 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Privacy of LLMs: An Ablation Study
May 04, 2026Large language models (LLMs) are increasingly deployed in interactive and retrieval-augmented settings, raising significant privacy concerns. While attacks such as Membership Inference (MIA), Attribute Inference (AIA), Data Extraction (DEA), and Backdoor Attacks (BA) have been studied, they are typically analyzed in isolation, leaving a gap in understanding their behavior under common system factors. In this paper, we introduce a unified threat model and notation, reproduce a representative set of privacy attacks, and conduct a structured ablation study to evaluate the impact of key factors such as model architecture, scale, dataset characteristics, and retrieval configuration. Our analysis reveals clear differences across attack types. Membership inference attacks, particularly mask-based variants, exhibit strong and reliable signals, while backdoor attacks achieve consistently high success rates due to their trigger-based nature. In contrast, attribute inference and data extraction attacks remain more challenging, resulting in lower accuracy, yet they pose significant risks as they target sensitive personal information. Overall, these results highlight that privacy risks in LLM systems are highly context-dependent and driven by design choices, emphasizing the need for holistic evaluation and informed deployment practices.
On the Impact of Multi-dimensional Local Differential Privacy on Fairness
Dec 08, 2023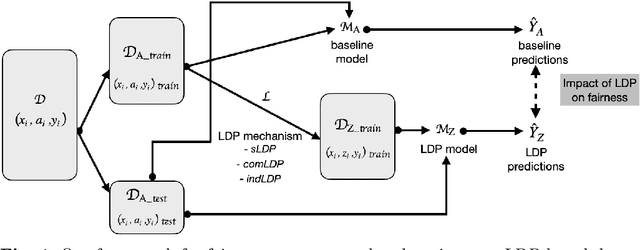



Automated decision systems are increasingly used to make consequential decisions in people's lives. Due to the sensitivity of the manipulated data as well as the resulting decisions, several ethical concerns need to be addressed for the appropriate use of such technologies, in particular, fairness and privacy. Unlike previous work, which focused on centralized differential privacy (DP) or local DP (LDP) for a single sensitive attribute, in this paper, we examine the impact of LDP in the presence of several sensitive attributes (i.e., multi-dimensional data) on fairness. Detailed empirical analysis on synthetic and benchmark datasets revealed very relevant observations. In particular, (1) multi-dimensional LDP is an efficient approach to reduce disparity, (2) the multi-dimensional approach of LDP (independent vs. combined) matters only at low privacy guarantees, and (3) the outcome Y distribution has an important effect on which group is more sensitive to the obfuscation. Last, we summarize our findings in the form of recommendations to guide practitioners in adopting effective privacy-preserving practices while maintaining fairness and utility in ML applications.
Dissecting Causal Biases
Oct 20, 2023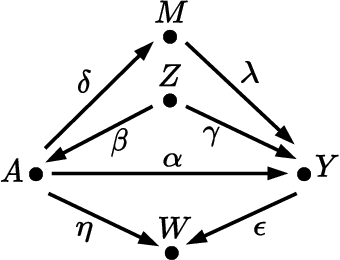

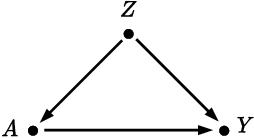
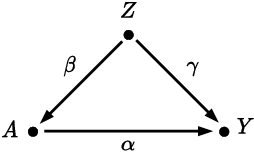
Accurately measuring discrimination in machine learning-based automated decision systems is required to address the vital issue of fairness between subpopulations and/or individuals. Any bias in measuring discrimination can lead to either amplification or underestimation of the true value of discrimination. This paper focuses on a class of bias originating in the way training data is generated and/or collected. We call such class causal biases and use tools from the field of causality to formally define and analyze such biases. Four sources of bias are considered, namely, confounding, selection, measurement, and interaction. The main contribution of this paper is to provide, for each source of bias, a closed-form expression in terms of the model parameters. This makes it possible to analyze the behavior of each source of bias, in particular, in which cases they are absent and in which other cases they are maximized. We hope that the provided characterizations help the community better understand the sources of bias in machine learning applications.
