 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptRot: Mitigating Weight Outliers via Data-Free Rotations for Post-Training Quantization
Dec 30, 2025The presence of outliers in Large Language Models (LLMs) weights and activations makes them difficult to quantize. Recent work has leveraged rotations to mitigate these outliers. In this work, we propose methods that learn fusible rotations by minimizing principled and cheap proxy objectives to the weight quantization error. We primarily focus on GPTQ as the quantization method. Our main method is OptRot, which reduces weight outliers simply by minimizing the element-wise fourth power of the rotated weights. We show that OptRot outperforms both Hadamard rotations and more expensive, data-dependent methods like SpinQuant and OSTQuant for weight quantization. It also improves activation quantization in the W4A8 setting. We also propose a data-dependent method, OptRot$^{+}$, that further improves performance by incorporating information on the activation covariance. In the W4A4 setting, we see that both OptRot and OptRot$^{+}$ perform worse, highlighting a trade-off between weight and activation quantization.
Pay Attention to Small Weights
Jun 26, 2025Finetuning large pretrained neural networks is known to be resource-intensive, both in terms of memory and computational cost. To mitigate this, a common approach is to restrict training to a subset of the model parameters. By analyzing the relationship between gradients and weights during finetuning, we observe a notable pattern: large gradients are often associated with small-magnitude weights. This correlation is more pronounced in finetuning settings than in training from scratch. Motivated by this observation, we propose NANOADAM, which dynamically updates only the small-magnitude weights during finetuning and offers several practical advantages: first, this criterion is gradient-free -- the parameter subset can be determined without gradient computation; second, it preserves large-magnitude weights, which are likely to encode critical features learned during pretraining, thereby reducing the risk of catastrophic forgetting; thirdly, it permits the use of larger learning rates and consistently leads to better generalization performance in experiments. We demonstrate this for both NLP and vision tasks.
Sign-In to the Lottery: Reparameterizing Sparse Training From Scratch
Apr 17, 2025The performance gap between training sparse neural networks from scratch (PaI) and dense-to-sparse training presents a major roadblock for efficient deep learning. According to the Lottery Ticket Hypothesis, PaI hinges on finding a problem specific parameter initialization. As we show, to this end, determining correct parameter signs is sufficient. Yet, they remain elusive to PaI. To address this issue, we propose Sign-In, which employs a dynamic reparameterization that provably induces sign flips. Such sign flips are complementary to the ones that dense-to-sparse training can accomplish, rendering Sign-In as an orthogonal method. While our experiments and theory suggest performance improvements of PaI, they also carve out the main open challenge to close the gap between PaI and dense-to-sparse training.
