 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
Paper and Code


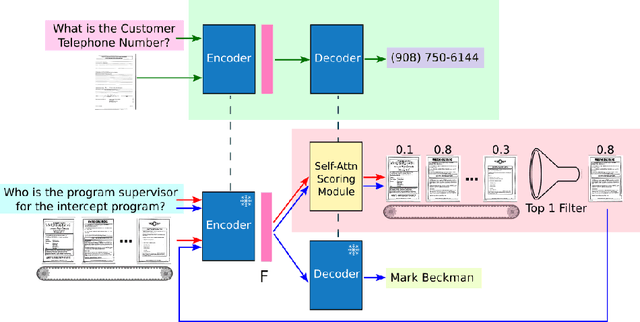
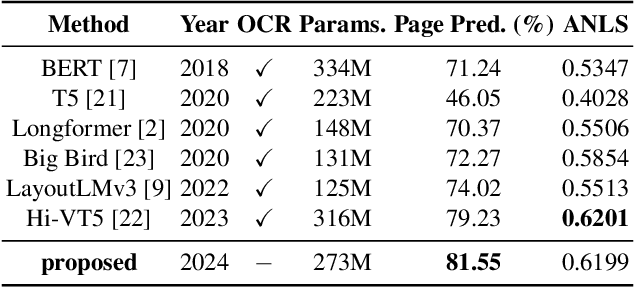
Documents are 2-dimensional carriers of written communication, and as such their interpretation requires a multi-modal approach where textual and visual information are efficiently combined. Document Visual Question Answering (Document VQA), due to this multi-modal nature, has garnered significant interest from both the document understanding and natural language processing communities. The state-of-the-art single-page Document VQA methods show impressive performance, yet in multi-page scenarios, these methods struggle. They have to concatenate all pages into one large page for processing, demanding substantial GPU resources, even for evaluation. In this work, we propose a novel method and efficient training strategy for multi-page Document VQA tasks. In particular, we employ a visual-only document representation, leveraging the encoder from a document understanding model, Pix2Struct. Our approach utilizes a self-attention scoring mechanism to generate relevance scores for each document page, enabling the retrieval of pertinent pages. This adaptation allows us to extend single-page Document VQA models to multi-page scenarios without constraints on the number of pages during evaluation, all with minimal demand for GPU resources. Our extensive experiments demonstrate not only achieving state-of-the-art performance without the need for Optical Character Recognition (OCR), but also sustained performance in scenarios extending to documents of nearly 800 pages compared to a maximum of 20 pages in the MP-DocVQA dataset. Our code is publicly available at \url{https://github.com/leitro/SelfAttnScoring-MPDocVQA}.