Shedding light on underrepresentation and Sampling Bias in machine learning
Jun 08, 2023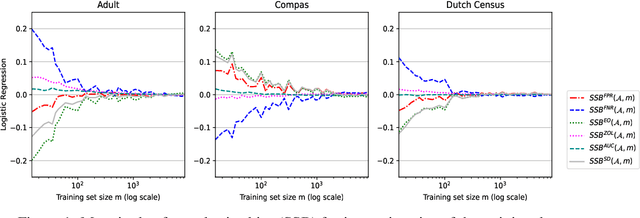
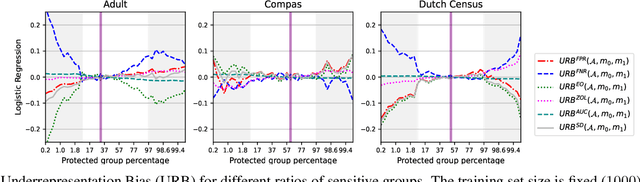
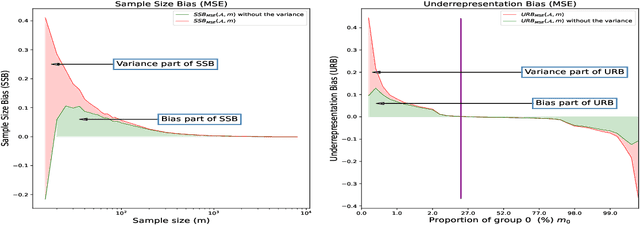
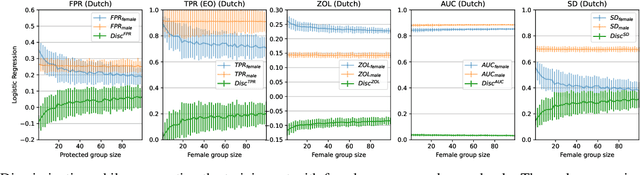
Accurately measuring discrimination is crucial to faithfully assessing fairness of trained machine learning (ML) models. Any bias in measuring discrimination leads to either amplification or underestimation of the existing disparity. Several sources of bias exist and it is assumed that bias resulting from machine learning is born equally by different groups (e.g. females vs males, whites vs blacks, etc.). If, however, bias is born differently by different groups, it may exacerbate discrimination against specific sub-populations. Sampling bias, is inconsistently used in the literature to describe bias due to the sampling procedure. In this paper, we attempt to disambiguate this term by introducing clearly defined variants of sampling bias, namely, sample size bias (SSB) and underrepresentation bias (URB). We show also how discrimination can be decomposed into variance, bias, and noise. Finally, we challenge the commonly accepted mitigation approach that discrimination can be addressed by collecting more samples of the underrepresented group.
Survey on Fairness Notions and Related Tensions
Sep 16, 2022

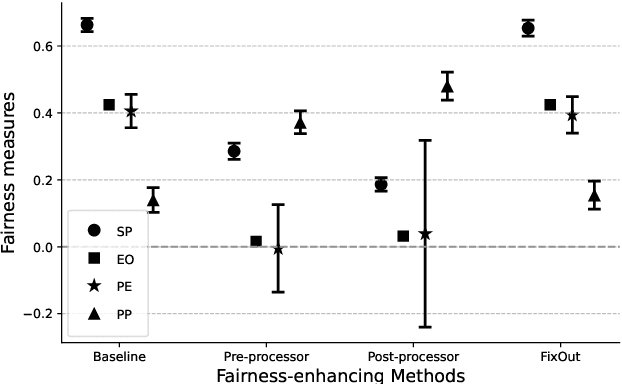
Automated decision systems are increasingly used to take consequential decisions in problems such as job hiring and loan granting with the hope of replacing subjective human decisions with objective machine learning (ML) algorithms. ML-based decision systems, however, are found to be prone to bias which result in yet unfair decisions. Several notions of fairness have been defined in the literature to capture the different subtleties of this ethical and social concept (e.g. statistical parity, equal opportunity, etc.). Fairness requirements to be satisfied while learning models created several types of tensions among the different notions of fairness, but also with other desirable properties such as privacy and classification accuracy. This paper surveys the commonly used fairness notions and discusses the tensions that exist among them and with privacy and accuracy. Different methods to address the fairness-accuracy trade-off (classified into four approaches, namely, pre-processing, in-processing, post-processing, and hybrid) are reviewed. The survey is consolidated with experimental analysis carried out on fairness benchmark datasets to illustrate the relationship between fairness measures and accuracy on real-world scenarios.
