 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Isometry for Residual Networks
Paper and Code
Oct 05, 2022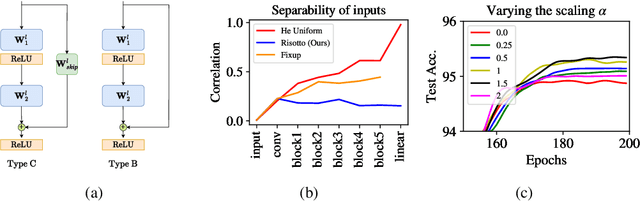
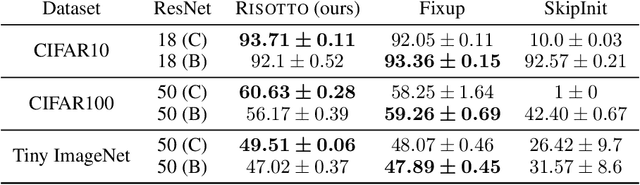

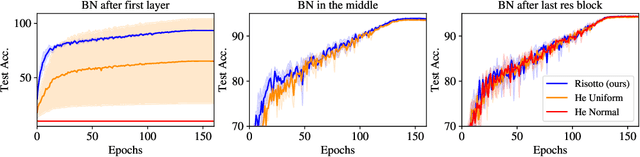
The training success, training speed and generalization ability of neural networks rely crucially on the choice of random parameter initialization. It has been shown for multiple architectures that initial dynamical isometry is particularly advantageous. Known initialization schemes for residual blocks, however, miss this property and suffer from degrading separability of different inputs for increasing depth and instability without Batch Normalization or lack feature diversity. We propose a random initialization scheme, RISOTTO, that achieves perfect dynamical isometry for residual networks with ReLU activation functions even for finite depth and width. It balances the contributions of the residual and skip branches unlike other schemes, which initially bias towards the skip connections. In experiments, we demonstrate that in most cases our approach outperforms initialization schemes proposed to make Batch Normalization obsolete, including Fixup and SkipInit, and facilitates stable training. Also in combination with Batch Normalization, we find that RISOTTO often achieves the overall best result.