 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocVXQA: Context-Aware Visual Explanations for Document Question Answering
May 12, 2025We propose DocVXQA, a novel framework for visually self-explainable document question answering. The framework is designed not only to produce accurate answers to questions but also to learn visual heatmaps that highlight contextually critical regions, thereby offering interpretable justifications for the model's decisions. To integrate explanations into the learning process, we quantitatively formulate explainability principles as explicit learning objectives. Unlike conventional methods that emphasize only the regions pertinent to the answer, our framework delivers explanations that are \textit{contextually sufficient} while remaining \textit{representation-efficient}. This fosters user trust while achieving a balance between predictive performance and interpretability in DocVQA applications. Extensive experiments, including human evaluation, provide strong evidence supporting the effectiveness of our method. The code is available at https://github.com/dali92002/DocVXQA.
Mitigating Membership Inference Vulnerability in Personalized Federated Learning
Mar 12, 2025Federated Learning (FL) has emerged as a promising paradigm for collaborative model training without the need to share clients' personal data, thereby preserving privacy. However, the non-IID nature of the clients' data introduces major challenges for FL, highlighting the importance of personalized federated learning (PFL) methods. In PFL, models are trained to cater to specific feature distributions present in the population data. A notable method for PFL is the Iterative Federated Clustering Algorithm (IFCA), which mitigates the concerns associated with the non-IID-ness by grouping clients with similar data distributions. While it has been shown that IFCA enhances both accuracy and fairness, its strategy of dividing the population into smaller clusters increases vulnerability to Membership Inference Attacks (MIA), particularly among minorities with limited training samples. In this paper, we introduce IFCA-MIR, an improved version of IFCA that integrates MIA risk assessment into the clustering process. Allowing clients to select clusters based on both model performance and MIA vulnerability, IFCA-MIR achieves an improved performance with respect to accuracy, fairness, and privacy. We demonstrate that IFCA-MIR significantly reduces MIA risk while maintaining comparable model accuracy and fairness as the original IFCA.
Metric Privacy in Federated Learning for Medical Imaging: Improving Convergence and Preventing Client Inference Attacks
Feb 03, 2025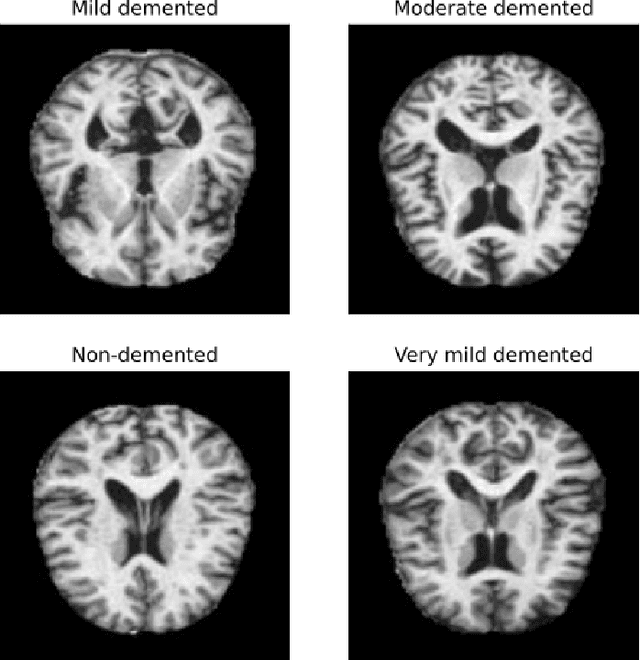
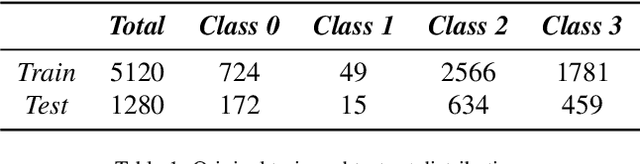
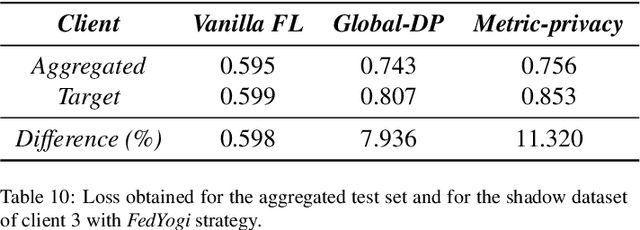
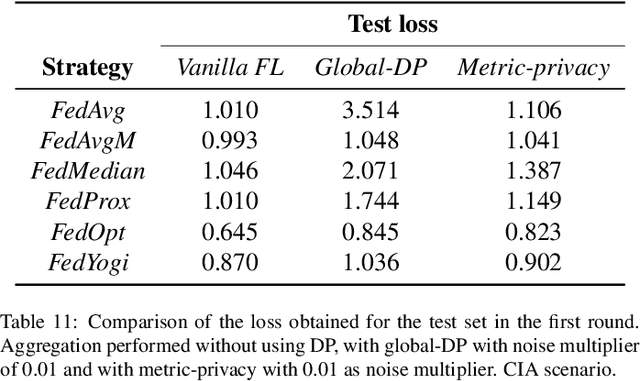
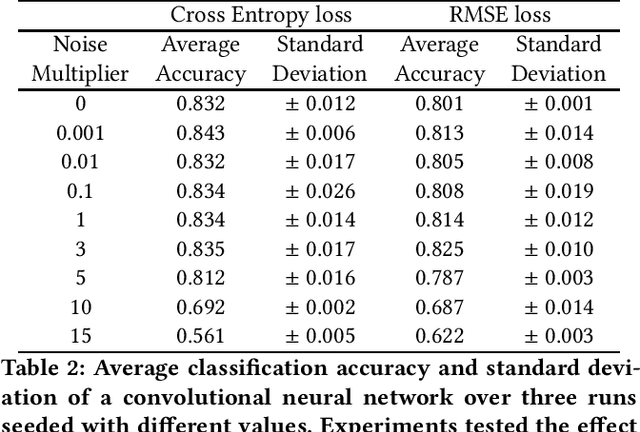
Federated learning is a distributed learning technique that allows training a global model with the participation of different data owners without the need to share raw data. This architecture is orchestrated by a central server that aggregates the local models from the clients. This server may be trusted, but not all nodes in the network. Then, differential privacy (DP) can be used to privatize the global model by adding noise. However, this may affect convergence across the rounds of the federated architecture, depending also on the aggregation