On the Need and Applicability of Causality for Fair Machine Learning
Jul 08, 2022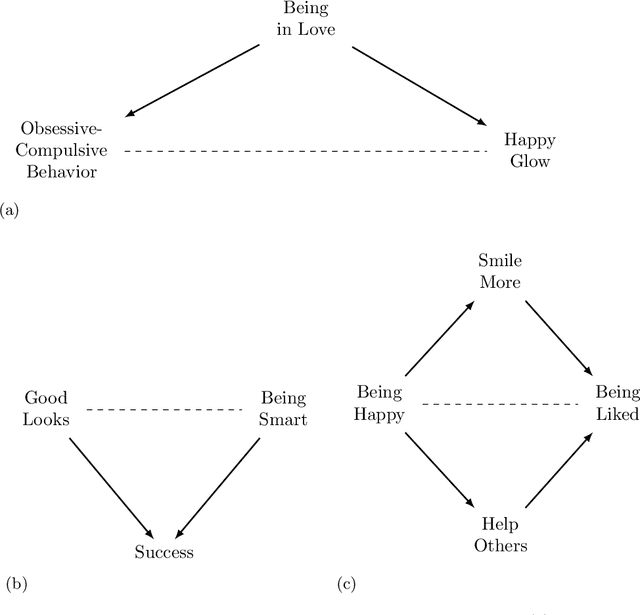
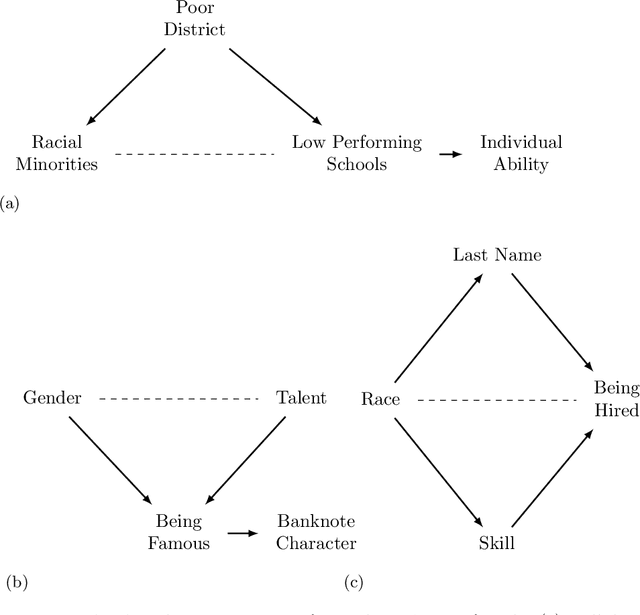
Causal reasoning has an indispensable role in how humans make sense of the world and come to decisions in everyday life. While $20th$ century science was reserved from making causal claims as too strong and not achievable, the $21st$ century is marked by the return of causality encouraged by the mathematization of causal notions and the introduction of the non-deterministic concept of cause~\cite{illari2011look}. Besides its common use cases in epidemiology, political, and social sciences, causality turns out to be crucial in evaluating the fairness of automated decisions, both in a legal and everyday sense. We provide arguments and examples of why causality is particularly important for fairness evaluation. In particular, we point out the social impact of non-causal predictions and the legal anti-discrimination process that relies on causal claims. We conclude with a discussion about the challenges and limitations of applying causality in practical scenarios as well as possible solutions.
