 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRavan: Multi-Head Low-Rank Adaptation for Federated Fine-Tuning
Jun 05, 2025Large language models (LLMs) have not yet effectively leveraged the vast amounts of edge-device data, and federated learning (FL) offers a promising paradigm to collaboratively fine-tune LLMs without transferring private edge data to the cloud. To operate within the computation and communication constraints of edge devices, recent literature on federated fine-tuning of LLMs proposes the use of low-rank adaptation (LoRA) and similar parameter-efficient methods. However, LoRA-based methods suffer from accuracy degradation in FL settings, primarily because of data and computational heterogeneity across clients. We propose \textsc{Ravan}, an adaptive multi-head LoRA method that balances parameter efficiency and model expressivity by reparameterizing the weight updates as the sum of multiple LoRA heads $s_i\textbf{B}_i\textbf{H}_i\textbf{A}_i$ in which only the core matrices $\textbf{H}_i$ and their lightweight scaling factors $s_i$ are trained. These trainable scaling factors let the optimization focus on the most useful heads, recovering a higher-rank approximation of the full update without increasing the number of communicated parameters since clients upload $s_i\textbf{H}_i$ directly. Experiments on vision and language benchmarks show that \textsc{Ravan} improves test accuracy by 2-8\% over prior parameter-efficient baselines, making it a robust and scalable solution for federated fine-tuning of LLMs.
Navigating the Accuracy-Size Trade-Off with Flexible Model Merging
May 29, 2025Model merging has emerged as an efficient method to combine multiple single-task fine-tuned models. The merged model can enjoy multi-task capabilities without expensive training. While promising, merging into a single model often suffers from an accuracy gap with respect to individual fine-tuned models. On the other hand, deploying all individual fine-tuned models incurs high costs. We propose FlexMerge, a novel data-free model merging framework to flexibly generate merged models of varying sizes, spanning the spectrum from a single merged model to retaining all individual fine-tuned models. FlexMerge treats fine-tuned models as collections of sequential blocks and progressively merges them using any existing data-free merging method, halting at a desired size. We systematically explore the accuracy-size trade-off exhibited by different merging algorithms in combination with FlexMerge. Extensive experiments on vision and NLP benchmarks, with up to 30 tasks, reveal that even modestly larger merged models can provide substantial accuracy improvements over a single model. By offering fine-grained control over fused model size, FlexMerge provides a flexible, data-free, and high-performance solution for diverse deployment scenarios.
Initialization Matters: Unraveling the Impact of Pre-Training on Federated Learning
Feb 11, 2025Initializing with pre-trained models when learning on downstream tasks is becoming standard practice in machine learning. Several recent works explore the benefits of pre-trained initialization in a federated learning (FL) setting, where the downstream training is performed at the edge clients with heterogeneous data distribution. These works show that starting from a pre-trained model can substantially reduce the adverse impact of data heterogeneity on the test performance of a model trained in a federated setting, with no changes to the standard FedAvg training algorithm. In this work, we provide a deeper theoretical understanding of this phenomenon. To do so, we study the class of two-layer convolutional neural networks (CNNs) and provide bounds on the training error convergence and test error of such a network trained with FedAvg. We introduce the notion of aligned and misaligned filters at initialization and show that the data heterogeneity only affects learning on misaligned filters. Starting with a pre-trained model typically results in fewer misaligned filters at initialization, thus producing a lower test error even when the model is trained in a federated setting with data heterogeneity. Experiments in synthetic settings and practical FL training on CNNs verify our theoretical findings.
Erasure Coded Neural Network Inference via Fisher Averaging
Sep 02, 2024


Erasure-coded computing has been successfully used in cloud systems to reduce tail latency caused by factors such as straggling servers and heterogeneous traffic variations. A majority of cloud computing traffic now consists of inference on neural networks on shared resources where the response time of inference queries is also adversely affected by the same factors. However, current erasure coding techniques are largely focused on linear computations such as matrix-vector and matrix-matrix multiplications and hence do not work for the highly non-linear neural network functions. In this paper, we seek to design a method to code over neural networks, that is, given two or more neural network models, how to construct a coded model whose output is a linear combination of the outputs of the given neural networks. We formulate the problem as a KL barycenter problem and propose a practical algorithm COIN that leverages the diagonal Fisher information to create a coded model that approximately outputs the desired linear combination of outputs. We conduct experiments to perform erasure coding over neural networks trained on real-world vision datasets and show that the accuracy of the decoded outputs using COIN is significantly higher than other baselines while being extremely compute-efficient.