strategy employed. In this work, we aim to introduce the notion of metric-privacy to mitigate the impact of classical server side global-DP on the convergence of the aggregated model. Metric-privacy is a relaxation of DP, suitable for domains provided with a notion of distance. We apply it from the server side by computing a distance for the difference between the local models. We compare our approach with standard DP by analyzing the impact on six classical aggregation strategies. The proposed methodology is applied to an example of medical imaging and different scenarios are simulated across homogeneous and non-i.i.d clients. Finally, we introduce a novel client inference attack, where a semi-honest client tries to find whether another client participated in the training and study how it can be mitigated using DP and metric-privacy. Our evaluation shows that metric-privacy can increase the performance of the model compared to standard DP, while offering similar protection against client inference attacks.
NeurIPS 2023 Competition: Privacy Preserving Federated Learning Document VQA
Nov 06, 2024



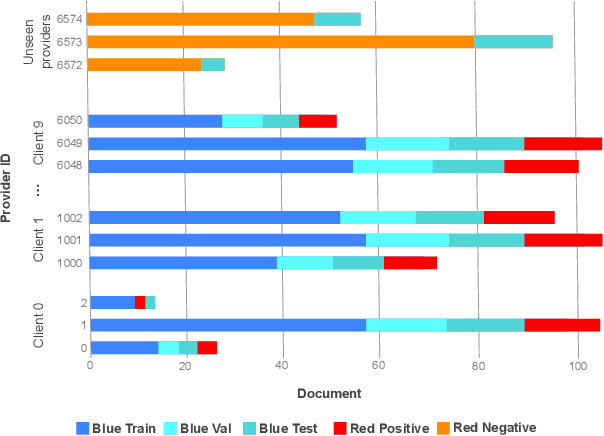
The Privacy Preserving Federated Learning Document VQA (PFL-DocVQA) competition challenged the community to develop provably private and communication-efficient solutions in a federated setting for a real-life use case: invoice processing. The competition introduced a dataset of real invoice documents, along with associated questions and answers requiring information extraction and reasoning over the document images. Thereby, it brings together researchers and expertise from the document analysis, privacy, and federated learning communities. Participants fine-tuned a pre-trained, state-of-the-art Document Visual Question Answering model provided by the organizers for this new domain, mimicking a typical federated invoice processing setup. The base model is a multi-modal generative language model, and sensitive information could be exposed through either the visual or textual input modality. Participants proposed elegant solutions to reduce communication costs while maintaining a minimum utility threshold in track 1 and to protect all information from each document provider using differential privacy in track 2. The competition served as a new testbed for developing and testing private federated learning methods, simultaneously raising awareness about privacy within the document image analysis and recognition community. Ultimately, the competition analysis provides best practices and recommendations for successfully running privacy-focused federated learning challenges in the future.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023


Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
Causal Discovery Under Local Privacy
Nov 15, 2023Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
Advancing Personalized Federated Learning: Group Privacy, Fairness, and Beyond
