 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-step Cofolding with All-Atom Flow Maps
Jun 07, 2026All-atom generative modeling of 3D biomolecular complexes has emerged as the dominant paradigm for predicting the structure of proteins and protein-ligand systems. Generating structures at the atomic level of fidelity, however, typically requires expensive iterative diffusion rollouts, making both conventional deployment and inference-time search techniques computationally costly. In this paper, we introduce the Denoiser Cofolding All-Atom Flowmap (DeCAF) framework for distilling state-of-the-art all-atom cofolding models into all-atom flow maps that produce high-quality samples in only a few inference steps. We build DeCAF on a denoiser-based formulation of flow maps with endpoint losses that naturally support SE(3) rigid alignment, which we show is critical for training accurate models. We further derive a simple change of variables that lets DeCAF operate in the σ-space noise schedule of EDM-style architectures, enabling direct distillation from pretrained cofolding diffusion models. Equipped with DeCAF's flowmap lookahead, we introduce a purpose-built inference-time framework that improves sampling through reward-guided search. Empirically, DeCAF-Boltz statistically improves over Boltz-1x in both accuracy (RMSD) and physical validity scores of protein-ligand poses at strict NFE budgets on the challenging Runs N' Poses, while also showing a more optimal Pareto frontier across all inference compute budgets on PoseBusters. Distilling the state-of-the-art Pearl cofolding model, DeCAF-Pearl outperforms diffusion-based cofolding models and matches its teacher on success rate while using 5x fewer NFEs. We release our code at https://github.com/genesistherapeutics/decaf.
Knowledge-Aware Meta-learning for Low-Resource Text Classification
Sep 10, 2021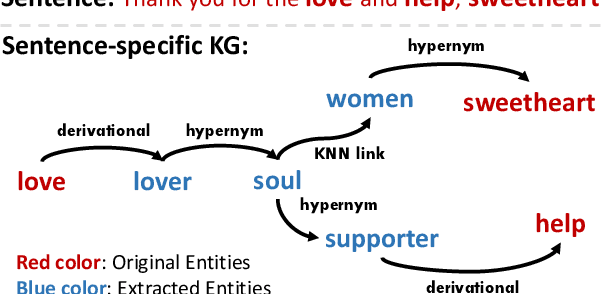
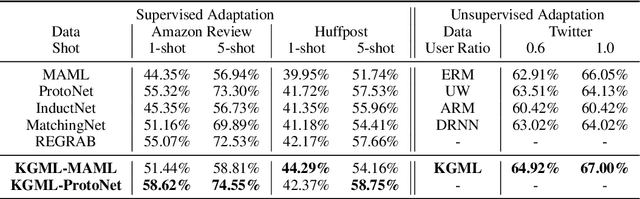
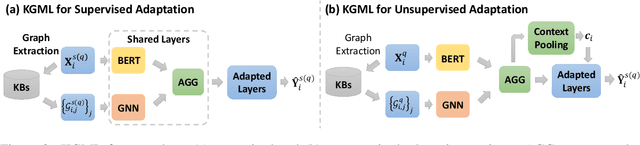
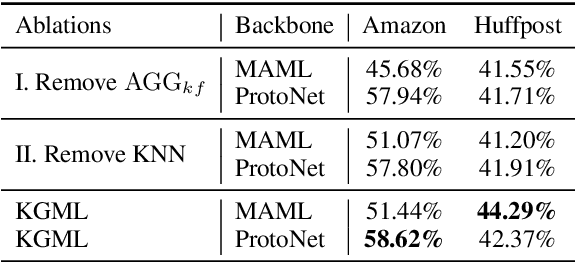
Meta-learning has achieved great success in leveraging the historical learned knowledge to facilitate the learning process of the new task. However, merely learning the knowledge from the historical tasks, adopted by current meta-learning algorithms, may not generalize well to testing tasks when they are not well-supported by training tasks. This paper studies a low-resource text classification problem and bridges the gap between meta-training and meta-testing tasks by leveraging the external knowledge bases. Specifically, we propose KGML to introduce additional representation for each sentence learned from the extracted sentence-specific knowledge graph. The extensive experiments on three datasets demonstrate the effectiveness of KGML under both supervised adaptation and unsupervised adaptation settings.