FedFisher: Leveraging Fisher Information for One-Shot Federated Learning
Mar 19, 2024Standard federated learning (FL) algorithms typically require multiple rounds of communication between the server and the clients, which has several drawbacks, including requiring constant network connectivity, repeated investment of computational resources, and susceptibility to privacy attacks. One-Shot FL is a new paradigm that aims to address this challenge by enabling the server to train a global model in a single round of communication. In this work, we present FedFisher, a novel algorithm for one-shot FL that makes use of Fisher information matrices computed on local client models, motivated by a Bayesian perspective of FL. First, we theoretically analyze FedFisher for two-layer over-parameterized ReLU neural networks and show that the error of our one-shot FedFisher global model becomes vanishingly small as the width of the neural networks and amount of local training at clients increases. Next, we propose practical variants of FedFisher using the diagonal Fisher and K-FAC approximation for the full Fisher and highlight their communication and compute efficiency for FL. Finally, we conduct extensive experiments on various datasets, which show that these variants of FedFisher consistently improve over competing baselines.
FedExP: Speeding up Federated Averaging Via Extrapolation
Jan 23, 2023



Federated Averaging (FedAvg) remains the most popular algorithm for Federated Learning (FL) optimization due to its simple implementation, stateless nature, and privacy guarantees combined with secure aggregation. Recent work has sought to generalize the vanilla averaging in FedAvg to a generalized gradient descent step by treating client updates as pseudo-gradients and using a server step size. While the use of a server step size has been shown to provide performance improvement theoretically, the practical benefit of the server step size has not been seen in most existing works. In this work, we present FedExP, a method to adaptively determine the server step size in FL based on dynamically varying pseudo-gradients throughout the FL process. We begin by considering the overparameterized convex regime, where we reveal an interesting similarity between FedAvg and the Projection Onto Convex Sets (POCS) algorithm. We then show how FedExP can be motivated as a novel extension to the extrapolation mechanism that is used to speed up POCS. Our theoretical analysis later also discusses the implications of FedExP in underparameterized and non-convex settings. Experimental results show that FedExP consistently converges faster than FedAvg and competing baselines on a range of realistic FL datasets.
FedVARP: Tackling the Variance Due to Partial Client Participation in Federated Learning
Jul 28, 2022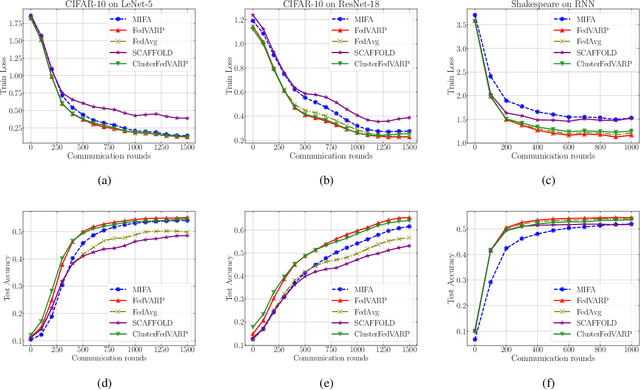
Data-heterogeneous federated learning (FL) systems suffer from two significant sources of convergence error: 1) client drift error caused by performing multiple local optimization steps at clients, and 2) partial client participation error caused by the fact that only a small subset of the edge clients participate in every training round. We find that among these, only the former has received significant attention in the literature. To remedy this, we propose FedVARP, a novel variance reduction algorithm applied at the server that eliminates error due to partial client participation. To do so, the server simply maintains in memory the most recent update for each client and uses these as surrogate updates for the non-participating clients in every round. Further, to alleviate the memory requirement at the server, we propose a novel clustering-based variance reduction algorithm ClusterFedVARP. Unlike previously proposed methods, both FedVARP and ClusterFedVARP do not require additional computation at clients or communication of additional optimization parameters. Through extensive experiments, we show that FedVARP outperforms state-of-the-art methods, and ClusterFedVARP achieves performance comparable to FedVARP with much less memory requirements.
