 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust ML Auditing using Prior Knowledge
May 07, 2025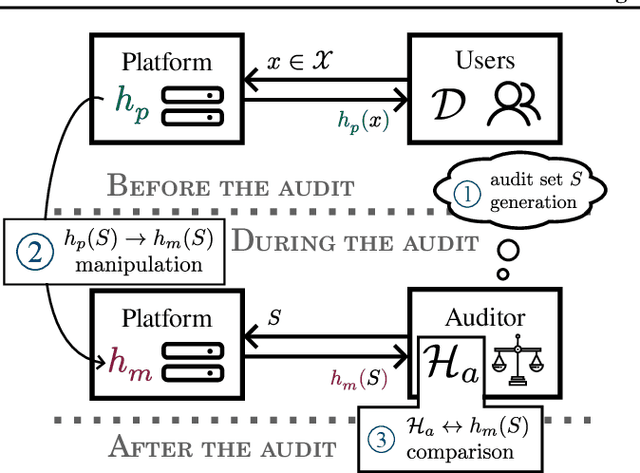

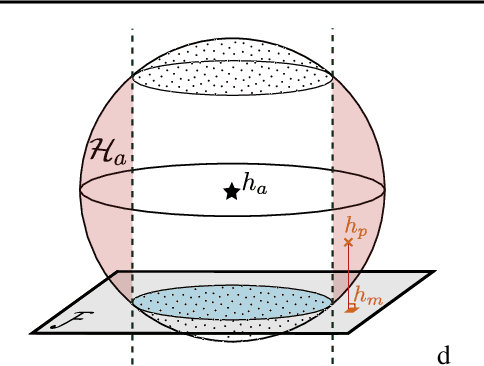
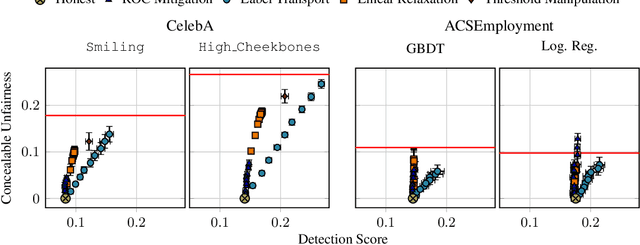
The rapid adoption of ML decision-making systems across products and services has led to a set of regulations on how such systems should behave and be built. Among all the technical challenges to enforcing these regulations, one crucial, yet under-explored problem is the risk of manipulation while these systems are being audited for fairness. This manipulation occurs when a platform deliberately alters its answers to a regulator to pass an audit without modifying its answers to other users. In this paper, we introduce a novel approach to manipulation-proof auditing by taking into account the auditor's prior knowledge of the task solved by the platform. We first demonstrate that regulators must not rely on public priors (e.g. a public dataset), as platforms could easily fool the auditor in such cases. We then formally establish the conditions under which an auditor can prevent audit manipulations using prior knowledge about the ground truth. Finally, our experiments with two standard datasets exemplify the maximum level of unfairness a platform can hide before being detected as malicious. Our formalization and generalization of manipulation-proof auditing with a prior opens up new research directions for more robust fairness audits.
P2NIA: Privacy-Preserving Non-Iterative Auditing
Apr 01, 2025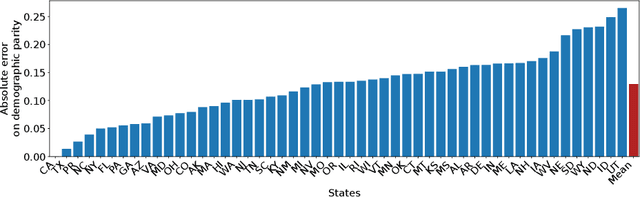
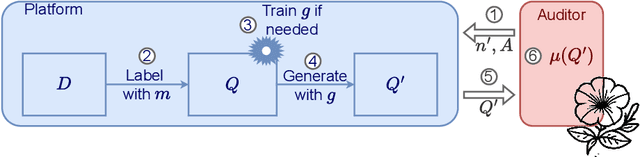
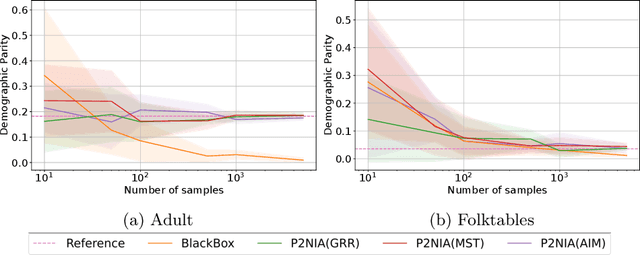
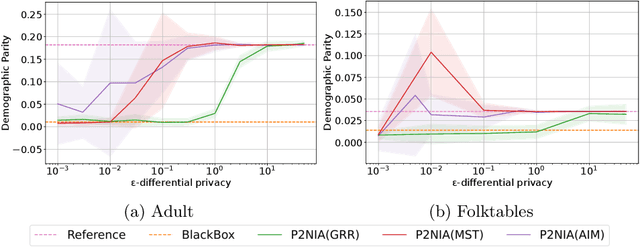
The emergence of AI legislation has increased the need to assess the ethical compliance of high-risk AI systems. Traditional auditing methods rely on platforms' application programming interfaces (APIs), where responses to queries are examined through the lens of fairness requirements. However, such approaches put a significant burden on platforms, as they are forced to maintain APIs while ensuring privacy, facing the possibility of data leaks. This lack of proper collaboration between the two parties, in turn, causes a significant challenge to the auditor, who is subject to estimation bias as they are unaware of the data distribution of the platform. To address these two issues, we present P2NIA, a novel auditing scheme that proposes a mutually beneficial collaboration for both the auditor and the platform. Extensive experiments demonstrate P2NIA's effectiveness in addressing both issues. In summary, our work introduces a privacy-preserving and non-iterative audit scheme that enhances fairness assessments using synthetic or local data, avoiding the challenges associated with traditional API-based audits.
