 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueries, Representation & Detection: The Next 100 Model Fingerprinting Schemes
Dec 17, 2024The deployment of machine learning models in operational contexts represents a significant investment for any organisation. Consequently, the risk of these models being misappropriated by competitors needs to be addressed. In recent years, numerous proposals have been put forth to detect instances of model stealing. However, these proposals operate under implicit and disparate data and model access assumptions; as a consequence, it remains unclear how they can be effectively compared to one another. Our evaluation shows that a simple baseline that we introduce performs on par with existing state-of-the-art fingerprints, which, on the other hand, are much more complex. To uncover the reasons behind this intriguing result, this paper introduces a systematic approach to both the creation of model fingerprinting schemes and their evaluation benchmarks. By dividing model fingerprinting into three core components -- Query, Representation and Detection (QuRD) -- we are able to identify $\sim100$ previously unexplored QuRD combinations and gain insights into their performance. Finally, we introduce a set of metrics to compare and guide the creation of more representative model stealing detection benchmarks. Our approach reveals the need for more challenging benchmarks and a sound comparison with baselines. To foster the creation of new fingerprinting schemes and benchmarks, we open-source our fingerprinting toolbox.
Algorithmic audits of algorithms, and the law
Feb 15, 2022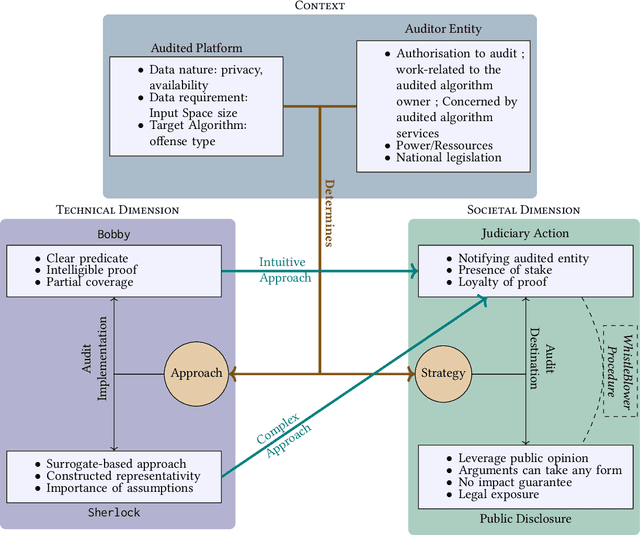
Algorithmic decision making is now widespread, ranging from health care allocation to more common actions such as recommendation or information ranking. The aim to audit these algorithms has grown alongside. In this paper, we focus on external audits that are conducted by interacting with the user side of the target algorithm, hence considered as a black box. Yet, the legal framework in which these audits take place is mostly ambiguous to researchers developing them: on the one hand, the legal value of the audit outcome is uncertain; on the other hand the auditors' rights and obligations are unclear. The contribution of this paper is to articulate two canonical audit forms to law, to shed light on these aspects: 1) the first audit form (we coin the Bobby audit form) checks a predicate against the algorithm, while the second (Sherlock) is more loose and opens up to multiple investigations. We find that: Bobby audits are more amenable to prosecution, yet are delicate as operating on real user data. This can lead to reject by a court (notion of admissibility). Sherlock audits craft data for their operation, most notably to build surrogates of the audited algorithm. It is mostly used for acts for whistleblowing, as even if accepted as a proof, the evidential value will be low in practice. 2) these two forms require the prior respect of a proper right to audit, granted by law or by the platform being audited; otherwise the auditor will be also prone to prosecutions regardless of the audit outcome. This article thus highlights the relation of current audits with law, in order to structure the growing field of algorithm auditing.
TamperNN: Efficient Tampering Detection of Deployed Neural Nets
Mar 01, 2019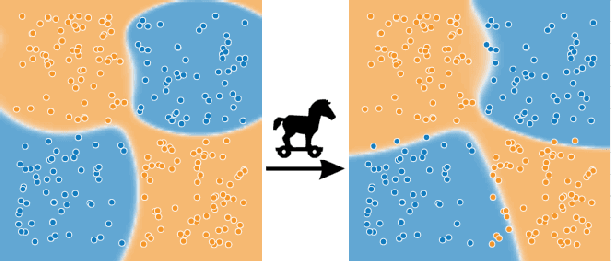

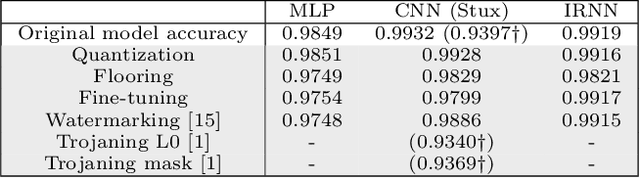
Neural networks are powering the deployment of embedded devices and Internet of Things. Applications range from personal assistants to critical ones such as self-driving cars. It has been shown recently that models obtained from neural nets can be trojaned ; an attacker can then trigger an arbitrary model behavior facing crafted inputs. This has a critical impact on the security and reliability of those deployed devices. We introduce novel algorithms to detect the tampering with deployed models, classifiers in particular. In the remote interaction setup we consider, the proposed strategy is to identify markers of the model input space that are likely to change class if the model is attacked, allowing a user to detect a possible tampering. This setup makes our proposal compatible with a wide rage of scenarios, such as embedded models, or models exposed through prediction APIs. We experiment those tampering detection algorithms on the canonical MNIST dataset, over three different types of neural nets, and facing five different attacks (trojaning, quantization, fine-tuning, compression and watermarking). We then validate over five large models (VGG16, VGG19, ResNet, MobileNet, DenseNet) with a state of the art dataset (VGGFace2), and report results demonstrating the possibility of an efficient detection of model tampering.