A Field Guide to Federated Optimization
Jul 14, 2021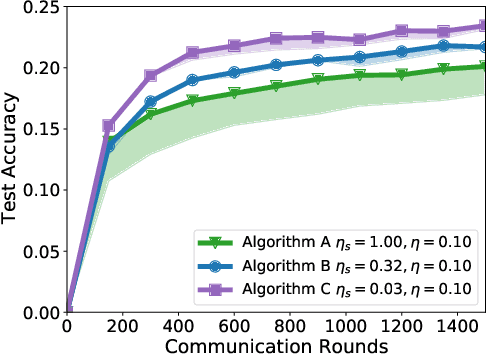


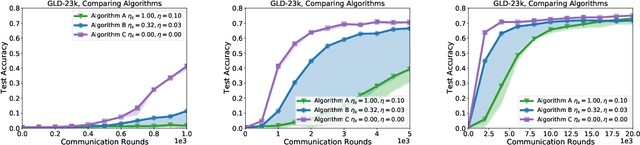
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
On Data Efficiency of Meta-learning
Jan 30, 2021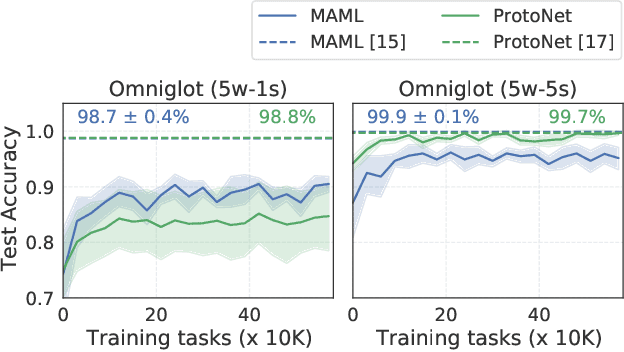
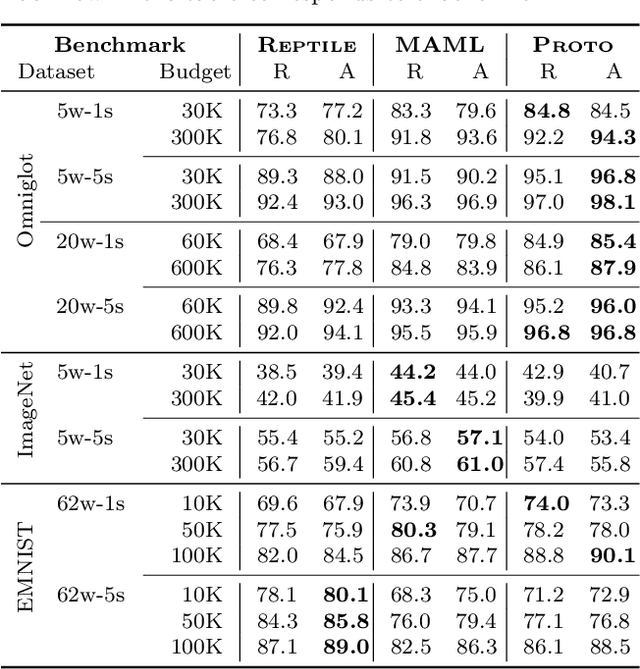

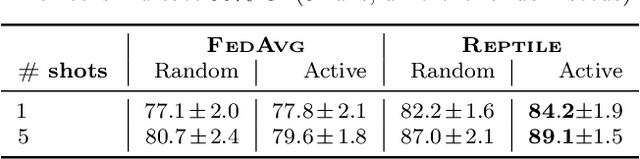
Meta-learning has enabled learning statistical models that can be quickly adapted to new prediction tasks. Motivated by use-cases in personalized federated learning, we study the often overlooked aspect of the modern meta-learning algorithms -- their data efficiency. To shed more light on which methods are more efficient, we use techniques from algorithmic stability to derive bounds on the transfer risk that have important practical implications, indicating how much supervision is needed and how it must be allocated for each method to attain the desired level of generalization. Further, we introduce a new simple framework for evaluating meta-learning methods under a limit on the available supervision, conduct an empirical study of MAML, Reptile, and Protonets, and demonstrate the differences in the behavior of these methods on few-shot and federated learning benchmarks. Finally, we propose active meta-learning, which incorporates active data selection into learning-to-learn, leading to better performance of all methods in the limited supervision regime.