Causal Discovery for Fairness
Jun 14, 2022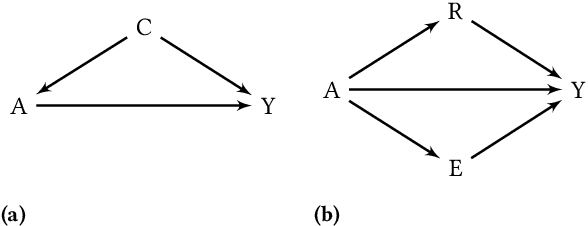
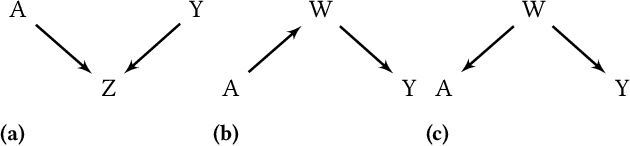
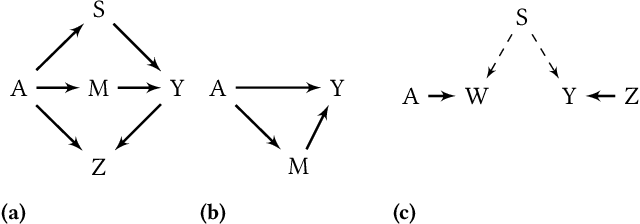
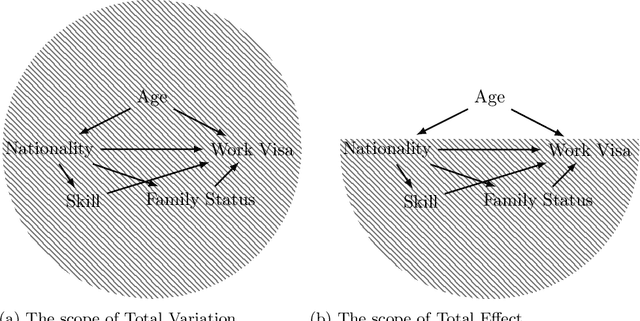
It is crucial to consider the social and ethical consequences of AI and ML based decisions for the safe and acceptable use of these emerging technologies. Fairness, in particular, guarantees that the ML decisions do not result in discrimination against individuals or minorities. Identifying and measuring reliably fairness/discrimination is better achieved using causality which considers the causal relation, beyond mere association, between the sensitive attribute (e.g. gender, race, religion, etc.) and the decision (e.g. job hiring, loan granting, etc.). The big impediment to the use of causality to address fairness, however, is the unavailability of the causal model (typically represented as a causal graph). Existing causal approaches to fairness in the literature do not address this problem and assume that the causal model is available. In this paper, we do not make such assumption and we review the major algorithms to discover causal relations from observable data. This study focuses on causal discovery and its impact on fairness. In particular, we show how different causal discovery approaches may result in different causal models and, most importantly, how even slight differences between causal models can have significant impact on fairness/discrimination conclusions. These results are consolidated by empirical analysis using synthetic and standard fairness benchmark datasets. The main goal of this study is to highlight the importance of the causal discovery step to appropriately address fairness using causality.