Attention Is All You Need For Mixture-of-Depths Routing
Dec 30, 2024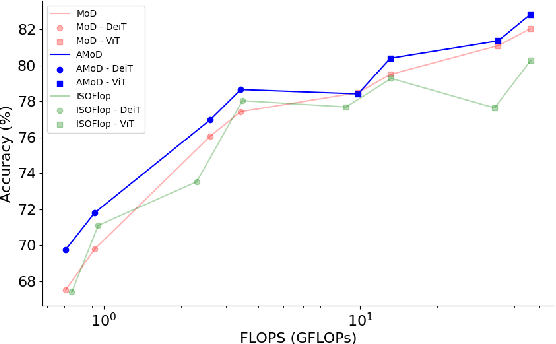
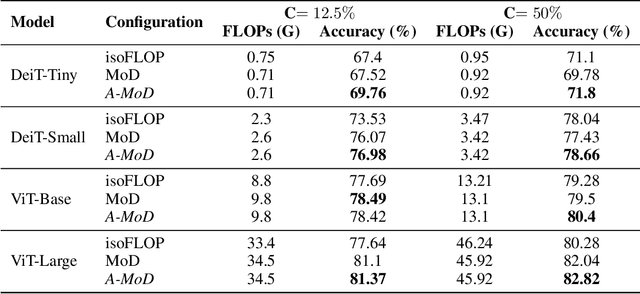
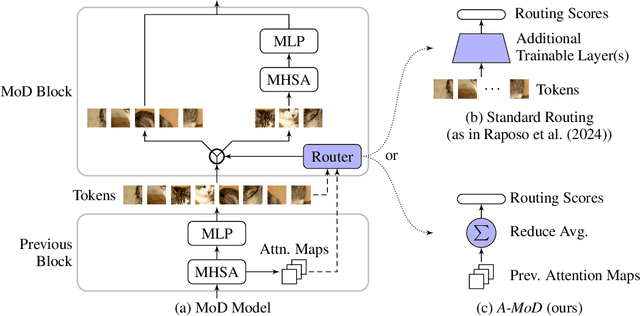
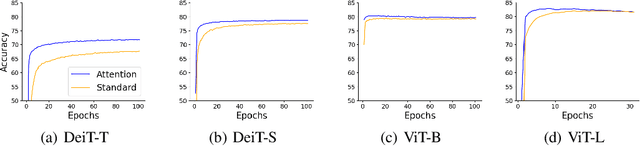
Advancements in deep learning are driven by training models with increasingly larger numbers of parameters, which in turn heightens the computational demands. To address this issue, Mixture-of-Depths (MoD) models have been proposed to dynamically assign computations only to the most relevant parts of the inputs, thereby enabling the deployment of large-parameter models with high efficiency during inference and training. These MoD models utilize a routing mechanism to determine which tokens should be processed by a layer, or skipped. However, conventional MoD models employ additional network layers specifically for the routing which are difficult to train, and add complexity and deployment overhead to the model. In this paper, we introduce a novel attention-based routing mechanism A-MoD that leverages the existing attention map of the preceding layer for routing decisions within the current layer. Compared to standard routing, A-MoD allows for more efficient training as it introduces no additional trainable parameters and can be easily adapted from pretrained transformer models. Furthermore, it can increase the performance of the MoD model. For instance, we observe up to 2% higher accuracy on ImageNet compared to standard routing and isoFLOP ViT baselines. Furthermore, A-MoD improves the MoD training convergence, leading to up to 2x faster transfer learning.
Cyclic Sparse Training: Is it Enough?
Jun 07, 2024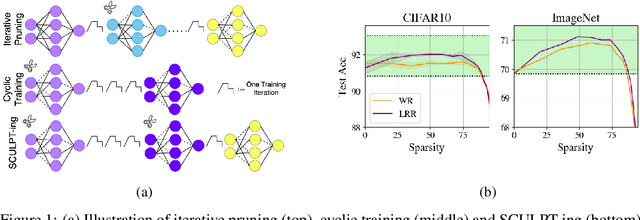

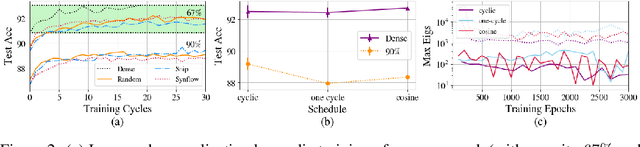

The success of iterative pruning methods in achieving state-of-the-art sparse networks has largely been attributed to improved mask identification and an implicit regularization induced by pruning. We challenge this hypothesis and instead posit that their repeated cyclic training schedules enable improved optimization. To verify this, we show that pruning at initialization is significantly boosted by repeated cyclic training, even outperforming standard iterative pruning methods. The dominant mechanism how this is achieved, as we conjecture, can be attributed to a better exploration of the loss landscape leading to a lower training loss. However, at high sparsity, repeated cyclic training alone is not enough for competitive performance. A strong coupling between learnt parameter initialization and mask seems to be required. Standard methods obtain this coupling via expensive pruning-training iterations, starting from a dense network. To achieve this with sparse training instead, we propose SCULPT-ing, i.e., repeated cyclic training of any sparse mask followed by a single pruning step to couple the parameters and the mask, which is able to match the performance of state-of-the-art iterative pruning methods in the high sparsity regime at reduced computational cost.
