 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding light on underrepresentation and Sampling Bias in machine learning
Paper and Code
Jun 08, 2023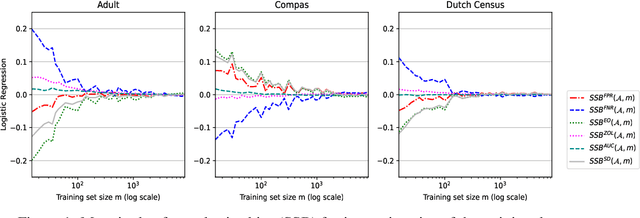
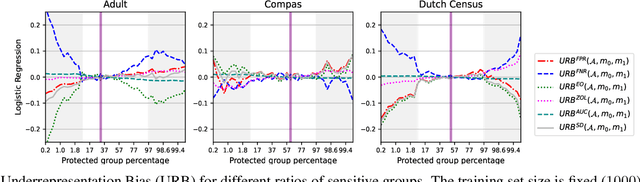
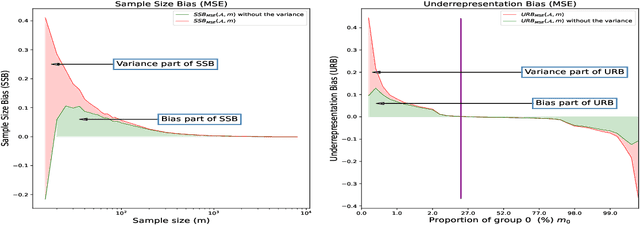
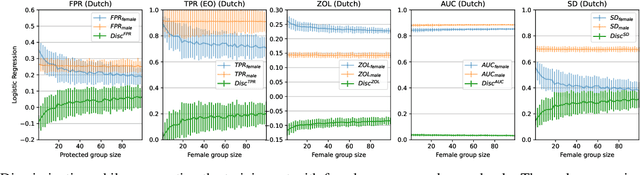
Accurately measuring discrimination is crucial to faithfully assessing fairness of trained machine learning (ML) models. Any bias in measuring discrimination leads to either amplification or underestimation of the existing disparity. Several sources of bias exist and it is assumed that bias resulting from machine learning is born equally by different groups (e.g. females vs males, whites vs blacks, etc.). If, however, bias is born differently by different groups, it may exacerbate discrimination against specific sub-populations. Sampling bias, is inconsistently used in the literature to describe bias due to the sampling procedure. In this paper, we attempt to disambiguate this term by introducing clearly defined variants of sampling bias, namely, sample size bias (SSB) and underrepresentation bias (URB). We show also how discrimination can be decomposed into variance, bias, and noise. Finally, we challenge the commonly accepted mitigation approach that discrimination can be addressed by collecting more samples of the underrepresented group.