 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Efficient Change Detection in LLM APIs
Feb 11, 2026Remote change detection in LLMs is a difficult problem. Existing methods are either too expensive for deployment at scale, or require initial white-box access to model weights or grey-box access to log probabilities. We aim to achieve both low cost and strict black-box operation, observing only output tokens. Our approach hinges on specific inputs we call Border Inputs, for which there exists more than one output top token. From a statistical perspective, optimal change detection depends on the model's Jacobian and the Fisher information of the output distribution. Analyzing these quantities in low-temperature regimes shows that border inputs enable powerful change detection tests. Building on this insight, we propose the Black-Box Border Input Tracking (B3IT) scheme. Extensive in-vivo and in-vitro experiments show that border inputs are easily found for non-reasoning tested endpoints, and achieve performance on par with the best available grey-box approaches. B3IT reduces costs by $30\times$ compared to existing methods, while operating in a strict black-box setting.
Mosaic Learning: A Framework for Decentralized Learning with Model Fragmentation
Feb 04, 2026Decentralized learning (DL) enables collaborative machine learning (ML) without a central server, making it suitable for settings where training data cannot be centrally hosted. We introduce Mosaic Learning, a DL framework that decomposes models into fragments and disseminates them independently across the network. Fragmentation reduces redundant communication across correlated parameters and enables more diverse information propagation without increasing communication cost. We theoretically show that Mosaic Learning (i) shows state-of-the-art worst-case convergence rate, and (ii) leverages parameter correlation in an ML model, improving contraction by reducing the highest eigenvalue of a simplified system. We empirically evaluate Mosaic Learning on four learning tasks and observe up to 12 percentage points higher node-level test accuracy compared to epidemic learning (EL), a state-of-the-art baseline. In summary, Mosaic Learning improves DL performance without sacrificing its utility or efficiency, and positions itself as a new DL standard.
ByzFL: Research Framework for Robust Federated Learning
May 30, 2025We present ByzFL, an open-source Python library for developing and benchmarking robust federated learning (FL) algorithms. ByzFL provides a unified and extensible framework that includes implementations of state-of-the-art robust aggregators, a suite of configurable attacks, and tools for simulating a variety of FL scenarios, including heterogeneous data distributions, multiple training algorithms, and adversarial threat models. The library enables systematic experimentation via a single JSON-based configuration file and includes built-in utilities for result visualization. Compatible with PyTorch tensors and NumPy arrays, ByzFL is designed to facilitate reproducible research and rapid prototyping of robust FL solutions. ByzFL is available at https://byzfl.epfl.ch/, with source code hosted on GitHub: https://github.com/LPD-EPFL/byzfl.
Queries, Representation & Detection: The Next 100 Model Fingerprinting Schemes
Dec 17, 2024The deployment of machine learning models in operational contexts represents a significant investment for any organisation. Consequently, the risk of these models being misappropriated by competitors needs to be addressed. In recent years, numerous proposals have been put forth to detect instances of model stealing. However, these proposals operate under implicit and disparate data and model access assumptions; as a consequence, it remains unclear how they can be effectively compared to one another. Our evaluation shows that a simple baseline that we introduce performs on par with existing state-of-the-art fingerprints, which, on the other hand, are much more complex. To uncover the reasons behind this intriguing result, this paper introduces a systematic approach to both the creation of model fingerprinting schemes and their evaluation benchmarks. By dividing model fingerprinting into three core components -- Query, Representation and Detection (QuRD) -- we are able to identify $\sim100$ previously unexplored QuRD combinations and gain insights into their performance. Finally, we introduce a set of metrics to compare and guide the creation of more representative model stealing detection benchmarks. Our approach reveals the need for more challenging benchmarks and a sound comparison with baselines. To foster the creation of new fingerprinting schemes and benchmarks, we open-source our fingerprinting toolbox.