Masks, Signs, And Learning Rate Rewinding
Feb 29, 2024Learning Rate Rewinding (LRR) has been established as a strong variant of Iterative Magnitude Pruning (IMP) to find lottery tickets in deep overparameterized neural networks. While both iterative pruning schemes couple structure and parameter learning, understanding how LRR excels in both aspects can bring us closer to the design of more flexible deep learning algorithms that can optimize diverse sets of sparse architectures. To this end, we conduct experiments that disentangle the effect of mask learning and parameter optimization and how both benefit from overparameterization. The ability of LRR to flip parameter signs early and stay robust to sign perturbations seems to make it not only more effective in mask identification but also in optimizing diverse sets of masks, including random ones. In support of this hypothesis, we prove in a simplified single hidden neuron setting that LRR succeeds in more cases than IMP, as it can escape initially problematic sign configurations.
How Erdös and Rényi Win the Lottery
Oct 05, 2022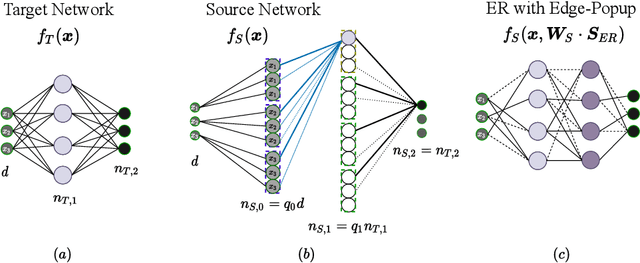

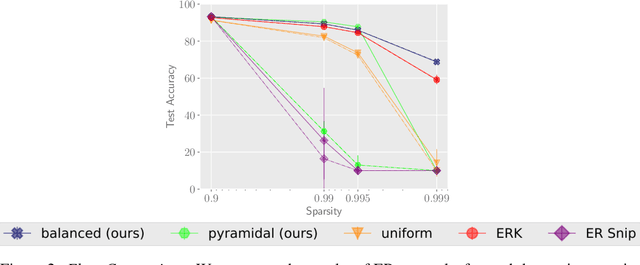

Random masks define surprisingly effective sparse neural network models, as has been shown empirically. The resulting Erd\"os-R\'enyi (ER) random graphs can often compete with dense architectures and state-of-the-art lottery ticket pruning algorithms struggle to outperform them, even though the random baselines do not rely on computationally expensive pruning-training iterations but can be drawn initially without significant computational overhead. We offer a theoretical explanation of how such ER masks can approximate arbitrary target networks if they are wider by a logarithmic factor in the inverse sparsity $1 / \log(1/\text{sparsity})$. While we are the first to show theoretically and experimentally that random ER source networks contain strong lottery tickets, we also prove the existence of weak lottery tickets that require a lower degree of overparametrization than strong lottery tickets. These unusual results are based on the observation that ER masks are well trainable in practice, which we verify in experiments with varied choices of random masks. Some of these data-free choices outperform previously proposed random approaches on standard image classification benchmark datasets.
Dynamical Isometry for Residual Networks
Oct 05, 2022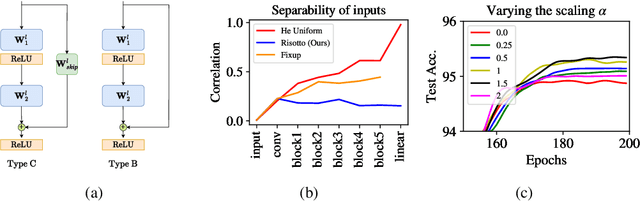
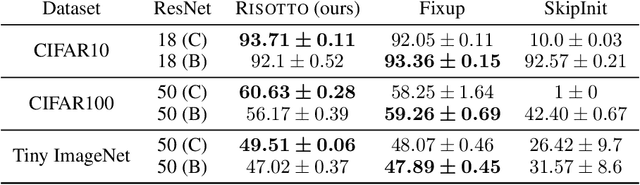

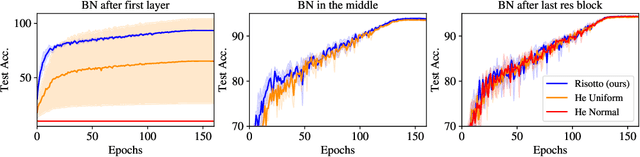
The training success, training speed and generalization ability of neural networks rely crucially on the choice of random parameter initialization. It has been shown for multiple architectures that initial dynamical isometry is particularly advantageous. Known initialization schemes for residual blocks, however, miss this property and suffer from degrading separability of different inputs for increasing depth and instability without Batch Normalization or lack feature diversity. We propose a random initialization scheme, RISOTTO, that achieves perfect dynamical isometry for residual networks with ReLU activation functions even for finite depth and width. It balances the contributions of the residual and skip branches unlike other schemes, which initially bias towards the skip connections. In experiments, we demonstrate that in most cases our approach outperforms initialization schemes proposed to make Batch Normalization obsolete, including Fixup and SkipInit, and facilitates stable training. Also in combination with Batch Normalization, we find that RISOTTO often achieves the overall best result.
