 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic Learning: A Framework for Decentralized Learning with Model Fragmentation
Feb 04, 2026Decentralized learning (DL) enables collaborative machine learning (ML) without a central server, making it suitable for settings where training data cannot be centrally hosted. We introduce Mosaic Learning, a DL framework that decomposes models into fragments and disseminates them independently across the network. Fragmentation reduces redundant communication across correlated parameters and enables more diverse information propagation without increasing communication cost. We theoretically show that Mosaic Learning (i) shows state-of-the-art worst-case convergence rate, and (ii) leverages parameter correlation in an ML model, improving contraction by reducing the highest eigenvalue of a simplified system. We empirically evaluate Mosaic Learning on four learning tasks and observe up to 12 percentage points higher node-level test accuracy compared to epidemic learning (EL), a state-of-the-art baseline. In summary, Mosaic Learning improves DL performance without sacrificing its utility or efficiency, and positions itself as a new DL standard.
Low-Cost Privacy-Aware Decentralized Learning
Mar 18, 2024
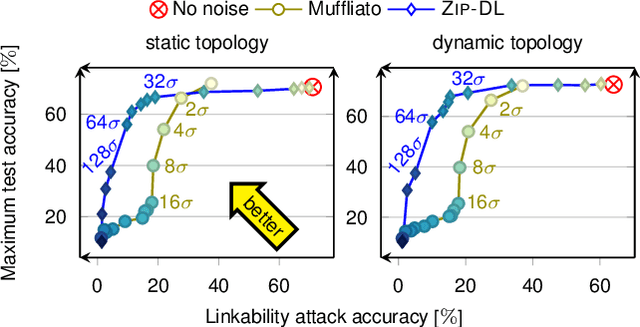
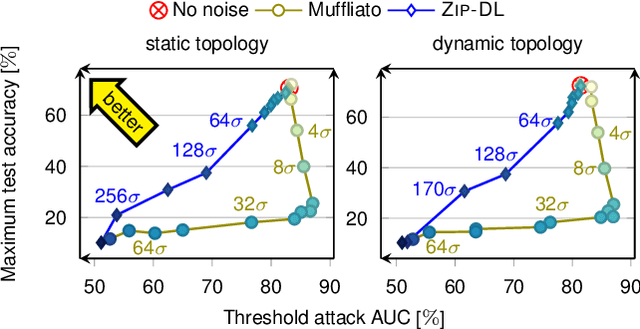
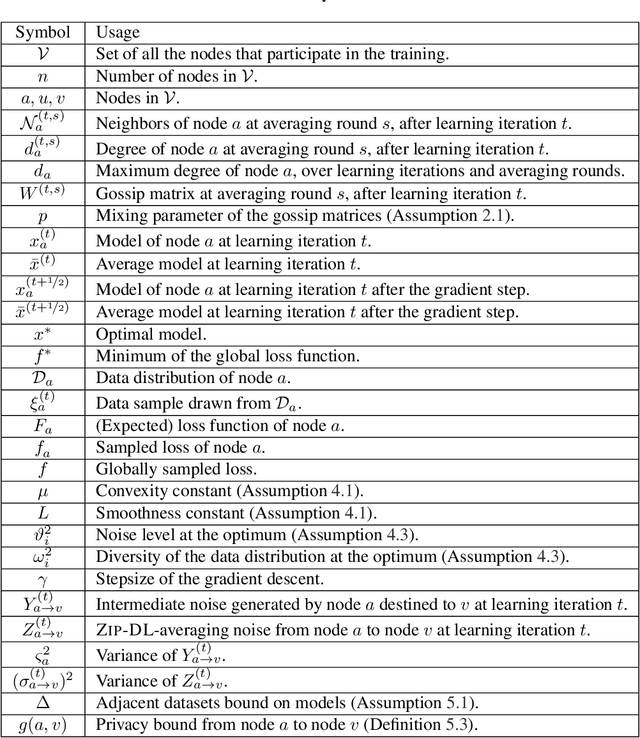
This paper introduces ZIP-DL, a novel privacy-aware decentralized learning (DL) algorithm that relies on adding correlated noise to each model update during the model training process. This technique ensures that the added noise almost neutralizes itself during the aggregation process due to its correlation, thus minimizing the impact on model accuracy. In addition, ZIP-DL does not require multiple communication rounds for noise cancellation, addressing the common trade-off between privacy protection and communication overhead. We provide theoretical guarantees for both convergence speed and privacy guarantees, thereby making ZIP-DL applicable to practical scenarios. Our extensive experimental study shows that ZIP-DL achieves the best trade-off between vulnerability and accuracy. In particular, ZIP-DL (i) reduces the effectiveness of a linkability attack by up to 52 points compared to baseline DL, and (ii) achieves up to 37 more accuracy points for the same vulnerability under membership inference attacks against a privacy-preserving competitor
Shaping Up SHAP: Enhancing Stability through Layer-Wise Neighbor Selection