Low-Cost Privacy-Aware Decentralized Learning
Mar 18, 2024
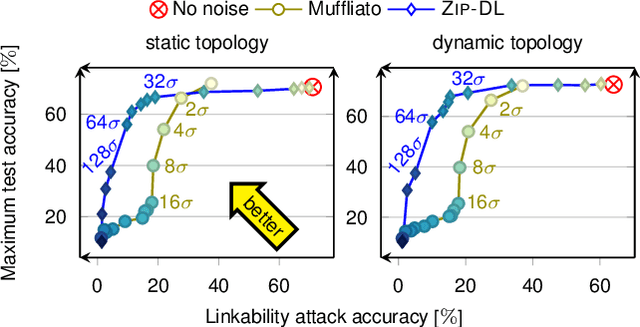
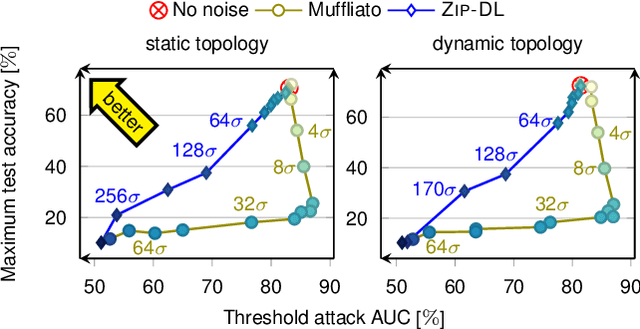
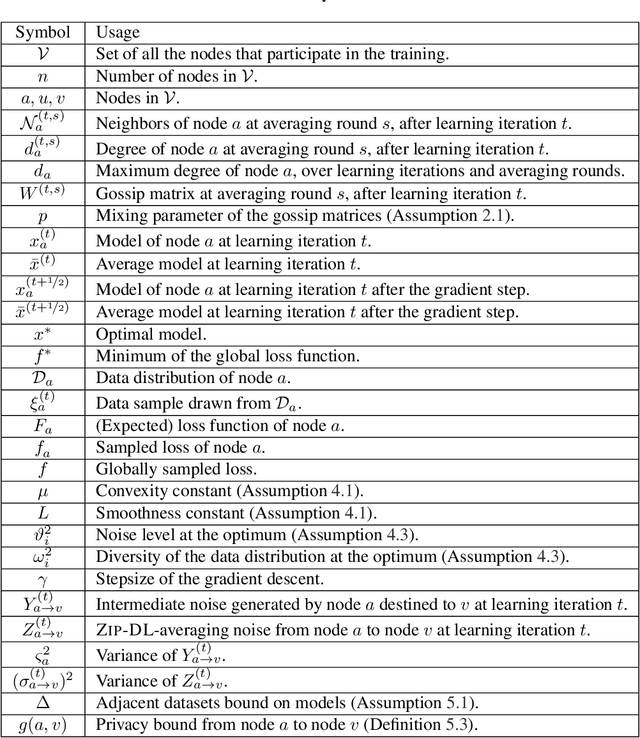
This paper introduces ZIP-DL, a novel privacy-aware decentralized learning (DL) algorithm that relies on adding correlated noise to each model update during the model training process. This technique ensures that the added noise almost neutralizes itself during the aggregation process due to its correlation, thus minimizing the impact on model accuracy. In addition, ZIP-DL does not require multiple communication rounds for noise cancellation, addressing the common trade-off between privacy protection and communication overhead. We provide theoretical guarantees for both convergence speed and privacy guarantees, thereby making ZIP-DL applicable to practical scenarios. Our extensive experimental study shows that ZIP-DL achieves the best trade-off between vulnerability and accuracy. In particular, ZIP-DL (i) reduces the effectiveness of a linkability attack by up to 52 points compared to baseline DL, and (ii) achieves up to 37 more accuracy points for the same vulnerability under membership inference attacks against a privacy-preserving competitor
The Graph Neural Networking Challenge: A Worldwide Competition for Education in AI/ML for Networks
Jul 26, 2021
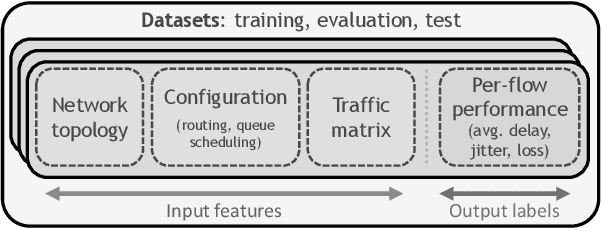

During the last decade, Machine Learning (ML) has increasingly become a hot topic in the field of Computer Networks and is expected to be gradually adopted for a plethora of control, monitoring and management tasks in real-world deployments. This poses the need to count on new generations of students, researchers and practitioners with a solid background in ML applied to networks. During 2020, the International Telecommunication Union (ITU) has organized the "ITU AI/ML in 5G challenge'', an open global competition that has introduced to a broad audience some of the current main challenges in ML for networks. This large-scale initiative has gathered 23 different challenges proposed by network operators, equipment manufacturers and academia, and has attracted a total of 1300+ participants from 60+ countries. This paper narrates our experience organizing one of the proposed challenges: the "Graph Neural Networking Challenge 2020''. We describe the problem presented to participants, the tools and resources provided, some organization aspects and participation statistics, an outline of the top-3 awarded solutions, and a summary with some lessons learned during all this journey. As a result, this challenge leaves a curated set of educational resources openly available to anyone interested in the topic.