Queries, Representation & Detection: The Next 100 Model Fingerprinting Schemes
Dec 17, 2024The deployment of machine learning models in operational contexts represents a significant investment for any organisation. Consequently, the risk of these models being misappropriated by competitors needs to be addressed. In recent years, numerous proposals have been put forth to detect instances of model stealing. However, these proposals operate under implicit and disparate data and model access assumptions; as a consequence, it remains unclear how they can be effectively compared to one another. Our evaluation shows that a simple baseline that we introduce performs on par with existing state-of-the-art fingerprints, which, on the other hand, are much more complex. To uncover the reasons behind this intriguing result, this paper introduces a systematic approach to both the creation of model fingerprinting schemes and their evaluation benchmarks. By dividing model fingerprinting into three core components -- Query, Representation and Detection (QuRD) -- we are able to identify $\sim100$ previously unexplored QuRD combinations and gain insights into their performance. Finally, we introduce a set of metrics to compare and guide the creation of more representative model stealing detection benchmarks. Our approach reveals the need for more challenging benchmarks and a sound comparison with baselines. To foster the creation of new fingerprinting schemes and benchmarks, we open-source our fingerprinting toolbox.
The 20 questions game to distinguish large language models
Sep 16, 2024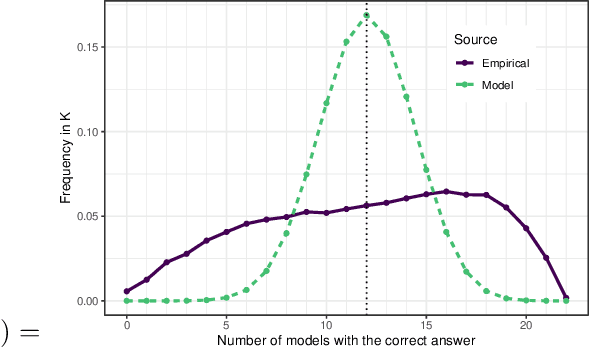
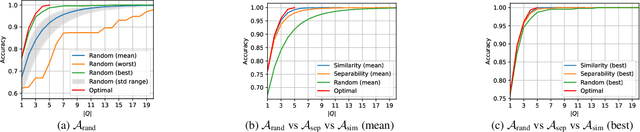
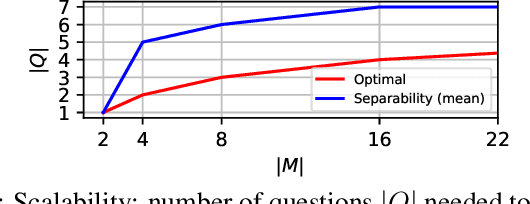
In a parallel with the 20 questions game, we present a method to determine whether two large language models (LLMs), placed in a black-box context, are the same or not. The goal is to use a small set of (benign) binary questions, typically under 20. We formalize the problem and first establish a baseline using a random selection of questions from known benchmark datasets, achieving an accuracy of nearly 100% within 20 questions. After showing optimal bounds for this problem, we introduce two effective questioning heuristics able to discriminate 22 LLMs by using half as many questions for the same task. These methods offer significant advantages in terms of stealth and are thus of interest to auditors or copyright owners facing suspicions of model leaks.