Federated Learning via Posterior Averaging: A New Perspective and Practical Algorithms
Oct 11, 2020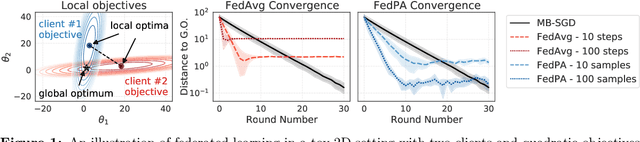

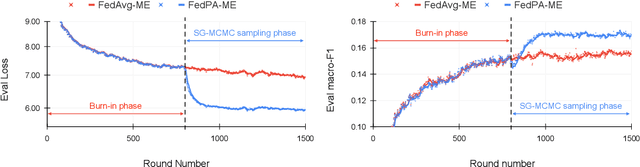
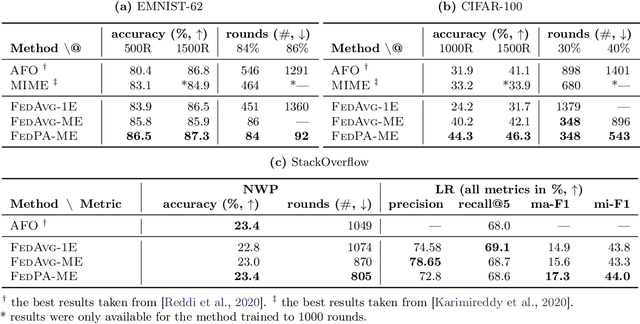
Federated learning is typically approached as an optimization problem, where the goal is to minimize a global loss function by distributing computation across client devices that possess local data and specify different parts of the global objective. We present an alternative perspective and formulate federated learning as a posterior inference problem, where the goal is to infer a global posterior distribution by having client devices each infer the posterior of their local data. While exact inference is often intractable, this perspective provides a principled way to search for global optima in federated settings. Further, starting with the analysis of federated quadratic objectives, we develop a computation- and communication-efficient approximate posterior inference algorithm -- federated posterior averaging (FedPA). Our algorithm uses MCMC for approximate inference of local posteriors on the clients and efficiently communicates their statistics to the server, where the latter uses them to refine a global estimate of the posterior mode. Finally, we show that FedPA generalizes federated averaging (FedAvg), can similarly benefit from adaptive optimizers, and yields state-of-the-art results on four realistic and challenging benchmarks, converging faster, to better optima.
Learning from Imperfect Annotations
Apr 07, 2020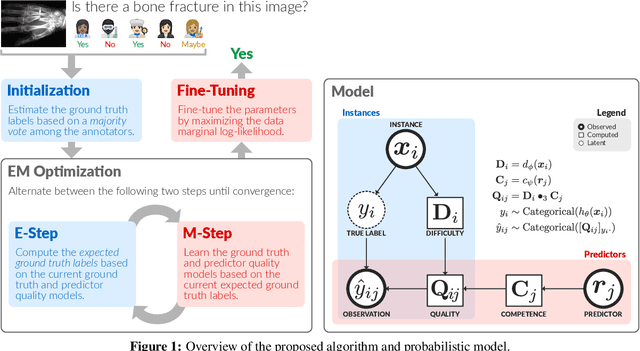
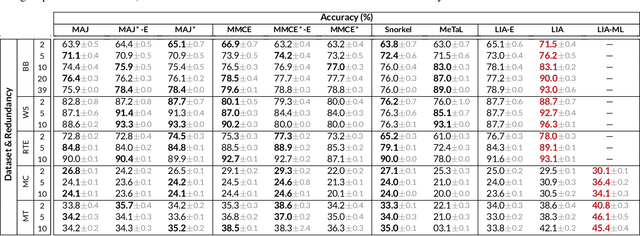
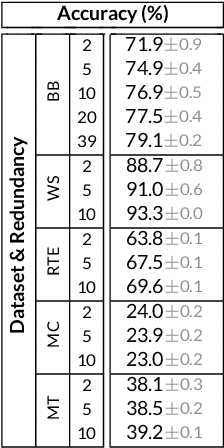
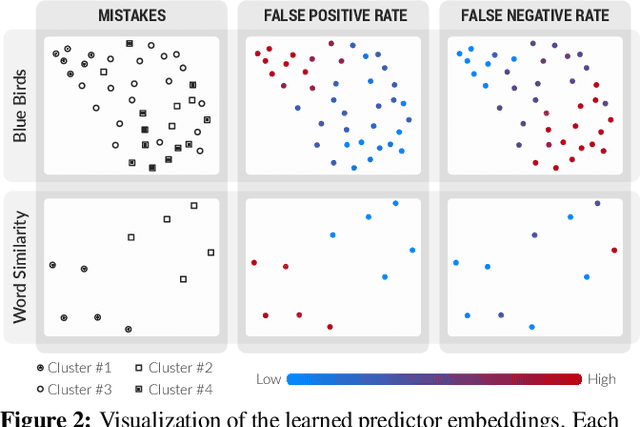
Many machine learning systems today are trained on large amounts of human-annotated data. Data annotation tasks that require a high level of competency make data acquisition expensive, while the resulting labels are often subjective, inconsistent, and may contain a variety of human biases. To improve the data quality, practitioners often need to collect multiple annotations per example and aggregate them before training models. Such a multi-stage approach results in