carriers of written communication, and as such their interpretation requires a multi-modal approach where textual and visual information are efficiently combined. Document Visual Question Answering (Document VQA), due to this multi-modal nature, has garnered significant interest from both the document understanding and natural language processing communities. The state-of-the-art single-page Document VQA methods show impressive performance, yet in multi-page scenarios, these methods struggle. They have to concatenate all pages into one large page for processing, demanding substantial GPU resources, even for evaluation. In this work, we propose a novel method and efficient training strategy for multi-page Document VQA tasks. In particular, we employ a visual-only document representation, leveraging the encoder from a document understanding model, Pix2Struct. Our approach utilizes a self-attention scoring mechanism to generate relevance scores for each document page, enabling the retrieval of pertinent pages. This adaptation allows us to extend single-page Document VQA models to multi-page scenarios without constraints on the number of pages during evaluation, all with minimal demand for GPU resources. Our extensive experiments demonstrate not only achieving state-of-the-art performance without the need for Optical Character Recognition (OCR), but also sustained performance in scenarios extending to documents of nearly 800 pages compared to a maximum of 20 pages in the MP-DocVQA dataset. Our code is publicly available at \url{https://github.com/leitro/SelfAttnScoring-MPDocVQA}.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023

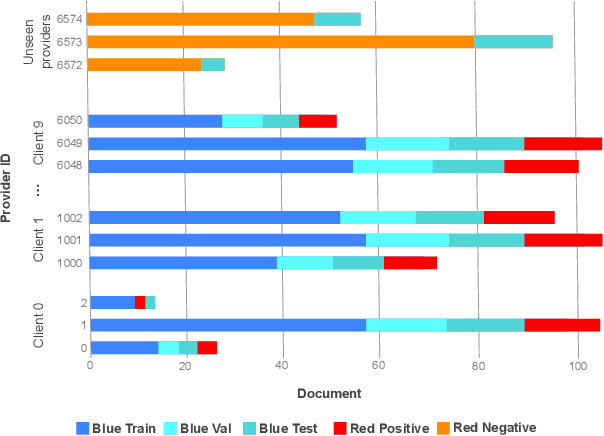

Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.