 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Frequency Estimation Via Residue Number Systems
Nov 17, 2025We present \textsf{ModularSubsetSelection} (MSS), a new algorithm for locally differentially private (LDP) frequency estimation. Given a universe of size $k$ and $n$ users, our $\varepsilon$-LDP mechanism encodes each input via a Residue Number System (RNS) over $\ell$ pairwise-coprime moduli $m_0, \ldots, m_{\ell-1}$, and reports a randomly chosen index $j \in [\ell]$ along with the perturbed residue using the statistically optimal \textsf{SubsetSelection} (SS) (Wang et al. 2016). This design reduces the user communication cost from $Θ\bigl(ω\log_2(k/ω)\bigr)$ bits required by standard SS (with $ω\approx k/(e^\varepsilon+1)$) down to $\lceil \log_2 \ell \rceil + \lceil \log_2 m_j \rceil$ bits, where $m_j < k$. Server-side decoding runs in $Θ(n + r k \ell)$ time, where $r$ is the number of LSMR (Fong and Saunders 2011) iterations. In practice, with well-conditioned moduli (\textit{i.e.}, constant $r$ and $\ell = Θ(\log k)$), this becomes $Θ(n + k \log k)$. We prove that MSS achieves worst-case MSE within a constant factor of state-of-the-art protocols such as SS and \textsf{ProjectiveGeometryResponse} (PGR) (Feldman et al. 2022) while avoiding the algebraic prerequisites and dynamic-programming decoder required by PGR. Empirically, MSS matches the estimation accuracy of SS, PGR, and \textsf{RAPPOR} (Erlingsson, Pihur, and Korolova 2014) across realistic $(k, \varepsilon)$ settings, while offering faster decoding than PGR and shorter user messages than SS. Lastly, by sampling from multiple moduli and reporting only a single perturbed residue, MSS achieves the lowest reconstruction-attack success rate among all evaluated LDP protocols.
Fair Play for Individuals, Foul Play for Groups? Auditing Anonymization's Impact on ML Fairness
May 12, 2025Machine learning (ML) algorithms are heavily based on the availability of training data, which, depending on the domain, often includes sensitive information about data providers. This raises critical privacy concerns. Anonymization techniques have emerged as a practical solution to address these issues by generalizing features or suppressing data to make it more difficult to accurately identify individuals. Although recent studies have shown that privacy-enhancing technologies can influence ML predictions across different subgroups, thus affecting fair decision-making, the specific effects of anonymization techniques, such as $k$-anonymity, $\ell$-diversity, and $t$-closeness, on ML fairness remain largely unexplored. In this work, we systematically audit the impact of anonymization techniques on ML fairness, evaluating both individual and group fairness. Our quantitative study reveals that anonymization can degrade group fairness metrics by up to four orders of magnitude. Conversely, similarity-based individual fairness metrics tend to improve under stronger anonymization, largely as a result of increased input homogeneity. By analyzing varying levels of anonymization across diverse privacy settings and data distributions, this study provides critical insights into the trade-offs between privacy, fairness, and utility, offering actionable guidelines for responsible AI development. Our code is publicly available at: https://github.com/hharcolezi/anonymity-impact-fairness.
Causal Discovery Under Local Privacy
Nov 15, 2023Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
On the Utility Gain of Iterative Bayesian Update for Locally Differentially Private Mechanisms
Jul 15, 2023This paper investigates the utility gain of using Iterative Bayesian Update (IBU) for private discrete distribution estimation using data obfuscated with Locally Differentially Private (LDP) mechanisms. We compare the performance of IBU to Matrix Inversion (MI), a standard estimation technique, for seven LDP mechanisms designed for one-time data collection and for other seven LDP mechanisms designed for multiple data collections (e.g., RAPPOR). To broaden the scope of our study, we also varied the utility metric, the number of users n, the domain size k, and the privacy parameter {\epsilon}, using both synthetic and real-world data. Our results suggest that IBU can be a useful post-processing tool for improving the utility of LDP mechanisms in different scenarios without any additional privacy cost. For instance, our experiments show that IBU can provide better utility than MI, especially in high privacy regimes (i.e., when {\epsilon} is small). Our paper provides insights for practitioners to use IBU in conjunction with existing LDP mechanisms for more accurate and privacy-preserving data analysis. Finally, we implemented IBU for all fourteen LDP mechanisms into the state-of-the-art multi-freq-ldpy Python package (https://pypi.org/project/multi-freq-ldpy/) and open-sourced all our code used for the experiments as tutorials.
(Local) Differential Privacy has NO Disparate Impact on Fairness
Apr 25, 2023In recent years, Local Differential Privacy (LDP), a robust privacy-preserving methodology, has gained widespread adoption in real-world applications. With LDP, users can perturb their data on their devices before sending it out for analysis. However, as the collection of multiple sensitive information becomes more prevalent across various industries, collecting a single sensitive attribute under LDP may not be sufficient. Correlated attributes in the data may still lead to inferences about the sensitive attribute. This paper empirically studies the impact of collecting multiple sensitive attributes under LDP on fairness. We propose a novel privacy budget allocation scheme that considers the varying domain size of sensitive attributes. This generally led to a better privacy-utility-fairness trade-off in our experiments than the state-of-art solution. Our results show that LDP leads to slightly improved fairness in learning problems without significantly affecting the performance of the models. We conduct extensive experiments evaluating three benchmark datasets using several group fairness metrics and seven state-of-the-art LDP protocols. Overall, this study challenges the common belief that differential privacy necessarily leads to worsened fairness in machine learning.