redundant annotations and may often produce imperfect "ground truth" that may limit the potential of training accurate machine learning models. We propose a new end-to-end framework that enables us to: (i) merge the aggregation step with model training, thus allowing deep learning systems to learn to predict ground truth estimates directly from the available data, and (ii) model difficulties of examples and learn representations of the annotators that allow us to estimate and take into account their competencies. Our approach is general and has many applications, including training more accurate models on crowdsourced data, ensemble learning, as well as classifier accuracy estimation from unlabeled data. We conduct an extensive experimental evaluation of our method on 5 crowdsourcing datasets of varied difficulty and show accuracy gains of up to 25% over the current state-of-the-art approaches for aggregating annotations, as well as significant reductions in the required annotation redundancy.
Regularizing Black-box Models for Improved Interpretability (HILL 2019 Version)
May 31, 2019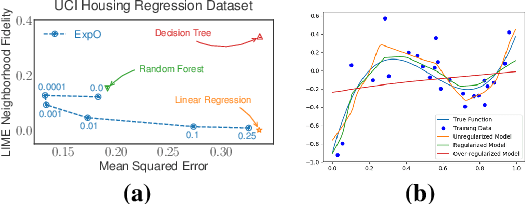
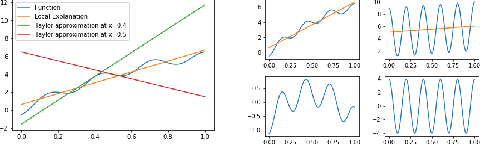
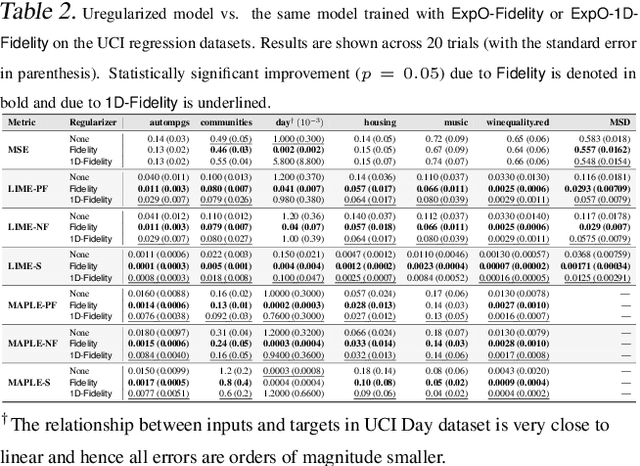
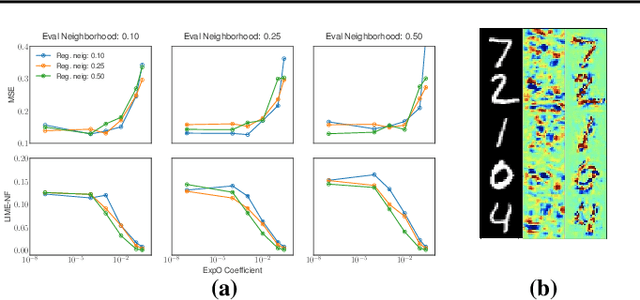
Most of the work on interpretable machine learning has focused on designing either inherently interpretable models, which typically trade-off accuracy for interpretability, or post-hoc explanation systems, which lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: (i) the model's innate explainability, (ii) the explanation system used at test time, and (iii) the metrics that measure explanation quality. Our regularization results in substantial improvement in terms of the explanation fidelity and stability metrics across a range of datasets and black-box explanation systems while slightly improving accuracy. Further, if the resulting model is still not sufficiently interpretable, the weight of the regularization term can be adjusted to achieve the desired trade-off between accuracy and interpretability. Finally, we justify theoretically that the benefits of explanation-based regularization generalize to unseen points.
