 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Data Efficiency of Meta-learning
Paper and Code
Jan 30, 2021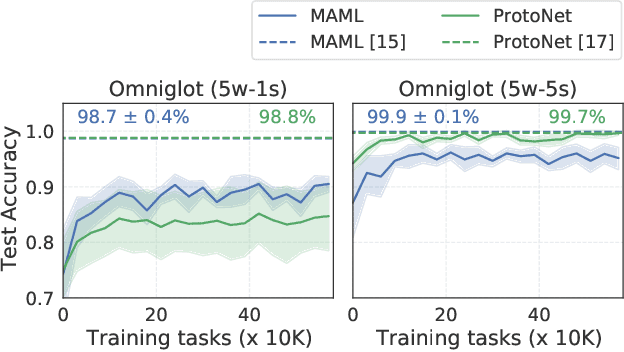
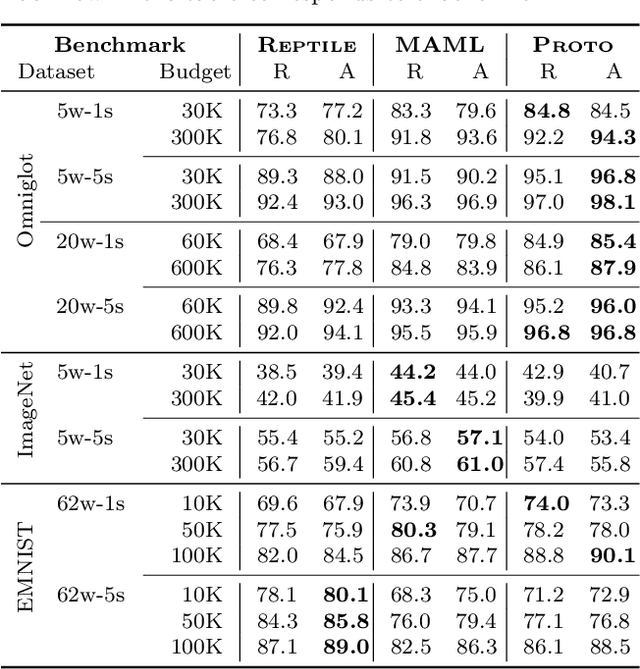

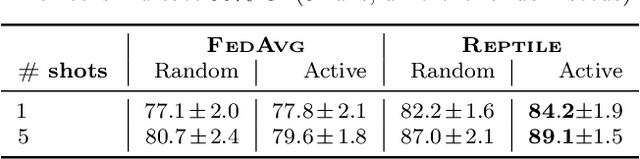
Meta-learning has enabled learning statistical models that can be quickly adapted to new prediction tasks. Motivated by use-cases in personalized federated learning, we study the often overlooked aspect of the modern meta-learning algorithms -- their data efficiency. To shed more light on which methods are more efficient, we use techniques from algorithmic stability to derive bounds on the transfer risk that have important practical implications, indicating how much supervision is needed and how it must be allocated for each method to attain the desired level of generalization. Further, we introduce a new simple framework for evaluating meta-learning methods under a limit on the available supervision, conduct an empirical study of MAML, Reptile, and Protonets, and demonstrate the differences in the behavior of these methods on few-shot and federated learning benchmarks. Finally, we propose active meta-learning, which incorporates active data selection into learning-to-learn, leading to better performance of all methods in the limited supervision regime.