 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduction of Categorical Data Verifying Differential Privacy: Conception and Applications to Machine Learning
Paper and Code
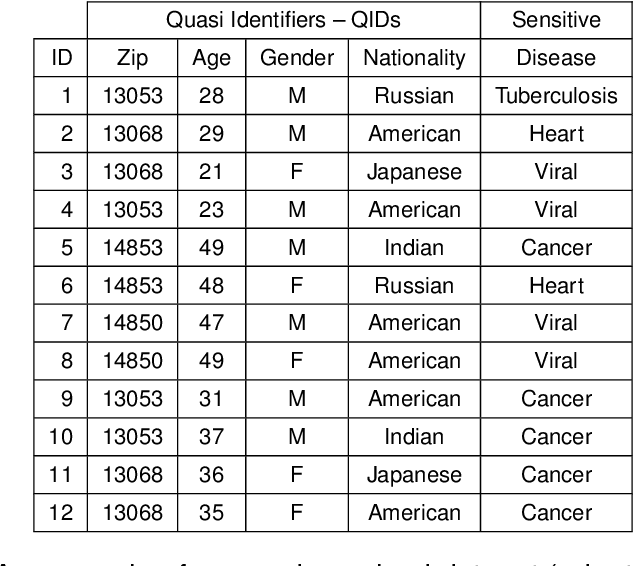
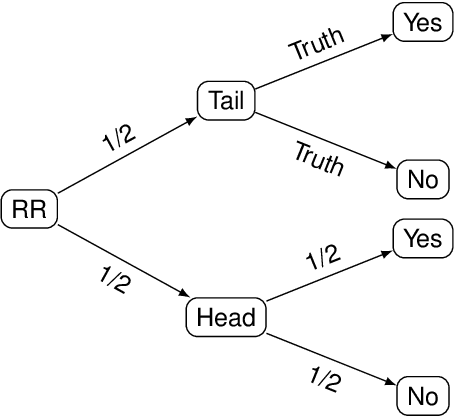

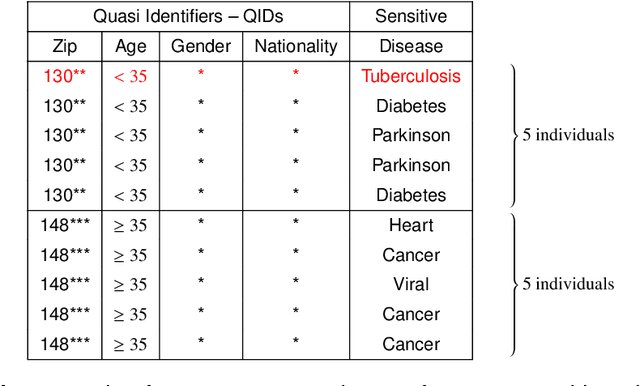
Private and public organizations regularly collect and analyze digitalized data about their associates, volunteers, clients, etc. However, because most personal data are sensitive, there is a key challenge in designing privacy-preserving systems. To tackle privacy concerns, research communities have proposed different methods to preserve privacy, with Differential privacy (DP) standing out as a formal definition that allows quantifying the privacy-utility trade-off. Besides, with the local DP (LDP) model, users can sanitize their data locally before transmitting it to the server. The objective of this thesis is thus two-fold: O$_1$) To improve the utility and privacy in multiple frequency estimates under LDP guarantees, which is fundamental to statistical learning. And O$_2$) To assess the privacy-utility trade-off of machine learning (ML) models trained over differentially private data. For O$_1$, we first tackled the problem from two "multiple" perspectives, i.e., multiple attributes and multiple collections throughout time, while focusing on utility. Secondly, we focused our attention on the multiple attributes aspect only, in which we proposed a solution focusing on privacy while preserving utility. In both cases, we demonstrate through analytical and experimental validations the advantages of our proposed solutions over state-of-the-art LDP protocols. For O$_2$, we empirically evaluated ML-based solutions designed to solve real-world problems while ensuring DP guarantees. Indeed, we mainly used the input data perturbation setting from the privacy-preserving ML literature. This is the situation in which the whole dataset is sanitized independently and, thus, we implemented LDP algorithms from the perspective of the centralized data owner. In all cases, we concluded that differentially private ML models achieve nearly the same utility metrics as non-private ones.