Dec 19, 2023

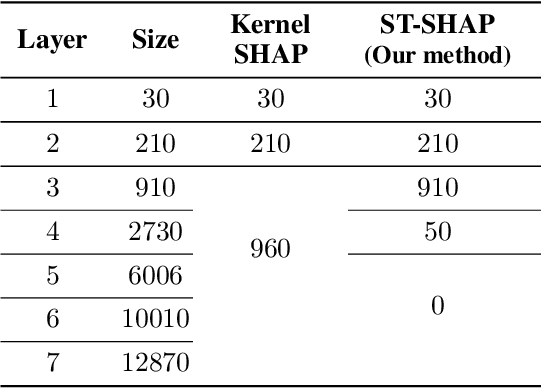

Machine learning techniques, such as deep learning and ensemble methods, are widely used in various domains due to their ability to handle complex real-world tasks. However, their black-box nature has raised multiple concerns about the fairness, trustworthiness, and transparency of computer-assisted decision-making. This has led to the emergence of local post-hoc explainability methods, which offer explanations for individual decisions made by black-box algorithms. Among these methods, Kernel SHAP is widely used due to its model-agnostic nature and its well-founded theoretical framework. Despite these strengths, Kernel SHAP suffers from high instability: different executions of the method with the same inputs can lead to significantly different explanations, which diminishes the utility of post-hoc explainability. The contribution of this paper is two-fold. On the one hand, we show that Kernel SHAP's instability is caused by its stochastic neighbor selection procedure, which we adapt to achieve full stability without compromising explanation fidelity. On the other hand, we show that by restricting the neighbors generation to perturbations of size 1 -- which we call the coalitions of Layer 1 -- we obtain a novel feature-attribution method that is fully stable, efficient to compute, and still meaningful.
UniRank: Unimodal Bandit Algorithm for Online Ranking
Aug 02, 2022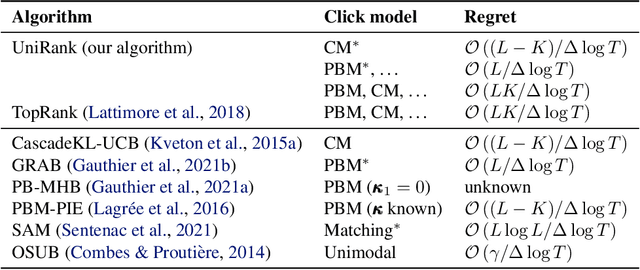


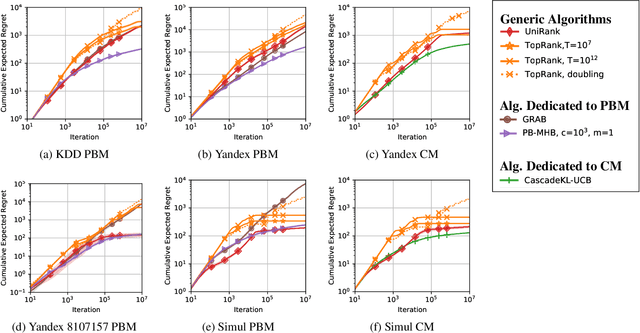
We tackle a new emerging problem, which is finding an optimal monopartite matching in a weighted graph. The semi-bandit version, where a full matching is sampled at each iteration, has been addressed by \cite{ADMA}, creating an algorithm with an expected regret matching $O(\frac{L\log(L)}{\Delta}\log(T))$ with $2L$ players, $T$ iterations and a minimum reward gap $\Delta$. We reduce this bound in two steps. First, as in \cite{GRAB} and \cite{UniRank} we use the unimodality property of the expected reward on the appropriate graph to design an algorithm with a regret in $O(L\frac{1}{\Delta}\log(T))$. Secondly, we show that by moving the focus towards the main question `\emph{Is user $i$ better than user $j$?}' this regret becomes $O(L\frac{\Delta}{\tilde{\Delta}^2}\log(T))$, where $\Tilde{\Delta} > \Delta$ derives from a better way of comparing users. Some experimental results finally show these theoretical results are corroborated in practice.
