 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating the Accuracy-Size Trade-Off with Flexible Model Merging
May 29, 2025Model merging has emerged as an efficient method to combine multiple single-task fine-tuned models. The merged model can enjoy multi-task capabilities without expensive training. While promising, merging into a single model often suffers from an accuracy gap with respect to individual fine-tuned models. On the other hand, deploying all individual fine-tuned models incurs high costs. We propose FlexMerge, a novel data-free model merging framework to flexibly generate merged models of varying sizes, spanning the spectrum from a single merged model to retaining all individual fine-tuned models. FlexMerge treats fine-tuned models as collections of sequential blocks and progressively merges them using any existing data-free merging method, halting at a desired size. We systematically explore the accuracy-size trade-off exhibited by different merging algorithms in combination with FlexMerge. Extensive experiments on vision and NLP benchmarks, with up to 30 tasks, reveal that even modestly larger merged models can provide substantial accuracy improvements over a single model. By offering fine-grained control over fused model size, FlexMerge provides a flexible, data-free, and high-performance solution for diverse deployment scenarios.
Robust ML Auditing using Prior Knowledge
May 07, 2025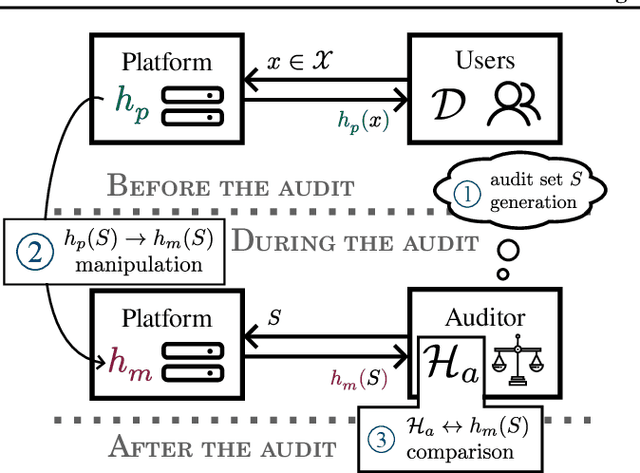