Leveraging Spatial and Temporal Correlations in Sparsified Mean Estimation
Oct 14, 2021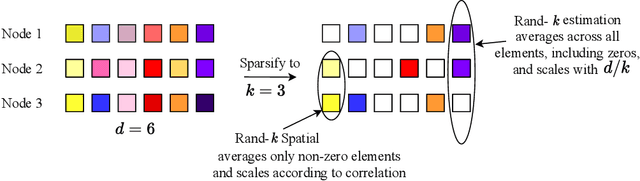
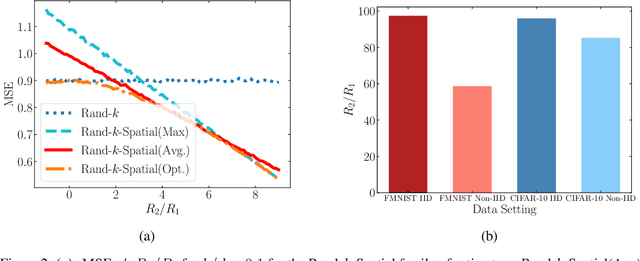
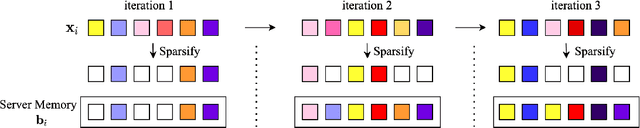
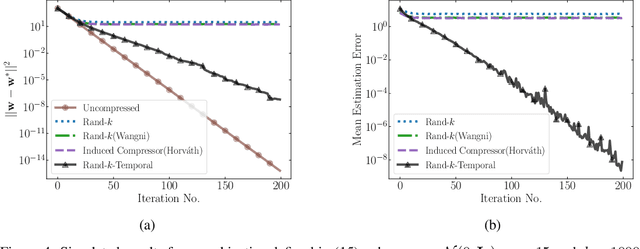
We study the problem of estimating at a central server the mean of a set of vectors distributed across several nodes (one vector per node). When the vectors are high-dimensional, the communication cost of sending entire vectors may be prohibitive, and it may be imperative for them to use sparsification techniques. While most existing work on sparsified mean estimation is agnostic to the characteristics of the data vectors, in many practical applications such as federated learning, there may be spatial correlations (similarities in the vectors sent by different nodes) or temporal correlations (similarities in the data sent by a single node over different iterations of the algorithm) in the data vectors. We leverage these correlations by simply modifying the decoding method used by the server to estimate the mean. We provide an analysis of the resulting estimation error as well as experiments for PCA, K-Means and Logistic Regression, which show that our estimators consistently outperform more sophisticated and expensive sparsification methods.
A Field Guide to Federated Optimization
Jul 14, 2021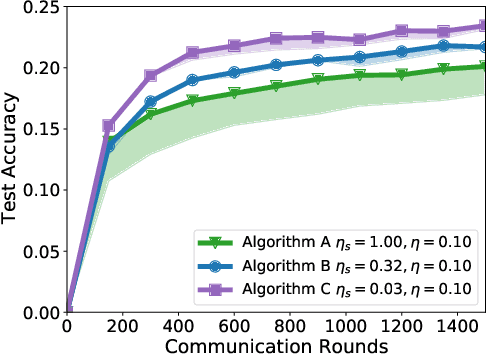


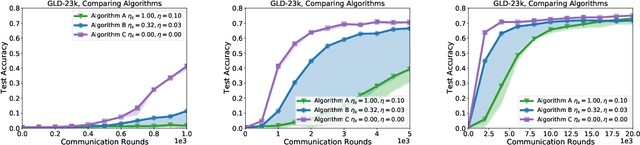
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.