Differentially Private Multivariate Time Series Forecasting of Aggregated Human Mobility With Deep Learning: Input or Gradient Perturbation?
May 01, 2022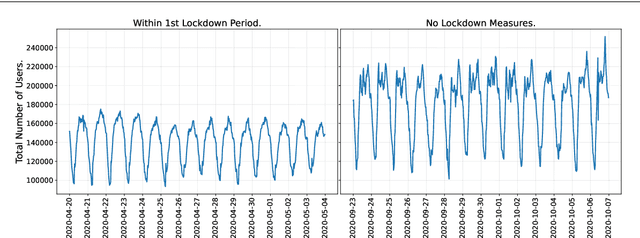
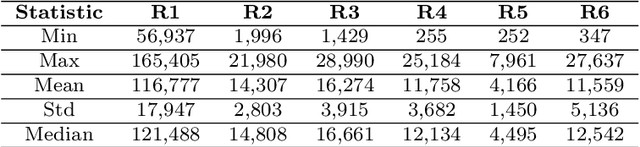
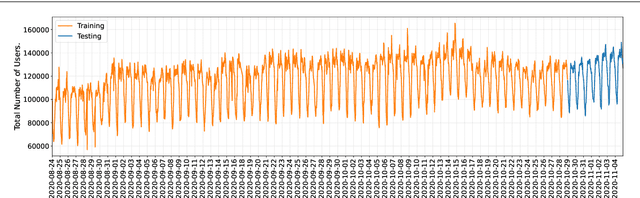

This paper investigates the problem of forecasting multivariate aggregated human mobility while preserving the privacy of the individuals concerned. Differential privacy, a state-of-the-art formal notion, has been used as the privacy guarantee in two different and independent steps when training deep learning models. On one hand, we considered \textit{gradient perturbation}, which uses the differentially private stochastic gradient descent algorithm to guarantee the privacy of each time series sample in the learning stage. On the other hand, we considered \textit{input perturbation}, which adds differential privacy guarantees in each sample of the series before applying any learning. We compared four state-of-the-art recurrent neural networks: Long Short-Term Memory, Gated Recurrent Unit, and their Bidirectional architectures, i.e., Bidirectional-LSTM and Bidirectional-GRU. Extensive experiments were conducted with a real-world multivariate mobility dataset, which we published openly along with this paper. As shown in the results, differentially private deep learning models trained under gradient or input perturbation achieve nearly the same performance as non-private deep learning models, with loss in performance varying between $0.57\%$ to $2.8\%$. The contribution of this paper is significant for those involved in urban planning and decision-making, providing a solution to the human mobility multivariate forecast problem through differentially private deep learning models.
Production of Categorical Data Verifying Differential Privacy: Conception and Applications to Machine Learning
Apr 02, 2022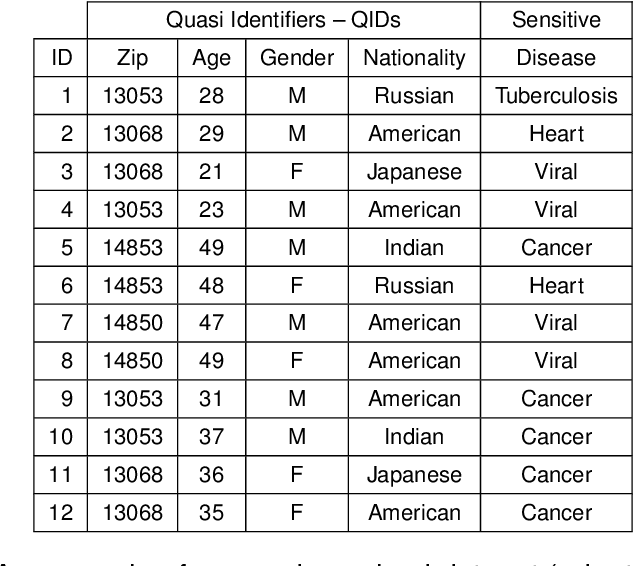

Private and public organizations regularly collect and analyze digitalized data about their associates, volunteers, clients, etc. However, because most personal data are sensitive, there is a key challenge in designing privacy-preserving systems. To tackle privacy concerns, research communities have proposed different methods to preserve privacy, with Differential privacy (DP) standing out as a formal definition that allows quantifying the privacy-utility trade-off. Besides, with the local DP (LDP) model, users can sanitize their data locally before transmitting it to the server. The objective of this thesis is thus two-fold: O$_1$) To improve the utility and privacy in multiple frequency estimates under LDP guarantees, which is fundamental to statistical learning. And O$_2$) To assess the privacy-utility trade-off of machine learning (ML) models trained over differentially private data. For O$_1$, we first tackled the problem from two "multiple" perspectives, i.e., multiple attributes and multiple collections throughout time, while focusing on utility. Secondly, we focused our attention on the multiple attributes aspect only, in which we proposed a solution focusing on privacy while preserving utility. In both cases, we demonstrate through analytical and experimental validations the advantages of our proposed solutions over state-of-the-art LDP protocols. For O$_2$, we empirically evaluated ML-based solutions designed to solve real-world problems while ensuring DP guarantees. Indeed, we mainly used the input data perturbation setting from the privacy-preserving ML literature. This is the situation in which the whole dataset is sanitized independently and, thus, we implemented LDP algorithms from the perspective of the centralized data owner. In all cases, we concluded that differentially private ML models achieve nearly the same utility metrics as non-private ones.