Unimodal Mono-Partite Matching in a Bandit Setting
Aug 02, 2022
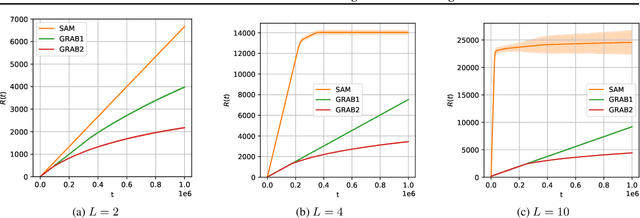

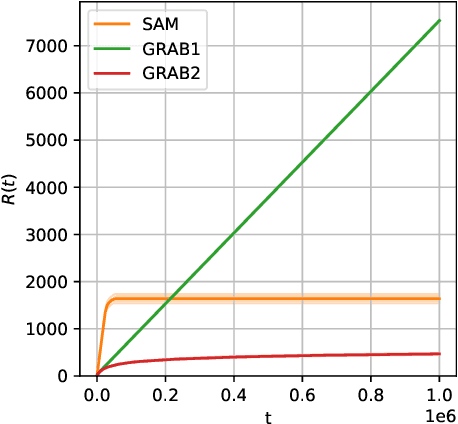
We tackle a new emerging problem, which is finding an optimal monopartite matching in a weighted graph. The semi-bandit version, where a full matching is sampled at each iteration, has been addressed by \cite{ADMA}, creating an algorithm with an expected regret matching $O(\frac{L\log(L)}{\Delta}\log(T))$ with $2L$ players, $T$ iterations and a minimum reward gap $\Delta$. We reduce this bound in two steps. First, as in \cite{GRAB} and \cite{UniRank} we use the unimodality property of the expected reward on the appropriate graph to design an algorithm with a regret in $O(L\frac{1}{\Delta}\log(T))$. Secondly, we show that by moving the focus towards the main question `\emph{Is user $i$ better than user $j$?}' this regret becomes $O(L\frac{\Delta}{\tilde{\Delta}^2}\log(T))$, where $\Tilde{\Delta} > \Delta$ derives from a better way of comparing users. Some experimental results finally show these theoretical results are corroborated in practice.
s-LIME: Reconciling Locality and Fidelity in Linear Explanations
Aug 02, 2022The benefit of locality is one of the major premises of LIME, one of the most prominent methods to explain black-box machine learning models. This emphasis relies on the postulate that the more locally we look at the vicinity of an instance, the simpler the black-box model becomes, and the more accurately we can mimic it with a linear surrogate. As logical as this seems, our findings suggest that, with the current design of LIME, the surrogate model may degenerate when the explanation is too local, namely, when the bandwidth parameter $\sigma$ tends to zero. Based on this observation, the contribution of this paper is twofold. Firstly, we study the impact of both the bandwidth and the training vicinity on the fidelity and semantics of LIME explanations. Secondly, and based on our findings, we propose \slime, an extension of LIME that reconciles fidelity and locality.