Cluster-and-Conquer: When Randomness Meets Graph Locality
Oct 22, 2020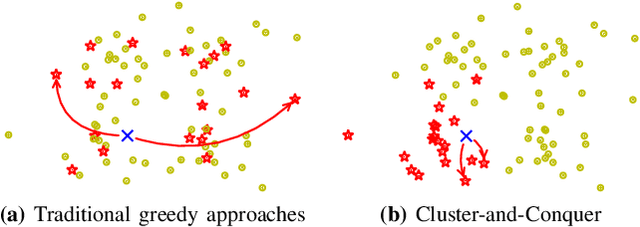
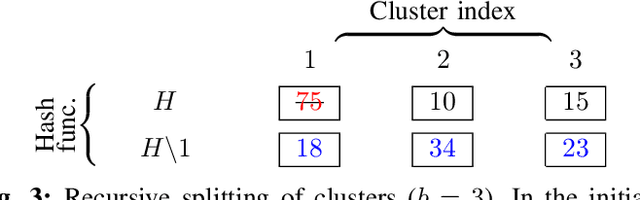

K-Nearest-Neighbors (KNN) graphs are central to many emblematic data mining and machine-learning applications. Some of the most efficient KNN graph algorithms are incremental and local: they start from a random graph, which they incrementally improve by traversing neighbors-of-neighbors links. Paradoxically, this random start is also one of the key weaknesses of these algorithms: nodes are initially connected to dissimilar neighbors, that lie far away according to the similarity metric. As a result, incremental algorithms must first laboriously explore spurious potential neighbors before they can identify similar nodes, and start converging. In this paper, we remove this drawback with Cluster-and-Conquer (C 2 for short). Cluster-and-Conquer boosts the starting configuration of greedy algorithms thanks to a novel lightweight clustering mechanism, dubbed FastRandomHash. FastRandomHash leverages random-ness and recursion to pre-cluster similar nodes at a very low cost. Our extensive evaluation on real datasets shows that Cluster-and-Conquer significantly outperforms existing approaches, including LSH, yielding speed-ups of up to x4.42 while incurring only a negligible loss in terms of KNN quality.
Spores: Stateless Predictive Onion Routing for E-Squads
Jul 02, 2020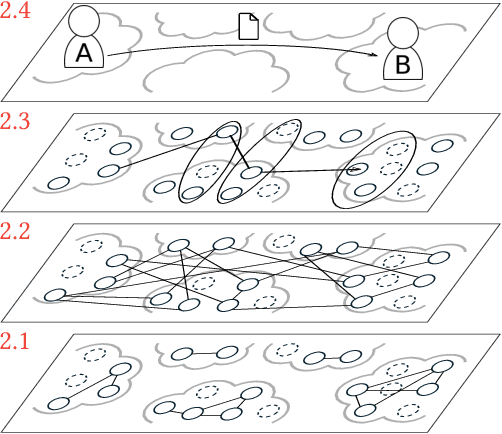
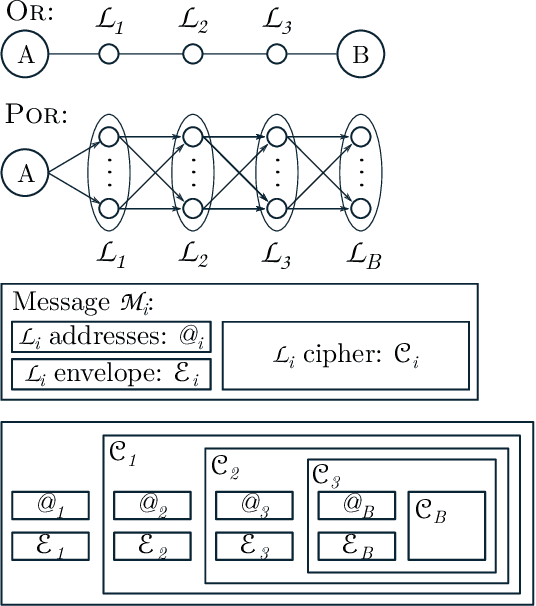
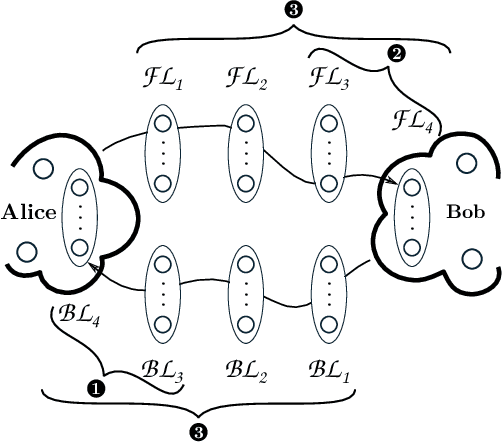
Mass surveillance of the population by state agencies and corporate parties is now a well-known fact. Journalists and whistle-blowers still lack means to circumvent global spying for the sake of their investigations. With Spores, we propose a way for journalists and their sources to plan a posteriori file exchanges when they physically meet. We leverage on the multiplication of personal devices per capita to provide a lightweight, robust and