 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Tester: Training Open-Source LLMs for Issue Reproduction in Real-World Repositories
Jan 20, 2026Software testing is crucial for ensuring the correctness and reliability of software systems. Automated generation of issue reproduction tests from natural language issue descriptions enhances developer productivity by simplifying root cause analysis, promotes test-driven development -- "test first, write code later", and can be used for improving the effectiveness of automated issue resolution systems like coding agents. Existing methods proposed for this task predominantly rely on closed-source LLMs, with limited exploration of open models. To address this, we propose SWE-Tester -- a novel pipeline for training open-source LLMs to generate issue reproduction tests. First, we curate a high-quality training dataset of 41K instances from 2.6K open-source GitHub repositories and use it to train LLMs of varying sizes and families. The fine-tuned models achieve absolute improvements of up to 10\% in success rate and 21\% in change coverage on SWT-Bench Verified. Further analysis shows consistent improvements with increased inference-time compute, more data, and larger models. These results highlight the effectiveness of our framework for advancing open-source LLMs in this domain.
Go-UT-Bench: A Fine-Tuning Dataset for LLM-Based Unit Test Generation in Go
Nov 14, 2025Training data imbalance poses a major challenge for code LLMs. Most available data heavily over represents raw opensource code while underrepresenting broader software engineering tasks, especially in low resource languages like Golang. As a result, models excel at code autocompletion but struggle with real world developer workflows such as unit test generation. To address this gap, we introduce GO UT Bench, a benchmark dataset of 5264 pairs of code and unit tests, drawn from 10 permissively licensed Golang repositories spanning diverse domain. We evaluate its effectiveness as a fine tuning dataset across two LLM families i.e. mixture of experts and dense decoders. Our results show that finetuned models outperform their base counterparts on more than 75% of benchmark tasks.
Predictive Scaling Laws for Efficient GRPO Training of Large Reasoning Models
Jul 24, 2025



Fine-tuning large language models (LLMs) for reasoning tasks using reinforcement learning methods like Group Relative Policy Optimization (GRPO) is computationally expensive. To address this, we propose a predictive framework that models training dynamics and helps optimize resource usage. Through experiments on Llama and Qwen models (3B 8B), we derive an empirical scaling law based on model size, initial performance, and training progress. This law predicts reward trajectories and identifies three consistent training phases: slow start, rapid improvement, and plateau. We find that training beyond certain number of an epoch offers little gain, suggesting earlier stopping can significantly reduce compute without sacrificing performance. Our approach generalizes across model types, providing a practical guide for efficient GRPO-based fine-tuning.
CPP-UT-Bench: Can LLMs Write Complex Unit Tests in C++?
Dec 03, 2024
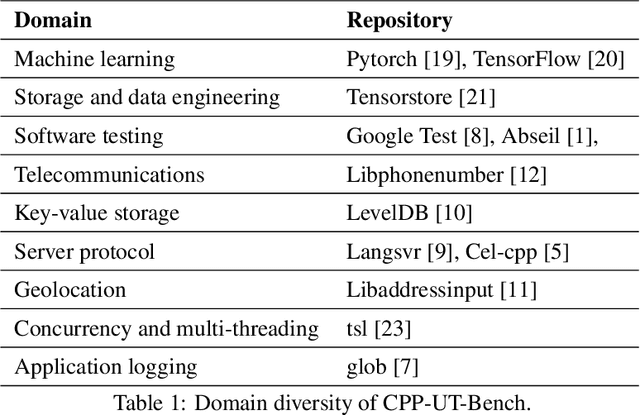
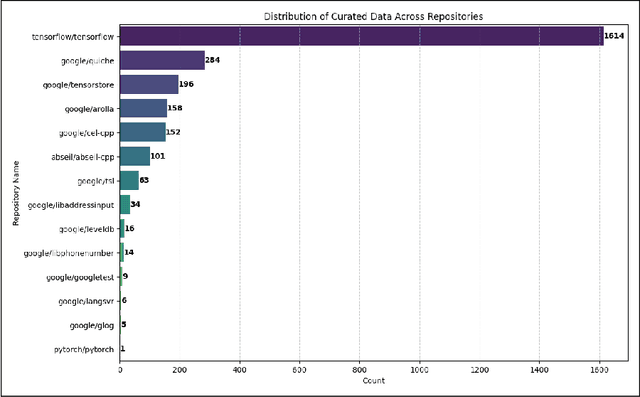
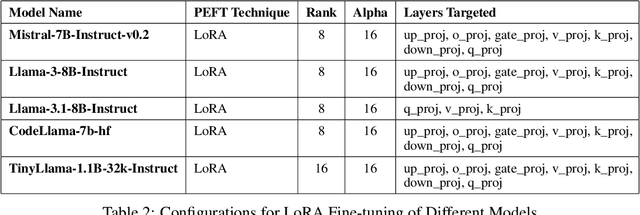
We introduce CPP-UT-Bench, a benchmark dataset to measure C++ unit test generation capability of a large language model (LLM). CPP-UT-Bench aims to reflect a broad and diverse set of C++ codebases found in the real world. The dataset includes 2,653 {code, unit test} pairs drawn from 14 different opensource C++ codebases spanned across nine diverse domains including machine learning, software testing, parsing, standard input-output, data engineering, logging, complete expression evaluation, key value storage, and server protocols. We demonstrated the effectiveness of CPP-UT-Bench as a benchmark dataset through extensive experiments in in-context learning, parameter-efficient fine-tuning (PEFT), and full-parameter fine-tuning. We also discussed the challenges of the dataset compilation and insights we learned from in-context learning and fine-tuning experiments. Besides the CPP-UT-Bench dataset and data compilation code, we are also offering the fine-tuned model weights for further research. For nine out of ten experiments, our fine-tuned LLMs outperformed the corresponding base models by an average of more than 70%.
s-LIME: Reconciling Locality and Fidelity in Linear Explanations
Aug 02, 2022The benefit of locality is one of the major premises of LIME, one of the most prominent methods to explain black-box machine learning models. This emphasis relies on the postulate that the more locally we look at the vicinity of an instance, the simpler the black-box model becomes, and the more accurately we can mimic it with a linear surrogate. As logical as this seems, our findings suggest that, with the current design of LIME, the surrogate model may degenerate when the explanation is too local, namely, when the bandwidth parameter $\sigma$ tends to zero. Based on this observation, the contribution of this paper is twofold. Firstly, we study the impact of both the bandwidth and the training vicinity on the fidelity and semantics of LIME explanations. Secondly, and based on our findings, we propose \slime, an extension of LIME that reconciles fidelity and locality.
Making ML models fairer through explanations: the case of LimeOut
Nov 01, 2020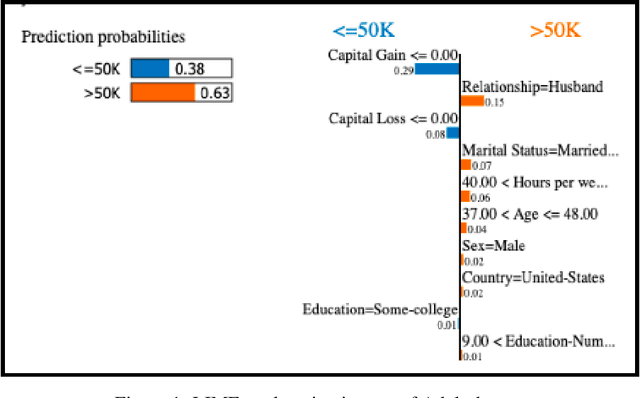
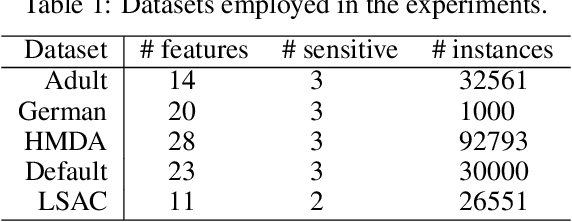
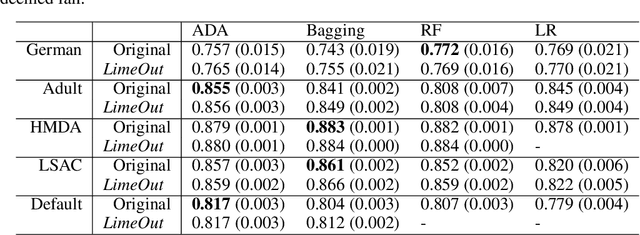