Position-Based Multiple-Play Bandits with Thompson Sampling
Sep 28, 2020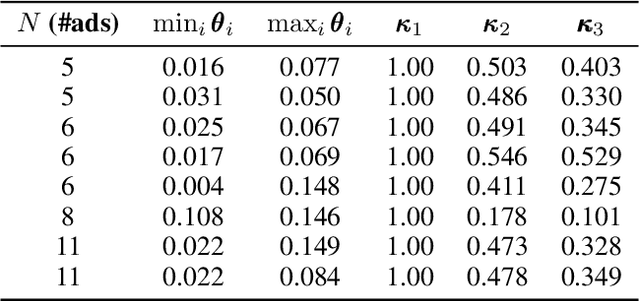

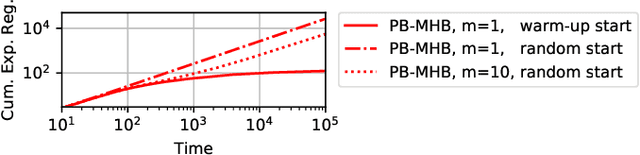

Multiple-play bandits aim at displaying relevant items at relevant positions on a web page. We introduce a new bandit-based algorithm, PB-MHB, for online recommender systems which uses the Thompson sampling framework. This algorithm handles a display setting governed by the position-based model. Our sampling method does not require as input the probability of a user to look at a given position in the web page which is, in practice, very difficult to obtain. Experiments on simulated and real datasets show that our method, with fewer prior information, deliver better recommendations than state-of-the-art algorithms.
Hybrid Recommender System based on Autoencoders
Dec 29, 2017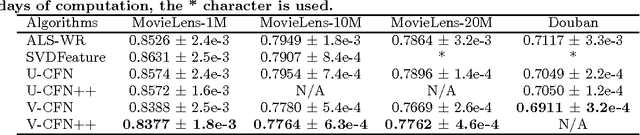
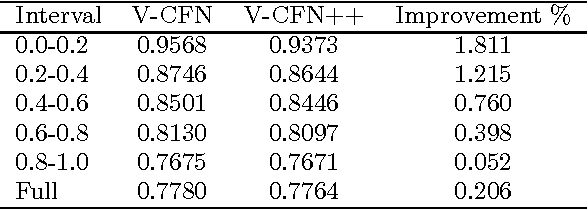
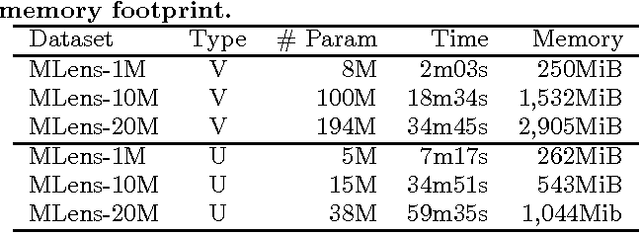
A standard model for Recommender Systems is the Matrix Completion setting: given partially known matrix of ratings given by users (rows) to items (columns), infer the unknown ratings. In the last decades, few attempts where done to handle that objective with Neural Networks, but recently an architecture based on Autoencoders proved to be a promising approach. In current paper, we enhanced that architecture (i) by using a loss function adapted to input data with missing values, and (ii) by incorporating side information. The experiments demonstrate that while side information only slightly improve the test error averaged on all users/items, it has more impact on cold users/items.
