 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeffrey's update rule as a minimizer of Kullback-Leibler divergence
Feb 21, 2025In this paper, we show a more concise and high level proof than the original one, derived by researcher Bart Jacobs, for the following theorem: in the context of Bayesian update rules for learning or updating internal states that produce predictions, the relative entropy between the observations and the predictions is reduced when applying Jeffrey's update rule to update the internal state.
Causal Discovery Under Local Privacy
Nov 15, 2023Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
Causal Discovery for Fairness
Jun 14, 2022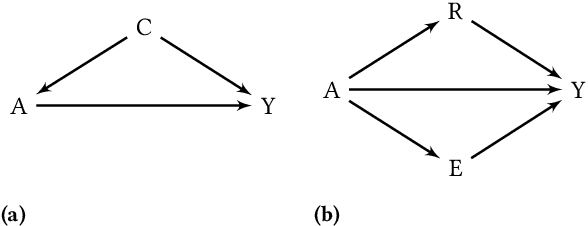
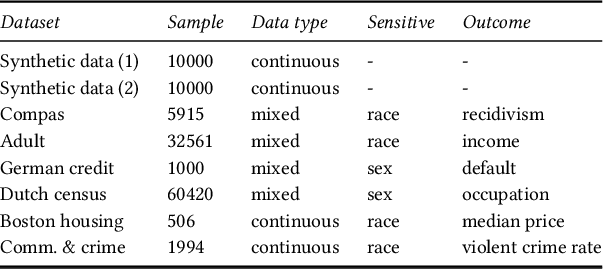
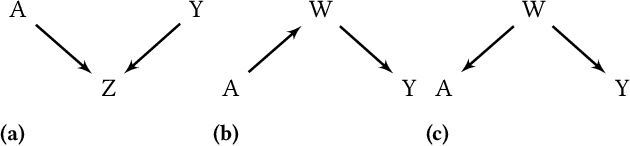
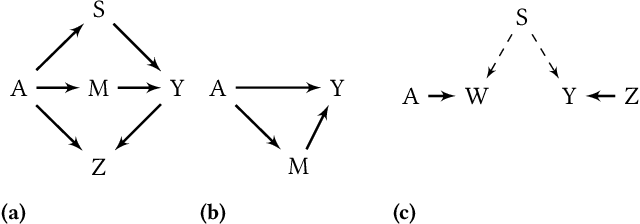
It is crucial to consider the social and ethical consequences of AI and ML based decisions for the safe and acceptable use of these emerging technologies. Fairness, in particular, guarantees that the ML decisions do not result in discrimination against individuals or minorities. Identifying and measuring reliably fairness/discrimination is better achieved using causality which considers the causal relation, beyond mere association, between the sensitive attribute (e.g. gender, race, religion, etc.) and the decision (e.g. job hiring, loan granting, etc.). The big impediment to the use of causality to address fairness, however, is the unavailability of the causal model (typically represented as a causal graph). Existing causal approaches to fairness in the literature do not address this problem and assume that the causal model is available. In this paper, we do not make such assumption and we review the major algorithms to discover causal relations from observable data. This study focuses on causal discovery and its impact on fairness. In particular, we show how different causal discovery approaches may result in different causal models and, most importantly, how even slight differences between causal models can have significant impact on fairness/discrimination conclusions. These results are consolidated by empirical analysis using synthetic and standard fairness benchmark datasets. The main goal of this study is to highlight the importance of the causal discovery step to appropriately address fairness using causality.
On the impossibility of non-trivial accuracy under fairness constraints
Jul 14, 2021

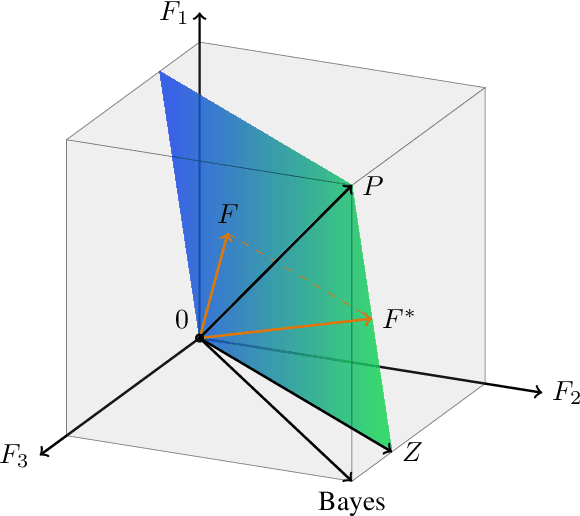
One of the main concerns about fairness in machine learning (ML) is that, in order to achieve it, one may have to renounce to some accuracy. Having this trade-off in mind, Hardt et al. have proposed the notion of equal opportunities (EO), designed so as to be compatible with accuracy. In fact, it can be shown that if the source of input data is deterministic, the two notions go well along with each other. In the probabilistic case, however, things change. As we show, there are probabilistic data sources for which EO can only be achieved at the total detriment of accuracy, i.e. among the models that achieve EO, those whose prediction does not depend on the input have the highest accuracy.