Consistency by Agreement in Zero-shot Neural Machine Translation
Apr 10, 2019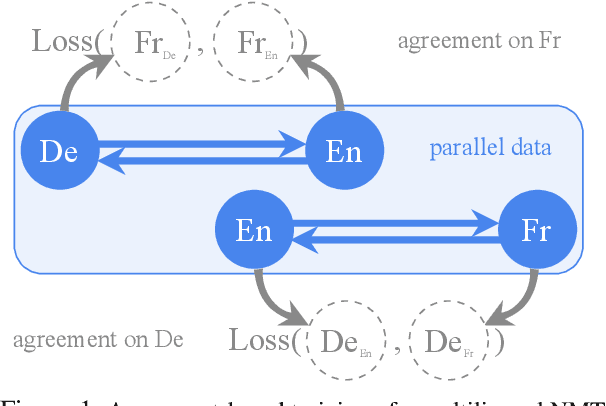
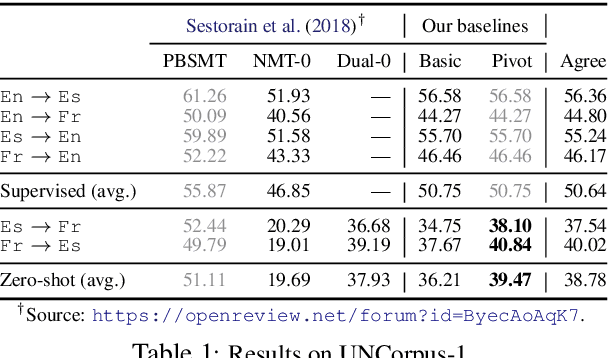

Generalization and reliability of multilingual translation often highly depend on the amount of available parallel data for each language pair of interest. In this paper, we focus on zero-shot generalization---a challenging setup that tests models on translation directions they have not been optimized for at training time. To solve the problem, we (i) reformulate multilingual translation as probabilistic inference, (ii) define the notion of zero-shot consistency and show why standard training often results in models unsuitable for zero-shot tasks, and (iii) introduce a consistent agreement-based training method that encourages the model to produce equivalent translations of parallel sentences in auxiliary languages. We test our multilingual NMT models on multiple public zero-shot translation benchmarks (IWSLT17, UN corpus, Europarl) and show that agreement-based learning often results in 2-3 BLEU zero-shot improvement over strong baselines without any loss in performance on supervised translation directions.