Identifiability of Causal-based Fairness Notions: A State of the Art
Mar 11, 2022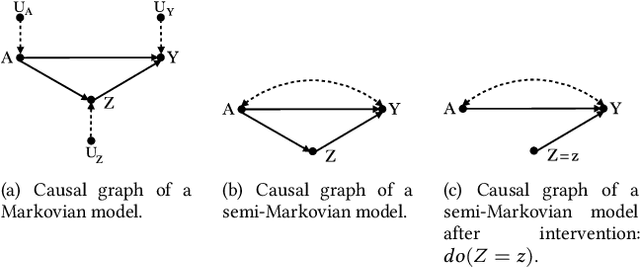
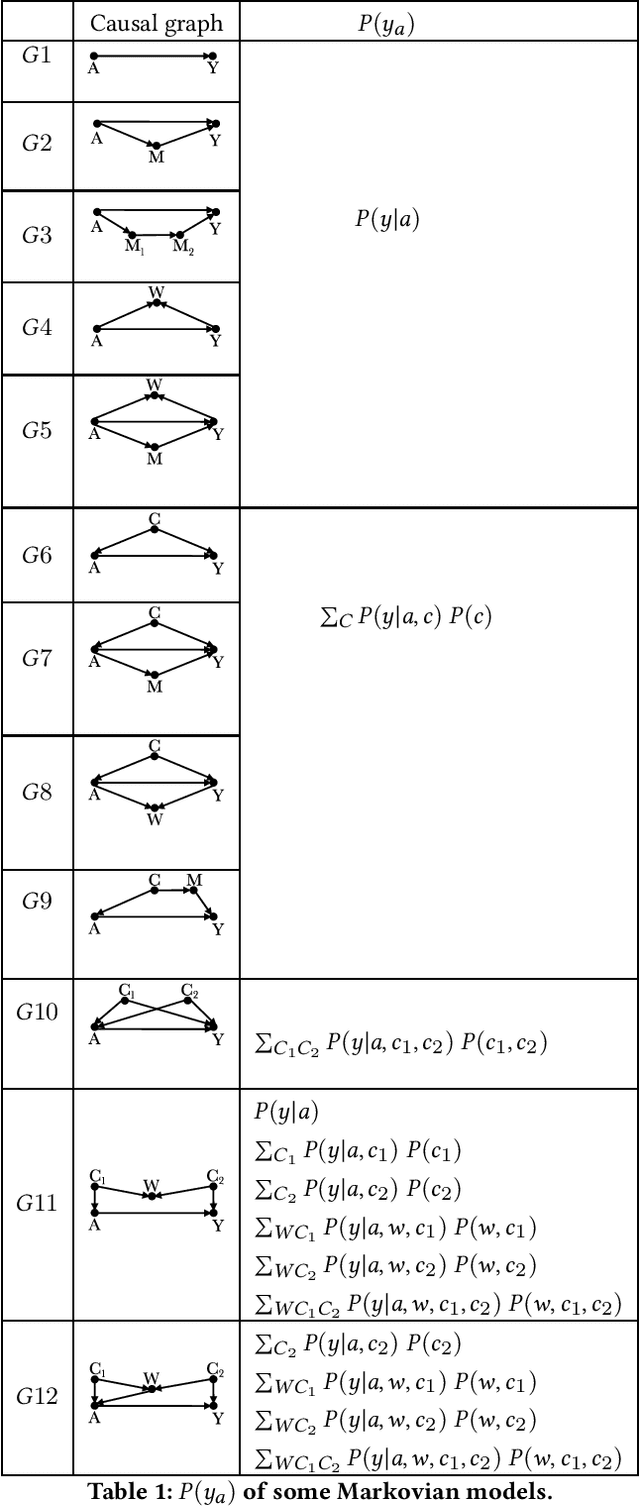
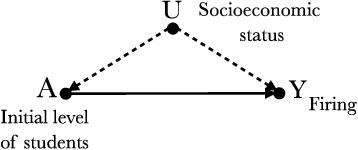
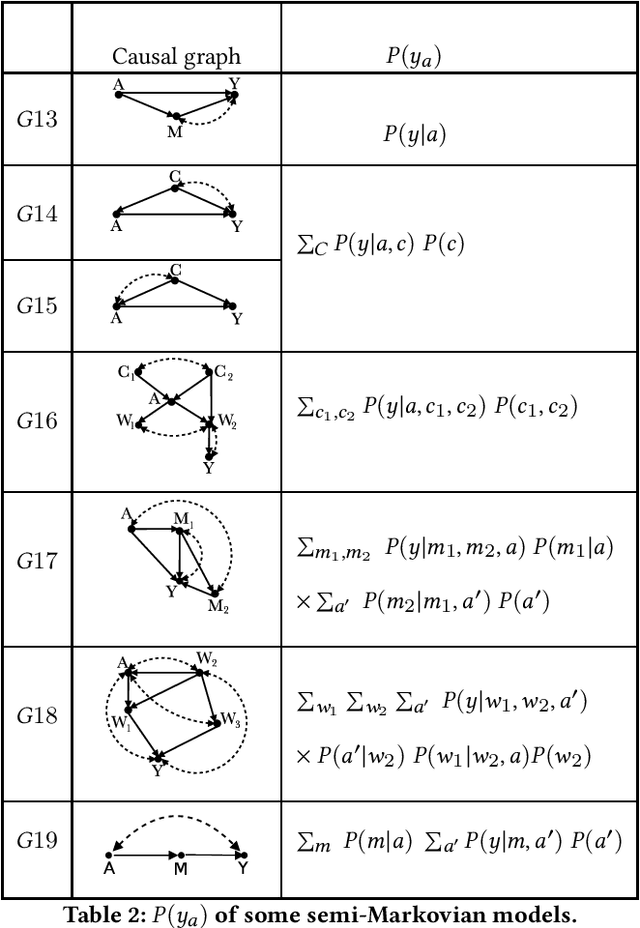
Machine learning algorithms can produce biased outcome/prediction, typically, against minorities and under-represented sub-populations. Therefore, fairness is emerging as an important requirement for the large scale application of machine learning based technologies. The most commonly used fairness notions (e.g. statistical parity, equalized odds, predictive parity, etc.) are observational and rely on mere correlation between variables. These notions fail to identify bias in case of statistical anomalies such as Simpson's or Berkson's paradoxes. Causality-based fairness notions (e.g. counterfactual fairness, no-proxy discrimination, etc.) are immune to such anomalies and hence more reliable to assess fairness. The problem of causality-based fairness notions, however, is that they are defined in terms of quantities (e.g. causal, counterfactual, and path-specific effects) that are not always measurable. This is known as the identifiability problem and is the topic of a large body of work in the causal inference literature. This paper is a compilation of the major identifiability results which are of particular relevance for machine learning fairness. The results are illustrated using a large number of examples and causal graphs. The paper would be of particular interest to fairness researchers, practitioners, and policy makers who are considering the use of causality-based fairness notions as it summarizes and illustrates the major identifiability results