Sep 01, 2023Federated learning (FL) is a framework for training machine learning models in a distributed and collaborative manner. During training, a set of participating clients process their data stored locally, sharing only the model updates obtained by minimizing a cost function over their local inputs. FL was proposed as a stepping-stone towards privacy-preserving machine learning, but it has been shown vulnerable to issues such as leakage of private information, lack of personalization of the model, and the possibility of having a trained model that is fairer to some groups than to others. In this paper, we address the triadic interaction among personalization, privacy guarantees, and fairness attained by models trained within the FL framework. Differential privacy and its variants have been studied and applied as cutting-edge standards for providing formal privacy guarantees. However, clients in FL often hold very diverse datasets representing heterogeneous communities, making it important to protect their sensitive information while still ensuring that the trained model upholds the aspect of fairness for the users. To attain this objective, a method is put forth that introduces group privacy assurances through the utilization of $d$-privacy (aka metric privacy). $d$-privacy represents a localized form of differential privacy that relies on a metric-oriented obfuscation approach to maintain the original data's topological distribution. This method, besides enabling personalized model training in a federated approach and providing formal privacy guarantees, possesses significantly better group fairness measured under a variety of standard metrics than a global model trained within a classical FL template. Theoretical justifications for the applicability are provided, as well as experimental validation on real-world datasets to illustrate the working of the proposed method.
Group privacy for personalized federated learning
Jun 07, 2022
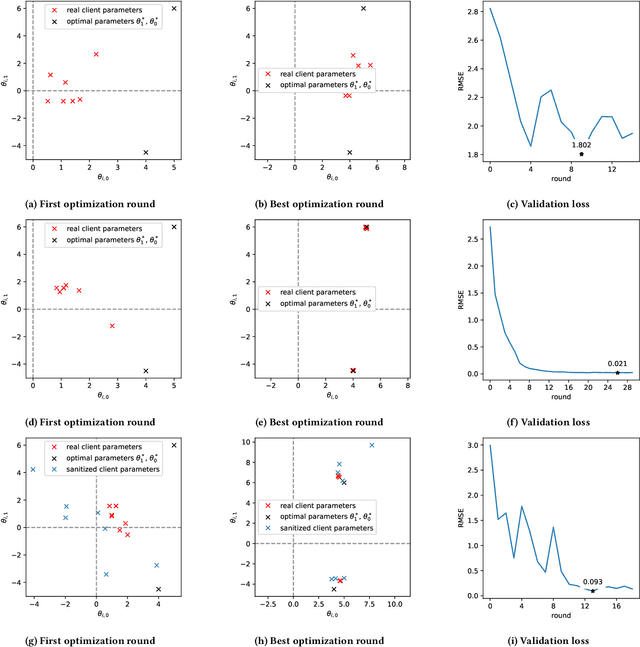

Federated learning is a type of collaborative machine learning, where participating clients process their data locally, sharing only updates to the collaborative model. This enables to build privacy-aware distributed machine learning models, among others. The goal is the optimization of a statistical model's parameters by minimizing a cost function of a collection of datasets which are stored locally by a set of clients. This process exposes the clients to two issues: leakage of private information and lack of personalization of the model. On the other hand, with the recent advancements in techniques to analyze data, there is a surge of concern for the privacy violation of the participating clients. To mitigate this, differential privacy and its variants serve as a standard for providing formal privacy guarantees. Often the clients represent very heterogeneous communities and hold data which are very diverse. Therefore, aligned with the recent focus of the FL community to build a framework of personalized models for the users representing their diversity, it is also of utmost importance to protect against potential threats against the sensitive and personal information of the clients. $d$-privacy, which is a generalization of geo-indistinguishability, the lately popularized paradigm of location privacy, uses a metric-based obfuscation technique that preserves the spatial distribution of the original data. To address the issue of protecting the privacy of the clients and allowing for personalized model training to enhance the fairness and utility of the system, we propose a method to provide group privacy guarantees exploiting some key properties of $d$-privacy which enables personalized models under the framework of FL. We provide with theoretical justifications to the applicability and experimental validation on real-world datasets to illustrate the working of the proposed method.