 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Aware Document Visual Question Answering
Paper and Code
Dec 15, 2023

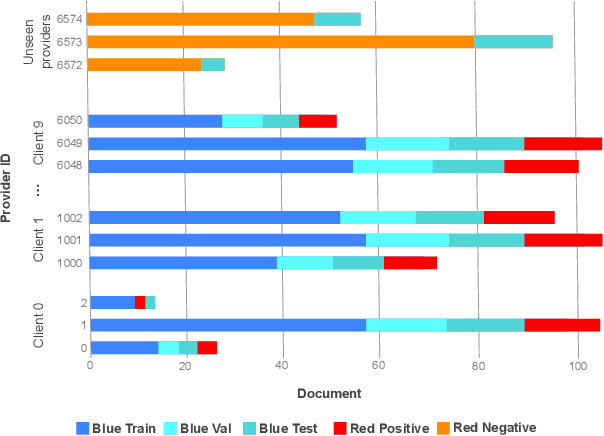

Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.