Survey on Causal-based Machine Learning Fairness Notions
Oct 25, 2020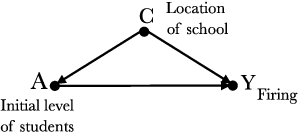
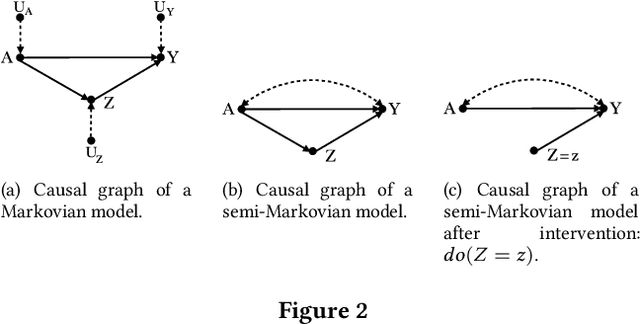
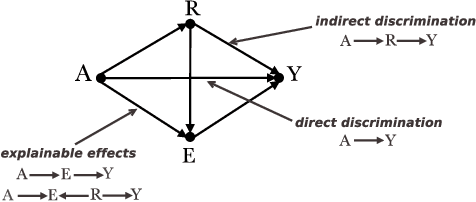
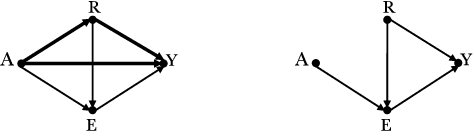
Addressing the problem of fairness is crucial to safely use machine learning algorithms to support decisions with a critical impact on people's lives such as job hiring, child maltreatment, disease diagnosis, loan granting, etc. Several notions of fairness have been defined and examined in the past decade, such as, statistical parity and equalized odds. The most recent fairness notions, however, are causal-based and reflect the now widely accepted idea that using causality is necessary to appropriately address the problem of fairness. This paper examines an exhaustive list of causal-based fairness notions, in particular their applicability in real-world scenarios. As the majority of causal-based fairness notions are defined in terms of non-observable quantities (e.g. interventions and counterfactuals), their applicability depends heavily on the identifiability of those quantities from observational data. In this paper, we compile the most relevant identifiability criteria for the problem of fairness from the extensive literature on identifiability theory. These criteria are then used to decide about the applicability of causal-based fairness notions in concrete discrimination scenarios.