fully anonymous decentralised file transfer protocol between users. Spores hinges on our novel concept of e-squads: one's personal devices, rendered intelligent by gossip communication protocols, can provide private and dependable services to their user. People's e-squads are federated into a novel onion routing network, able to withstand the inherent unreliability of personal appliances while providing reliable routing. Spores' performances are competitive, and its privacy properties of the communication outperform state of the art onion routing strategies.
DiagNet: towards a generic, Internet-scale root cause analysis solution
Apr 07, 2020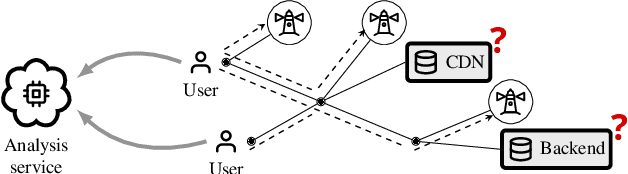
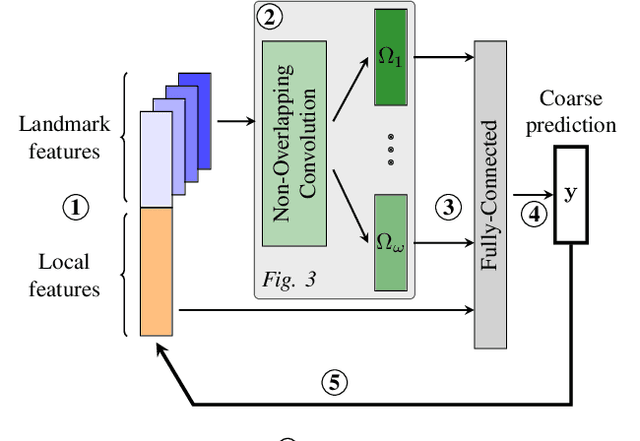
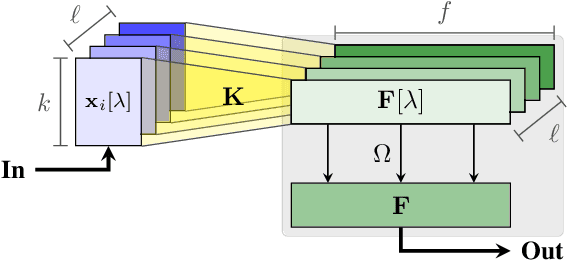
Diagnosing problems in Internet-scale services remains particularly difficult and costly for both content providers and ISPs. Because the Internet is decentralized, the cause of such problems might lie anywhere between an end-user's device and the service datacenters. Further, the set of possible problems and causes is not known in advance, making it impossible in practice to train a classifier with all combinations of problems, causes and locations. In this paper, we explore how different machine learning techniques can be used for Internet-scale root cause analysis using measurements taken from end-user devices. We show how to build generic models that (i) are agnostic to the underlying network topology, (ii) do not require to define the full set of possible causes during training, and (iii) can be quickly adapted to diagnose new services. Our solution, DiagNet, adapts concepts from image processing research to handle network and system metrics. We evaluate DiagNet with a multi-cloud deployment of online services with injected faults and emulated clients with automated browsers. We demonstrate promising root cause analysis capabilities, with a recall of 73.9% including causes only being introduced at inference time.