* arXiv admin note: substantial text overlap with arXiv:1603.00806
Hybrid Collaborative Filtering with Autoencoders
Jul 19, 2016
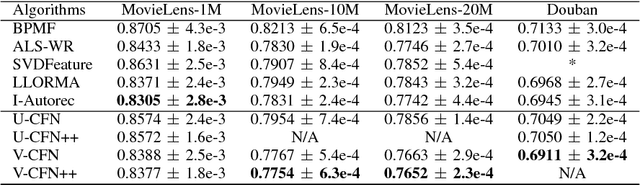
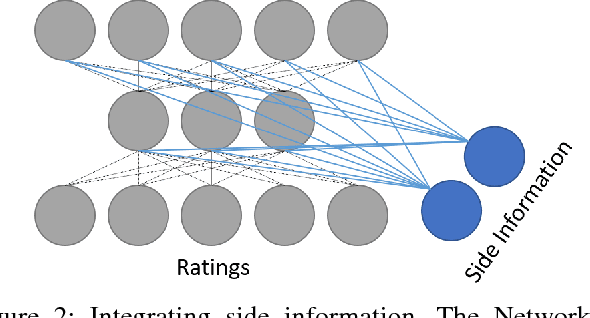

Collaborative Filtering aims at exploiting the feedback of users to provide personalised recommendations. Such algorithms look for latent variables in a large sparse matrix of ratings. They can be enhanced by adding side information to tackle the well-known cold start problem. While Neu-ral Networks have tremendous success in image and speech recognition, they have received less attention in Collaborative Filtering. This is all the more surprising that Neural Networks are able to discover latent variables in large and heterogeneous datasets. In this paper, we introduce a Collaborative Filtering Neural network architecture aka CFN which computes a non-linear Matrix Factorization from sparse rating inputs and side information. We show experimentally on the MovieLens and Douban dataset that CFN outper-forms the state of the art and benefits from side information. We provide an implementation of the algorithm as a reusable plugin for Torch, a popular Neural Network framework.
AUC Optimisation and Collaborative Filtering
Aug 25, 2015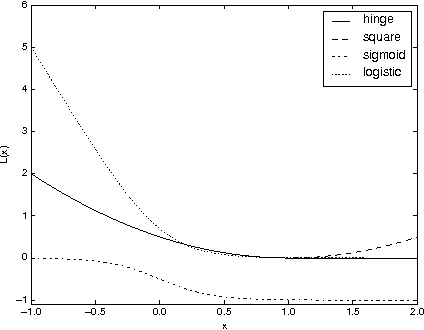

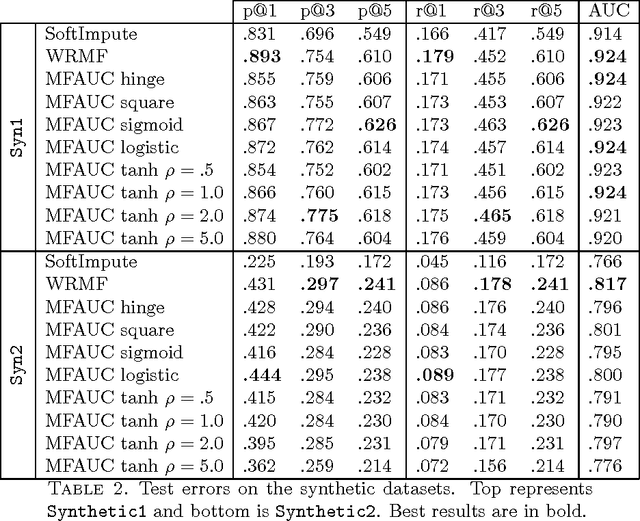
In recommendation systems, one is interested in the ranking of the predicted items as opposed to other losses such as the mean squared error. Although a variety of ways to evaluate rankings exist in the literature, here we focus on the Area Under the ROC Curve (AUC) as it widely used and has a strong theoretical underpinning. In practical recommendation, only items at the top of the ranked list are presented to the users. With this in mind, we propose a class of objective functions over matrix factorisations which primarily represent a smooth surrogate for the real AUC, and in a special case we show how to prioritise the top of the list. The objectives are differentiable and optimised through a carefully designed stochastic gradient-descent-based algorithm which scales linearly with the size of the data. In the special case of square loss we show how to improve computational complexity by leveraging previously computed measures. To understand theoretically the underlying matrix factorisation approaches we study both the consistency of the loss functions with respect to AUC, and generalisation using Rademacher theory. The resulting generalisation analysis gives strong motivation for the optimisation under study. Finally, we provide computation results as to the efficacy of the proposed method using synthetic and real data.