On the Applicability of ML Fairness Notions
Jun 30, 2020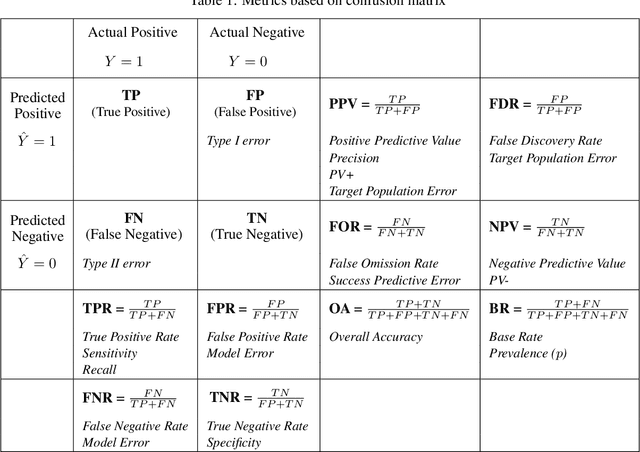
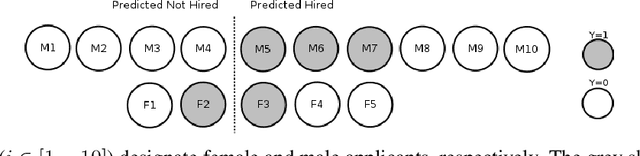
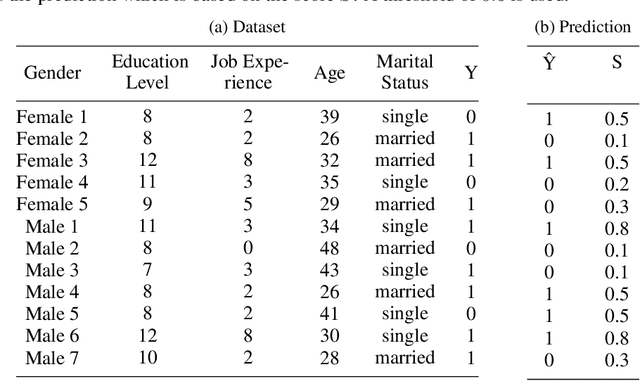
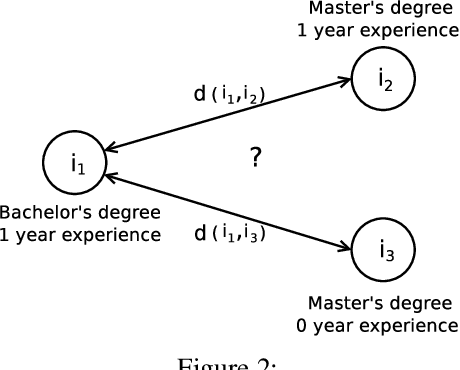
ML-based predictive systems are increasingly used to support decisions with a critical impact on individuals' lives such as college admission, job hiring, child custody, criminal risk assessment, etc. As a result, fairness emerged as an important requirement to guarantee that predictive systems do not discriminate against specific individuals or entire sub-populations, in particular, minorities. Given the inherent subjectivity of viewing the concept of fairness, several notions of fairness have been introduced in the literature. This paper is a survey of fairness notions that, unlike other surveys in the literature, addresses the question of "which notion of fairness is most suited to a given real-world scenario and why?". Our attempt to answer this question consists in (1) identifying the set of fairness-related characteristics of the real-world scenario at hand, (2) analyzing the behavior of each fairness notion, and then (3) fitting these two elements to recommend the most suitable fairness notion in every specific setup. The results are summarized in a decision diagram that can be used by practitioners and policy makers to navigate the relatively large catalogue of fairness notions.