To Federate or Not To Federate: Incentivizing Client Participation in Federated Learning
May 30, 2022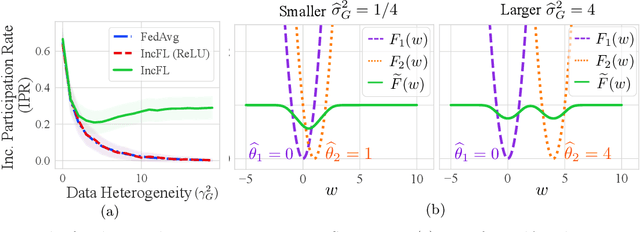

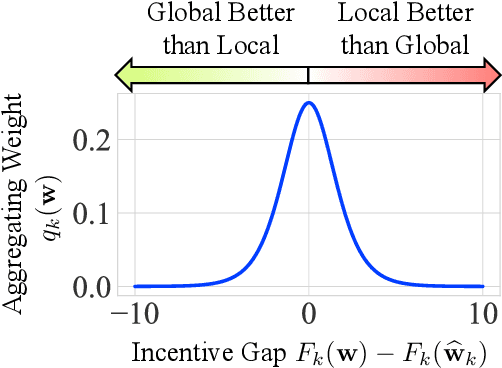
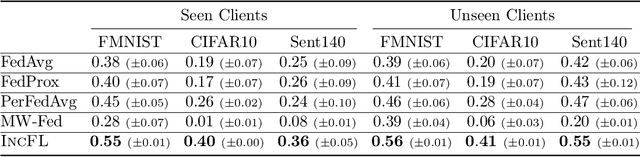
Federated learning (FL) facilitates collaboration between a group of clients who seek to train a common machine learning model without directly sharing their local data. Although there is an abundance of research on improving the speed, efficiency, and accuracy of federated training, most works implicitly assume that all clients are willing to participate in the FL framework. Due to data heterogeneity, however, the global model may not work well for some clients, and they may instead choose to use their own local model. Such disincentivization of clients can be problematic from the server's perspective because having more participating clients yields a better global model, and offers better privacy guarantees to the participating clients. In this paper, we propose an algorithm called IncFL that explicitly maximizes the fraction of clients who are incentivized to use the global model by dynamically adjusting the aggregation weights assigned to their updates. Our experiments show that IncFL increases the number of incentivized clients by 30-55% compared to standard federated training algorithms, and can also improve the generalization performance of the global model on unseen clients.
Leveraging Spatial and Temporal Correlations in Sparsified Mean Estimation
Oct 14, 2021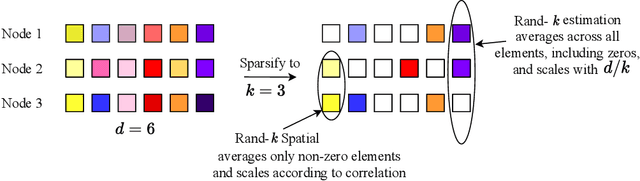
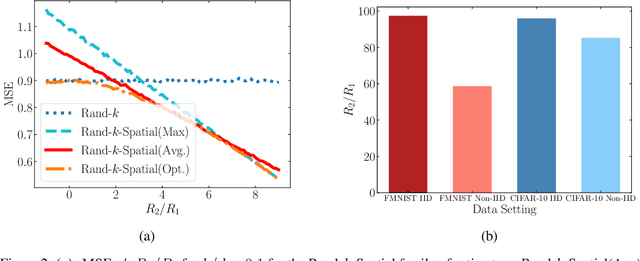
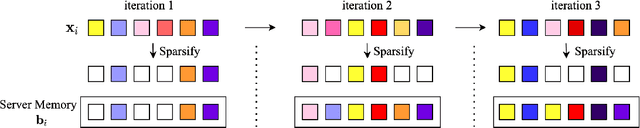
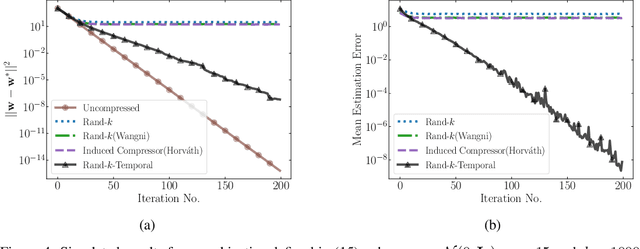
