 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Fairness Notions and Related Tensions
Sep 16, 2022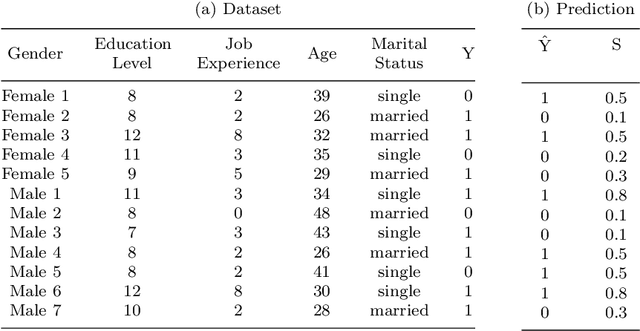

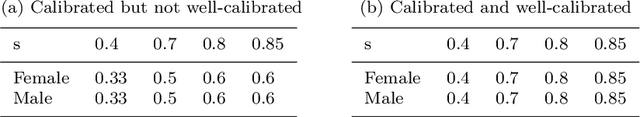
Automated decision systems are increasingly used to take consequential decisions in problems such as job hiring and loan granting with the hope of replacing subjective human decisions with objective machine learning (ML) algorithms. ML-based decision systems, however, are found to be prone to bias which result in yet unfair decisions. Several notions of fairness have been defined in the literature to capture the different subtleties of this ethical and social concept (e.g. statistical parity, equal opportunity, etc.). Fairness requirements to be satisfied while learning models created several types of tensions among the different notions of fairness, but also with other desirable properties such as privacy and classification accuracy. This paper surveys the commonly used fairness notions and discusses the tensions that exist among them and with privacy and accuracy. Different methods to address the fairness-accuracy trade-off (classified into four approaches, namely, pre-processing, in-processing, post-processing, and hybrid) are reviewed. The survey is consolidated with experimental analysis carried out on fairness benchmark datasets to illustrate the relationship between fairness measures and accuracy on real-world scenarios.
Reducing Unintended Bias of ML Models on Tabular and Textual Data
Aug 05, 2021



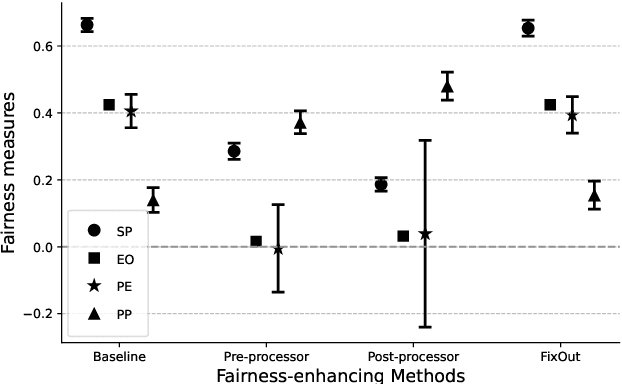
Unintended biases in machine learning (ML) models are among the major concerns that must be addressed to maintain public trust in ML. In this paper, we address process fairness of ML models that consists in reducing the dependence of models on sensitive features, without compromising their performance. We revisit the framework FixOut that is inspired in the approach "fairness through unawareness" to build fairer models. We introduce several improvements such as automating the choice of FixOut's parameters. Also, FixOut was originally proposed to improve fairness of ML models on tabular data. We also demonstrate the feasibility of FixOut's workflow for models on textual data. We present several experimental results that illustrate the fact that FixOut improves process fairness on different classification settings.
Making ML models fairer through explanations: the case of LimeOut
Nov 01, 2020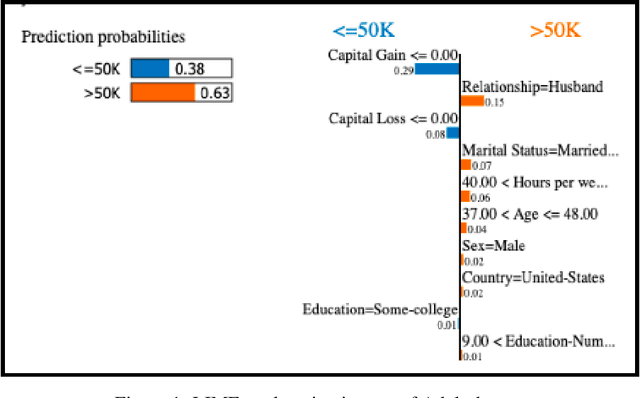
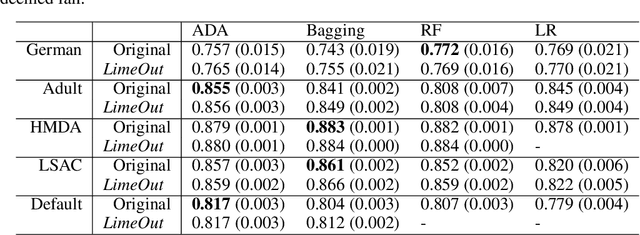

Algorithmic decisions are now being used on a daily basis, and based on Machine Learning (ML) processes that may be complex and biased. This raises several concerns given the critical impact that biased decisions may have on individuals or on society as a whole. Not only unfair outcomes affect human rights, they also undermine public trust in ML and AI. In this paper we address fairness issues of ML models based on decision outcomes, and we show how the simple idea of "feature dropout" followed by an "ensemble approach" can improve model fairness. To illustrate, we will revisit the case of "LimeOut" that was proposed to tackle "process fairness", which measures a model's reliance on sensitive or discriminatory features. Given a classifier, a dataset and a set of sensitive features, LimeOut first assesses whether the classifier is fair by checking its reliance on sensitive features using "Lime explanations". If deemed unfair, LimeOut then applies feature dropout to obtain a pool of classifiers. These are then combined into an ensemble classifier that was empirically shown to be less dependent on sensitive features without compromising the classifier's accuracy. We present different experiments on multiple datasets and several state of the art classifiers, which show that LimeOut's classifiers improve (or at least maintain) not only process fairness but also other fairness metrics such as individual and group fairness, equal opportunity, and demographic parity.