Algorithmic decisions are now being used on a daily basis, and based on Machine Learning (ML) processes that may be complex and biased. This raises several concerns given the critical impact that biased decisions may have on individuals or on society as a whole. Not only unfair outcomes affect human rights, they also undermine public trust in ML and AI. In this paper we address fairness issues of ML models based on decision outcomes, and we show how the simple idea of "feature dropout" followed by an "ensemble approach" can improve model fairness. To illustrate, we will revisit the case of "LimeOut" that was proposed to tackle "process fairness", which measures a model's reliance on sensitive or discriminatory features. Given a classifier, a dataset and a set of sensitive features, LimeOut first assesses whether the classifier is fair by checking its reliance on sensitive features using "Lime explanations". If deemed unfair, LimeOut then applies feature dropout to obtain a pool of classifiers. These are then combined into an ensemble classifier that was empirically shown to be less dependent on sensitive features without compromising the classifier's accuracy. We present different experiments on multiple datasets and several state of the art classifiers, which show that LimeOut's classifiers improve (or at least maintain) not only process fairness but also other fairness metrics such as individual and group fairness, equal opportunity, and demographic parity.
LimeOut: An Ensemble Approach To Improve Process Fairness
Jun 17, 2020



Artificial Intelligence and Machine Learning are becoming increasingly present in several aspects of human life, especially, those dealing with decision making. Many of these algorithmic decisions are taken without human supervision and through decision making processes that are not transparent. This raises concerns regarding the potential bias of these processes towards certain groups of society, which may entail unfair results and, possibly, violations of human rights. Dealing with such biased models is one of the major concerns to maintain the public trust. In this paper, we address the question of process or procedural fairness. More precisely, we consider the problem of making classifiers fairer by reducing their dependence on sensitive features while increasing (or, at least, maintaining) their accuracy. To achieve both, we draw inspiration from "dropout" techniques in neural based approaches, and propose a framework that relies on "feature drop-out" to tackle process fairness. We make use of "LIME Explanations" to assess a classifier's fairness and to determine the sensitive features to remove. This produces a pool of classifiers (through feature dropout) whose ensemble is shown empirically to be less dependent on sensitive features, and with improved or no impact on accuracy.