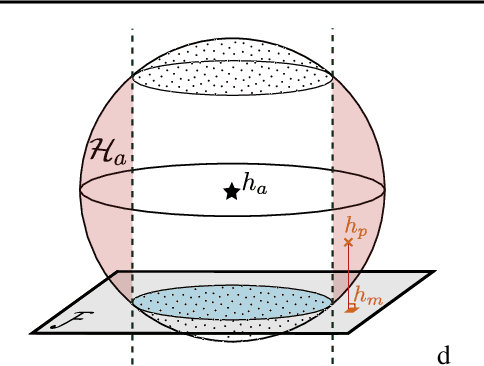
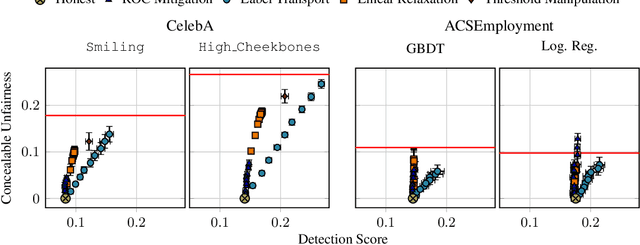
The rapid adoption of ML decision-making systems across products and services has led to a set of regulations on how such systems should behave and be built. Among all the technical challenges to enforcing these regulations, one crucial, yet under-explored problem is the risk of manipulation while these systems are being audited for fairness. This manipulation occurs when a platform deliberately alters its answers to a regulator to pass an audit without modifying its answers to other users. In this paper, we introduce a novel approach to manipulation-proof auditing by taking into account the auditor's prior knowledge of the task solved by the platform. We first demonstrate that regulators must not rely on public priors (e.g. a public dataset), as platforms could easily fool the auditor in such cases. We then formally establish the conditions under which an auditor can prevent audit manipulations using prior knowledge about the ground truth. Finally, our experiments with two standard datasets exemplify the maximum level of unfairness a platform can hide before being detected as malicious. Our formalization and generalization of manipulation-proof auditing with a prior opens up new research directions for more robust fairness audits.
Accelerating MoE Model Inference with Expert Sharding
Mar 11, 2025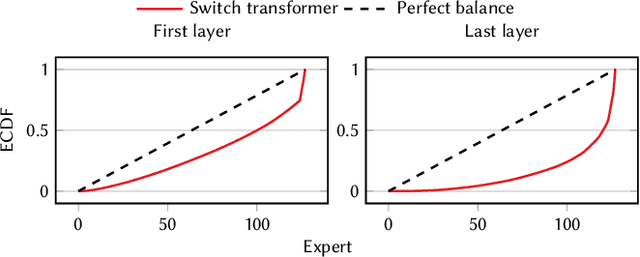
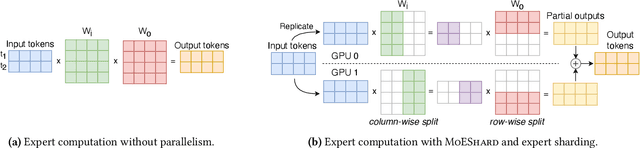
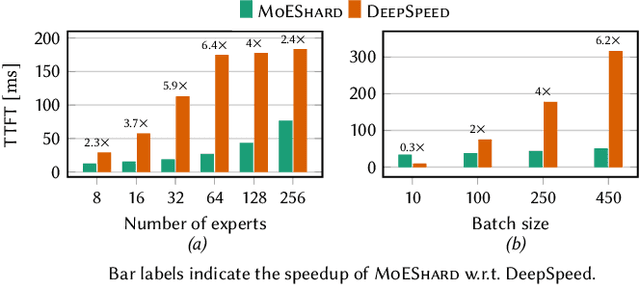
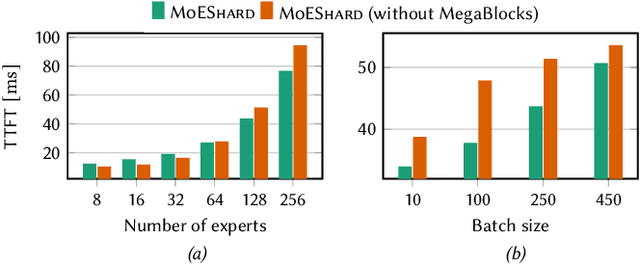
Mixture of experts (MoE) models achieve state-of-the-art results in language modeling but suffer from inefficient hardware utilization due to imbalanced token routing and communication overhead. While prior work has focused on optimizing MoE training and decoder architectures, inference for encoder-based MoE models in a multi-GPU with expert parallelism setting remains underexplored. We introduce MoEShard, an inference system that achieves perfect load balancing through tensor sharding of MoE experts. Unlike existing approaches that rely on heuristic capacity factors or drop tokens, MoEShard evenly distributes computation across GPUs and ensures full token retention, maximizing utilization regardless of routing skewness. We achieve this through a strategic row- and column-wise decomposition of expert matrices. This reduces idle time and avoids bottlenecks caused by imbalanced expert assignments. Furthermore, MoEShard minimizes kernel launches by fusing decomposed expert computations, significantly improving throughput. We evaluate MoEShard against DeepSpeed on encoder-based architectures, demonstrating speedups of up to 6.4$\times$ in time to first token (TTFT). Our results show that tensor sharding, when properly applied to experts, is a viable and effective strategy for efficient MoE inference.
Secure Aggregation Meets Sparsification in Decentralized Learning
May 14, 2024Decentralized learning (DL) faces increased vulnerability to privacy breaches due to sophisticated attacks on machine learning (ML) models. Secure aggregation is a computationally efficient cryptographic technique that enables multiple parties to compute an aggregate of their private data while keeping their individual inputs concealed from each other and from any central aggregator. To enhance communication efficiency in DL, sparsification techniques are used, selectively sharing only the most crucial parameters or gradients in a model, thereby maintaining efficiency without notably compromising accuracy. However, applying secure aggregation to sparsified models in DL is challenging due to the transmission of disjoint parameter sets by distinct nodes, which can prevent masks from canceling out effectively. This paper introduces CESAR, a novel secure aggregation protocol for DL designed to be compatible with existing sparsification mechanisms. CESAR provably defends against honest-but-curious adversaries and can be formally adapted to counteract collusion between them. We provide a foundational understanding of the interaction between the sparsification carried out by the nodes and the proportion of the parameters shared under CESAR in both colluding and non-colluding environments, offering analytical insight into the working and applicability of the protocol. Experiments on a network with 48 nodes in a 3-regular topology show that with random subsampling, CESAR is always within 0.5% accuracy of decentralized parallel stochastic gradient descent (D-PSGD), while adding only 11% of data overhead. Moreover, it surpasses the accuracy on TopK by up to 0.3% on independent and identically distributed (IID) data.
Get More for Less in Decentralized Learning Systems
Jun 07, 2023



Decentralized learning (DL) systems have been gaining popularity because they avoid raw data sharing by communicating only model parameters, hence preserving data confidentiality. However, the large size of deep neural networks poses a significant challenge for decentralized training, since each node needs to exchange gigabytes of data, overloading the network. In this paper, we address this challenge with JWINS, a communication-efficient and fully decentralized learning system that shares only a subset of parameters through sparsification. JWINS uses wavelet transform to limit the information loss due to sparsification and a randomized communication cut-off that reduces communication usage without damaging the performance of trained models. We demonstrate empirically with 96 DL nodes on non-IID datasets that JWINS can achieve similar accuracies to full-sharing DL while sending up to 64% fewer bytes. Additionally, on low communication budgets, JWINS outperforms the state-of-the-art communication-efficient DL algorithm CHOCO-SGD by up to 4x in terms of network savings and time.
Decentralized Learning Made Easy with DecentralizePy
Apr 17, 2023



Decentralized learning (DL) has gained prominence for its potential benefits in terms of scalability, privacy, and fault tolerance. It consists of many nodes that coordinate without a central server and exchange millions of parameters in the inherently iterative process of machine learning (ML) training. In addition, these nodes are connected in complex and potentially dynamic topologies. Assessing the intricate dynamics of such networks is clearly not an easy task. Often in literature, researchers resort to simulated environments that do not scale and fail to capture practical and crucial behaviors, including the ones associated to parallelism, data transfer, network delays, and wall-clock time. In this paper, we propose DecentralizePy, a distributed framework for decentralized ML, which allows for the emulation of large-scale learning networks in arbitrary topologies. We demonstrate the capabilities of DecentralizePy by deploying techniques such as sparsification and secure aggregation on top of several topologies, including dynamic networks with more than one thousand nodes.