Regularizing Black-box Models for Improved Interpretability
Feb 18, 2019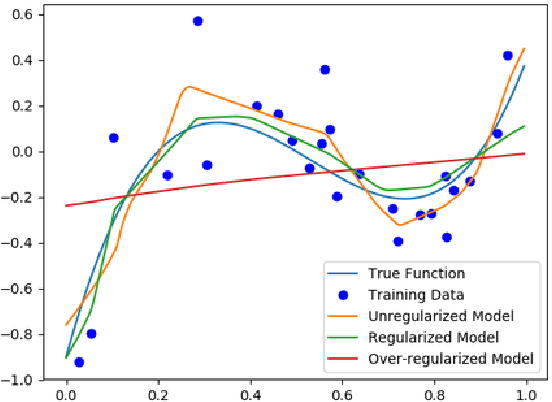
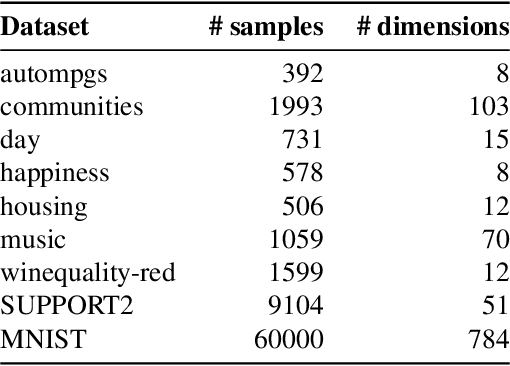
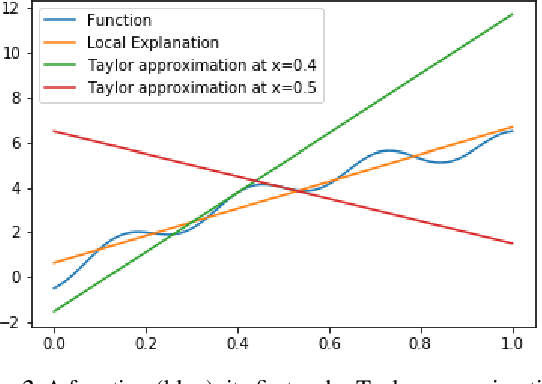
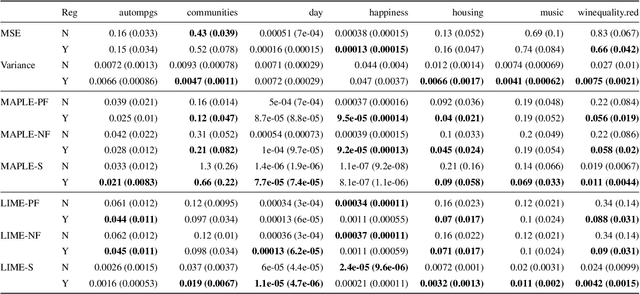
Most work on interpretability in machine learning has focused on designing either inherently interpretable models, that typically trade-off interpretability for accuracy, or post-hoc explanation systems, that lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: the model's innate explainability, the explanation system used at test time, and the metrics that measure explanation quality. Our regularization results in substantial (up to orders of magnitude) improvement in terms of explanation fidelity and stability metrics across a range of datasets, models, and black-box explanation systems. Remarkably, our regularizers also slightly improve predictive accuracy on average across the nine datasets we consider. Further, we show that the benefits of our novel regularizers on explanation quality provably generalize to unseen test points.
On the Complexity of Exploration in Goal-Driven Navigation
Nov 16, 2018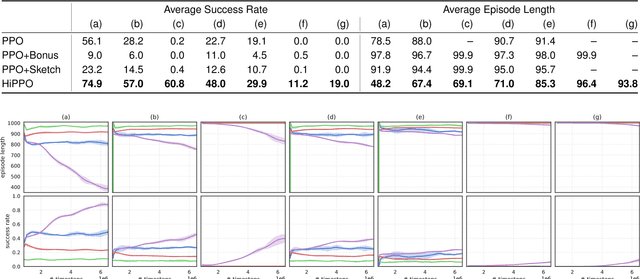
Building agents that can explore their environments intelligently is a challenging open problem. In this paper, we make a step towards understanding how a hierarchical design of the agent's policy can affect its exploration capabilities. First, we design EscapeRoom environments, where the agent must figure out how to navigate to the exit by accomplishing a number of intermediate tasks (\emph{subgoals}), such as finding keys or opening doors. Our environments are procedurally generated and vary in complexity, which can be controlled by the number of subgoals and relationships between them. Next, we propose to measure the complexity of each environment by constructing dependency graphs between the goals and analytically computing \emph{hitting times} of a random walk in the graph. We empirically evaluate Proximal Policy Optimization (PPO) with sparse and shaped rewards, a variation of policy sketches, and a hierarchical version of PPO (called HiPPO) akin to h-DQN. We show that analytically estimated \emph{hitting time} in goal dependency graphs is an informative metric of the environment complexity. We conjecture that the result should hold for environments other than navigation. Finally, we show that solving environments beyond certain level of complexity requires hierarchical approaches.