We study the problem of estimating at a central server the mean of a set of vectors distributed across several nodes (one vector per node). When the vectors are high-dimensional, the communication cost of sending entire vectors may be prohibitive, and it may be imperative for them to use sparsification techniques. While most existing work on sparsified mean estimation is agnostic to the characteristics of the data vectors, in many practical applications such as federated learning, there may be spatial correlations (similarities in the vectors sent by different nodes) or temporal correlations (similarities in the data sent by a single node over different iterations of the algorithm) in the data vectors. We leverage these correlations by simply modifying the decoding method used by the server to estimate the mean. We provide an analysis of the resulting estimation error as well as experiments for PCA, K-Means and Logistic Regression, which show that our estimators consistently outperform more sophisticated and expensive sparsification methods.
Adaptive Quantization of Model Updates for Communication-Efficient Federated Learning
Feb 08, 2021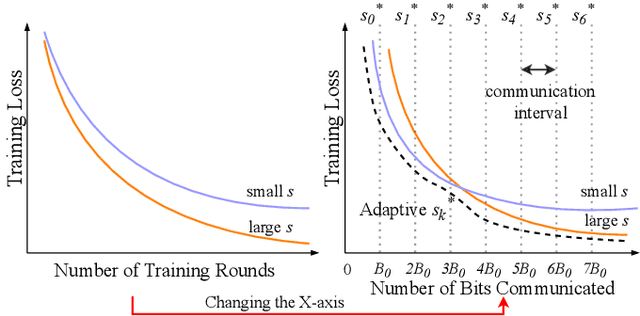
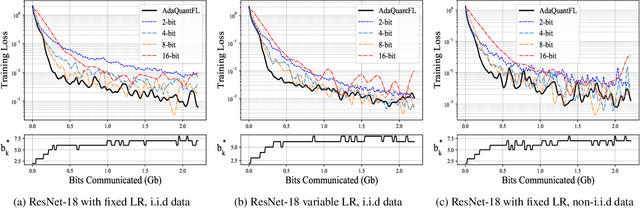
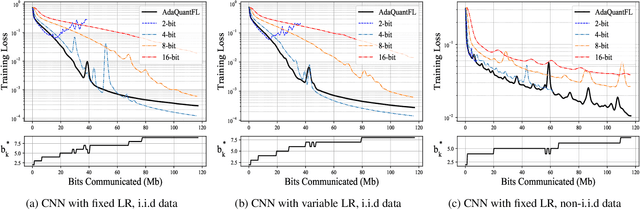
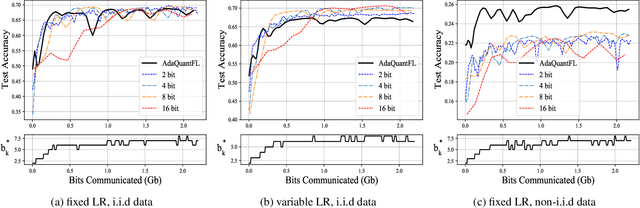
Communication of model updates between client nodes and the central aggregating server is a major bottleneck in federated learning, especially in bandwidth-limited settings and high-dimensional models. Gradient quantization is an effective way of reducing the number of bits required to communicate each model update, albeit at the cost of having a higher error floor due to the higher variance of the stochastic gradients. In this work, we propose an adaptive quantization strategy called AdaQuantFL that aims to achieve communication efficiency as well as a low error floor by changing the number of quantization levels during the course of training. Experiments on training deep neural networks show that our method can converge in much fewer communicated bits as compared to fixed quantization level setups, with little or no impact on training and test accuracy.