LLMs hallucinate graphs too: a structural perspective
Aug 30, 2024
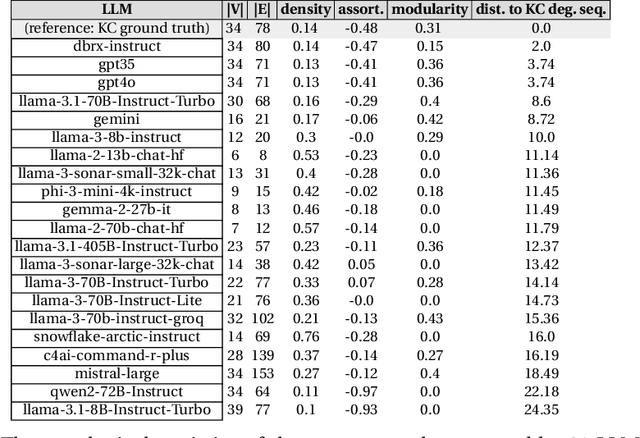

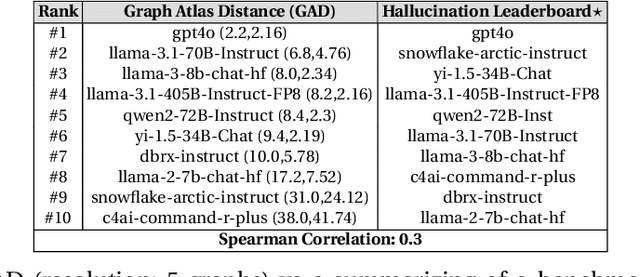
It is known that LLMs do hallucinate, that is, they return incorrect information as facts. In this paper, we introduce the possibility to study these hallucinations under a structured form: graphs. Hallucinations in this context are incorrect outputs when prompted for well known graphs from the literature (e.g. Karate club, Les Mis\'erables, graph atlas). These hallucinated graphs have the advantage of being much richer than the factual accuracy -- or not -- of a fact; this paper thus argues that such rich hallucinations can be used to characterize the outputs of LLMs. Our first contribution observes the diversity of topological hallucinations from major modern LLMs. Our second contribution is the proposal of a metric for the amplitude of such hallucinations: the Graph Atlas Distance, that is the average graph edit distance from several graphs in the graph atlas set. We compare this metric to the Hallucination Leaderboard, a hallucination rank that leverages 10,000 times more prompts to obtain its ranking.
Under manipulations, are some AI models harder to audit?
Feb 14, 2024Auditors need robust methods to assess the compliance of web platforms with the law. However, since they hardly ever have access to the algorithm, implementation, or training data used by a platform, the problem is harder than a simple metric estimation. Within the recent framework of manipulation-proof auditing, we study in this paper the feasibility of robust audits in realistic settings, in which models exhibit large capacities. We first prove a constraining result: if a web platform uses models that may fit any data, no audit strategy -- whether active or not -- can outperform random sampling when estimating properties such as demographic parity. To better understand the conditions under which state-of-the-art auditing techniques may remain competitive, we then relate the manipulability of audits to the capacity of the targeted models, using the Rademacher complexity. We empirically validate these results on popular models of increasing capacities, thus confirming experimentally that large-capacity models, which are commonly used in practice, are particularly hard to audit robustly. These results refine the limits of the auditing problem, and open up enticing questions on the connection between model capacity and the ability of platforms to manipulate audit attempts.
