 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueries, Representation & Detection: The Next 100 Model Fingerprinting Schemes
Dec 17, 2024The deployment of machine learning models in operational contexts represents a significant investment for any organisation. Consequently, the risk of these models being misappropriated by competitors needs to be addressed. In recent years, numerous proposals have been put forth to detect instances of model stealing. However, these proposals operate under implicit and disparate data and model access assumptions; as a consequence, it remains unclear how they can be effectively compared to one another. Our evaluation shows that a simple baseline that we introduce performs on par with existing state-of-the-art fingerprints, which, on the other hand, are much more complex. To uncover the reasons behind this intriguing result, this paper introduces a systematic approach to both the creation of model fingerprinting schemes and their evaluation benchmarks. By dividing model fingerprinting into three core components -- Query, Representation and Detection (QuRD) -- we are able to identify $\sim100$ previously unexplored QuRD combinations and gain insights into their performance. Finally, we introduce a set of metrics to compare and guide the creation of more representative model stealing detection benchmarks. Our approach reveals the need for more challenging benchmarks and a sound comparison with baselines. To foster the creation of new fingerprinting schemes and benchmarks, we open-source our fingerprinting toolbox.
The 20 questions game to distinguish large language models
Sep 16, 2024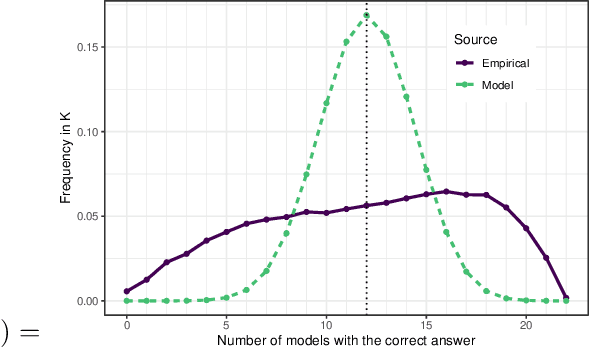
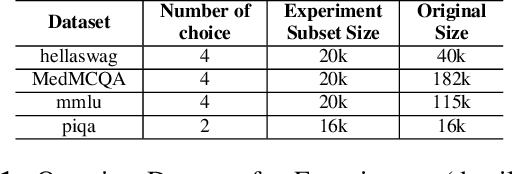
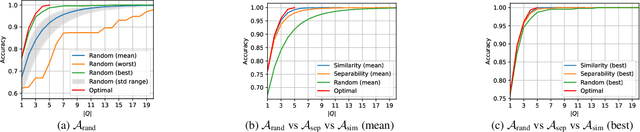
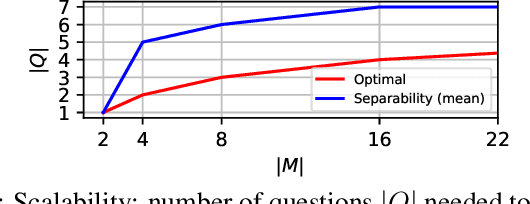
In a parallel with the 20 questions game, we present a method to determine whether two large language models (LLMs), placed in a black-box context, are the same or not. The goal is to use a small set of (benign) binary questions, typically under 20. We formalize the problem and first establish a baseline using a random selection of questions from known benchmark datasets, achieving an accuracy of nearly 100% within 20 questions. After showing optimal bounds for this problem, we introduce two effective questioning heuristics able to discriminate 22 LLMs by using half as many questions for the same task. These methods offer significant advantages in terms of stealth and are thus of interest to auditors or copyright owners facing suspicions of model leaks.
Under manipulations, are some AI models harder to audit?
Feb 14, 2024Auditors need robust methods to assess the compliance of web platforms with the law. However, since they hardly ever have access to the algorithm, implementation, or training data used by a platform, the problem is harder than a simple metric estimation. Within the recent framework of manipulation-proof auditing, we study in this paper the feasibility of robust audits in realistic settings, in which models exhibit large capacities. We first prove a constraining result: if a web platform uses models that may fit any data, no audit strategy -- whether active or not -- can outperform random sampling when estimating properties such as demographic parity. To better understand the conditions under which state-of-the-art auditing techniques may remain competitive, we then relate the manipulability of audits to the capacity of the targeted models, using the Rademacher complexity. We empirically validate these results on popular models of increasing capacities, thus confirming experimentally that large-capacity models, which are commonly used in practice, are particularly hard to audit robustly. These results refine the limits of the auditing problem, and open up enticing questions on the connection between model capacity and the ability of platforms to manipulate audit attempts.