 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Quantization of Model Updates for Communication-Efficient Federated Learning
Paper and Code
Feb 08, 2021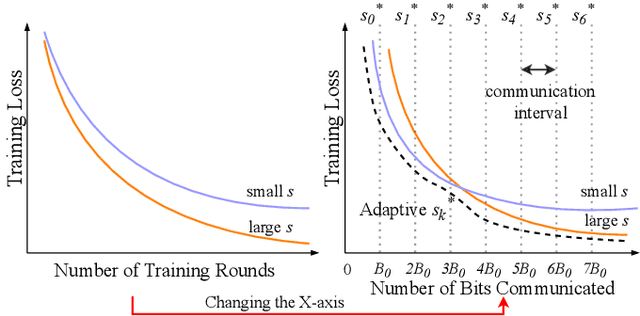
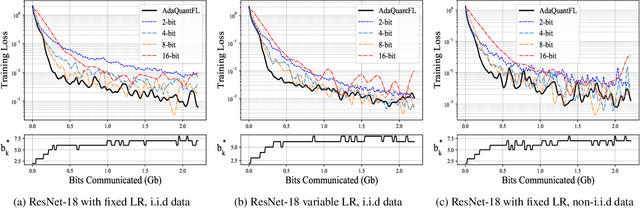
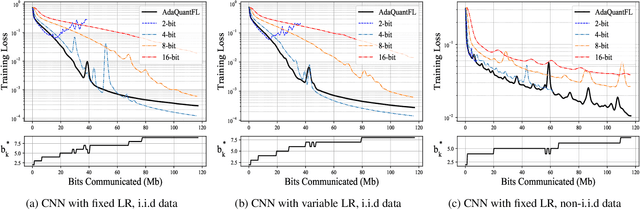
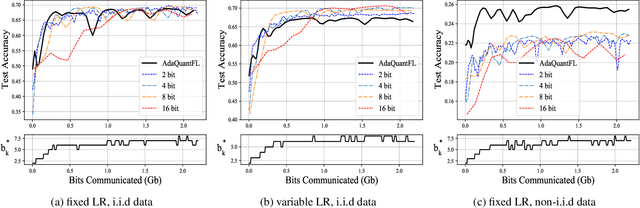
Communication of model updates between client nodes and the central aggregating server is a major bottleneck in federated learning, especially in bandwidth-limited settings and high-dimensional models. Gradient quantization is an effective way of reducing the number of bits required to communicate each model update, albeit at the cost of having a higher error floor due to the higher variance of the stochastic gradients. In this work, we propose an adaptive quantization strategy called AdaQuantFL that aims to achieve communication efficiency as well as a low error floor by changing the number of quantization levels during the course of training. Experiments on training deep neural networks show that our method can converge in much fewer communicated bits as compared to fixed quantization level setups, with little or no impact on training and test accuracy.