Fairness Auditing with Multi-Agent Collaboration
Feb 13, 2024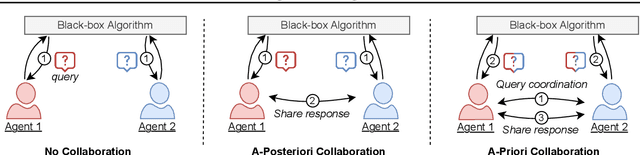
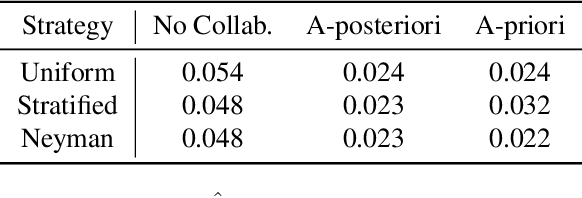
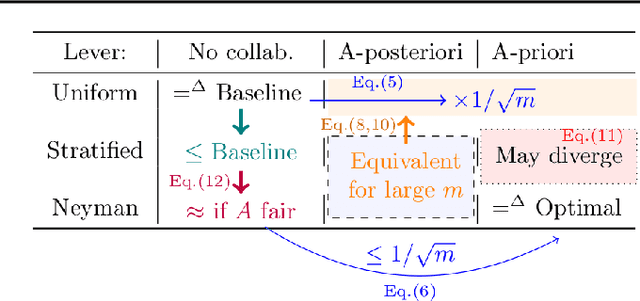
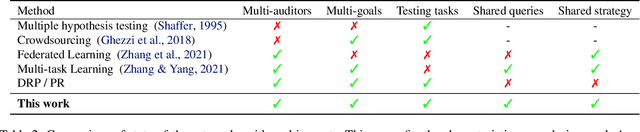
Existing work in fairness audits assumes that agents operate independently. In this paper, we consider the case of multiple agents auditing the same platform for different tasks. Agents have two levers: their collaboration strategy, with or without coordination beforehand, and their sampling method. We theoretically study their interplay when agents operate independently or collaborate. We prove that, surprisingly, coordination can sometimes be detrimental to audit accuracy, whereas uncoordinated collaboration generally yields good results. Experimentation on real-world datasets confirms this observation, as the audit accuracy of uncoordinated collaboration matches that of collaborative optimal sampling.
On the relevance of APIs facing fairwashed audits
May 23, 2023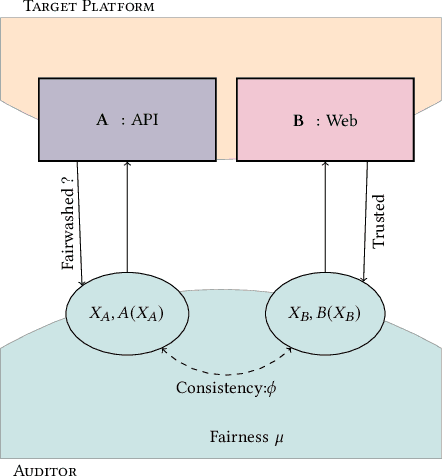
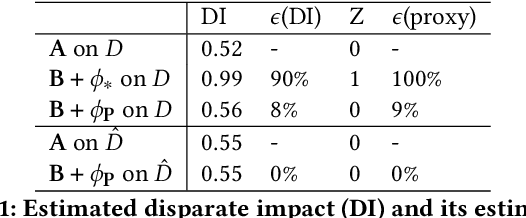
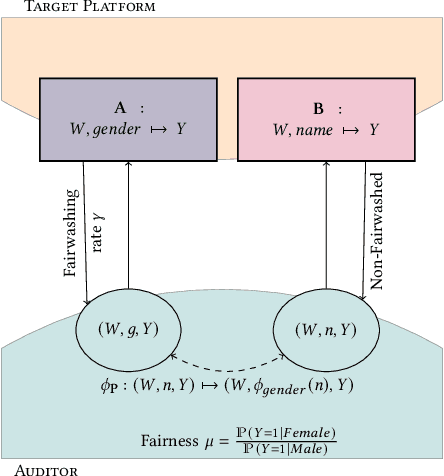
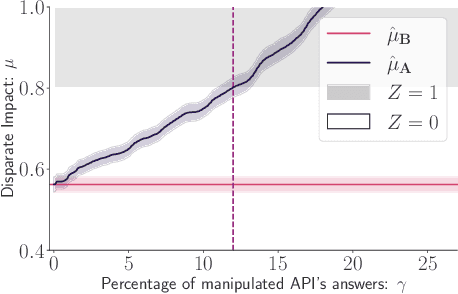
Recent legislation required AI platforms to provide APIs for regulators to assess their compliance with the law. Research has nevertheless shown that platforms can manipulate their API answers through fairwashing. Facing this threat for reliable auditing, this paper studies the benefits of the joint use of platform scraping and of APIs. In this setup, we elaborate on the use of scraping to detect manipulated answers: since fairwashing only manipulates API answers, exploiting scraps may reveal a manipulation. To abstract the wide range of specific API-scrap situations, we introduce a notion of proxy that captures the consistency an auditor might expect between both data sources. If the regulator has a good proxy of the consistency, then she can easily detect manipulation and even bypass the API to conduct her audit. On the other hand, without a good proxy, relying on the API is necessary, and the auditor cannot defend against fairwashing. We then simulate practical scenarios in which the auditor may mostly rely on the API to conveniently conduct the audit task, while maintaining her chances to detect a potential manipulation. To highlight the tension between the audit task and the API fairwashing detection task, we identify Pareto-optimal strategies in a practical audit scenario. We believe this research sets the stage for reliable audits in practical and manipulation-prone setups.
FBI: Fingerprinting models with Benign Inputs
Aug 05, 2022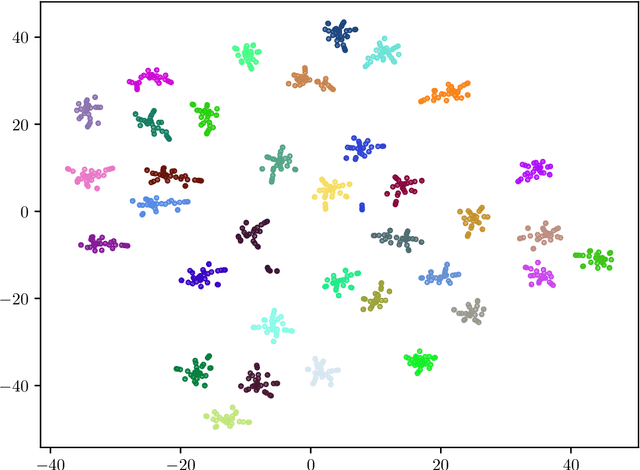
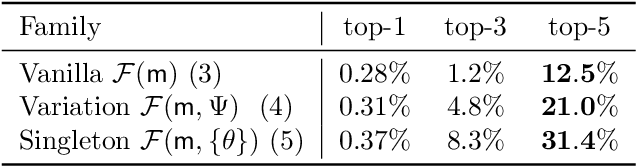

Recent advances in the fingerprinting of deep neural networks detect instances of models, placed in a black-box interaction scheme. Inputs used by the fingerprinting protocols are specifically crafted for each precise model to be checked for. While efficient in such a scenario, this nevertheless results in a lack of guarantee after a mere modification (like retraining, quantization) of a model. This paper tackles the challenges to propose i) fingerprinting schemes that are resilient to significant modifications of the models, by generalizing to the notion of model families and their variants, ii) an extension of the fingerprinting task encompassing scenarios where one wants to fingerprint not only a precise model (previously referred to as a detection task) but also to identify which model family is in the black-box (identification task). We achieve both goals by demonstrating that benign inputs, that are unmodified images, for instance, are sufficient material for both tasks. We leverage an information-theoretic scheme for the identification task. We devise a greedy discrimination algorithm for the detection task. Both approaches are experimentally validated over an unprecedented set of more than 1,000 networks.
Randomized Smoothing under Attack: How Good is it in Pratice?
Apr 28, 2022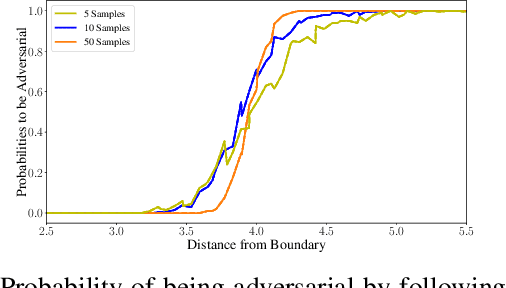

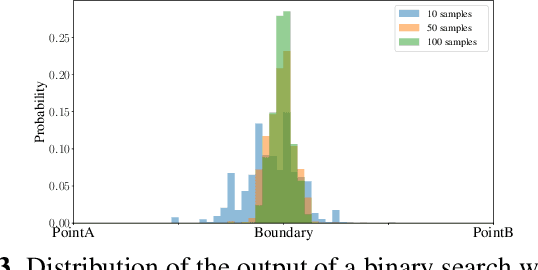
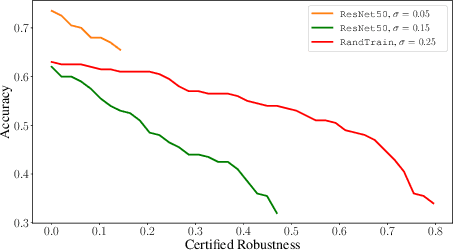
Randomized smoothing is a recent and celebrated solution to certify the robustness of any classifier. While it indeed provides a theoretical robustness against adversarial attacks, the dimensionality of current classifiers necessarily imposes Monte Carlo approaches for its application in practice. This paper questions the effectiveness of randomized smoothing as a defense, against state of the art black-box attacks. This is a novel perspective, as previous research works considered the certification as an unquestionable guarantee. We first formally highlight the mismatch between a theoretical certification and the practice of attacks on classifiers. We then perform attacks on randomized smoothing as a defense. Our main observation is that there is a major mismatch in the settings of the RS for obtaining high certified robustness or when defeating black box attacks while preserving the classifier accuracy.