 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuRA: Towards General Goal-Oriented Agent via Simulative Reasoning Architecture with LLM-Based World Model
Jul 31, 2025



AI agents built on large language models (LLMs) hold enormous promise, but current practice focuses on a one-task-one-agent approach, which not only falls short of scalability and generality, but also suffers from the fundamental limitations of autoregressive LLMs. On the other hand, humans are general agents who reason by mentally simulating the outcomes of their actions and plans. Moving towards a more general and powerful AI agent, we introduce SimuRA, a goal-oriented architecture for generalized agentic reasoning. Based on a principled formulation of optimal agent in any environment, \modelname overcomes the limitations of autoregressive reasoning by introducing a world model for planning via simulation. The generalized world model is implemented using LLM, which can flexibly plan in a wide range of environments using the concept-rich latent space of natural language. Experiments on difficult web browsing tasks show that \modelname improves the success of flight search from 0\% to 32.2\%. World-model-based planning, in particular, shows consistent advantage of up to 124\% over autoregressive planning, demonstrating the advantage of world model simulation as a reasoning paradigm. We are excited about the possibility for training a single, general agent model based on LLMs that can act superintelligently in all environments. To start, we make SimuRA, a web-browsing agent built on \modelname with pretrained LLMs, available as a research demo for public testing.
Global and Local Entailment Learning for Natural World Imagery
Jun 26, 2025Learning the hierarchical structure of data in vision-language models is a significant challenge. Previous works have attempted to address this challenge by employing entailment learning. However, these approaches fail to model the transitive nature of entailment explicitly, which establishes the relationship between order and semantics within a representation space. In this work, we introduce Radial Cross-Modal Embeddings (RCME), a framework that enables the explicit modeling of transitivity-enforced entailment. Our proposed framework optimizes for the partial order of concepts within vision-language models. By leveraging our framework, we develop a hierarchical vision-language foundation model capable of representing the hierarchy in the Tree of Life. Our experiments on hierarchical species classification and hierarchical retrieval tasks demonstrate the enhanced performance of our models compared to the existing state-of-the-art models. Our code and models are open-sourced at https://vishu26.github.io/RCME/index.html.
Pruning Spurious Subgraphs for Graph Out-of-Distribtuion Generalization
Jun 06, 2025Graph Neural Networks (GNNs) often encounter significant performance degradation under distribution shifts between training and test data, hindering their applicability in real-world scenarios. Recent studies have proposed various methods to address the out-of-distribution generalization challenge, with many methods in the graph domain focusing on directly identifying an invariant subgraph that is predictive of the target label. However, we argue that identifying the edges from the invariant subgraph directly is challenging and error-prone, especially when some spurious edges exhibit strong correlations with the targets. In this paper, we propose PrunE, the first pruning-based graph OOD method that eliminates spurious edges to improve OOD generalizability. By pruning spurious edges, \mine{} retains the invariant subgraph more comprehensively, which is critical for OOD generalization. Specifically, PrunE employs two regularization terms to prune spurious edges: 1) graph size constraint to exclude uninformative spurious edges, and 2) $\epsilon$-probability alignment to further suppress the occurrence of spurious edges. Through theoretical analysis and extensive experiments, we show that PrunE achieves superior OOD performance and outperforms previous state-of-the-art methods significantly. Codes are available at: \href{https://github.com/tianyao-aka/PrunE-GraphOOD}{https://github.com/tianyao-aka/PrunE-GraphOOD}.
ConText-CIR: Learning from Concepts in Text for Composed Image Retrieval
May 27, 2025
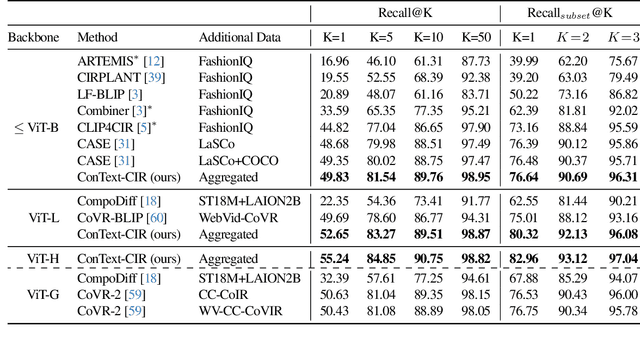

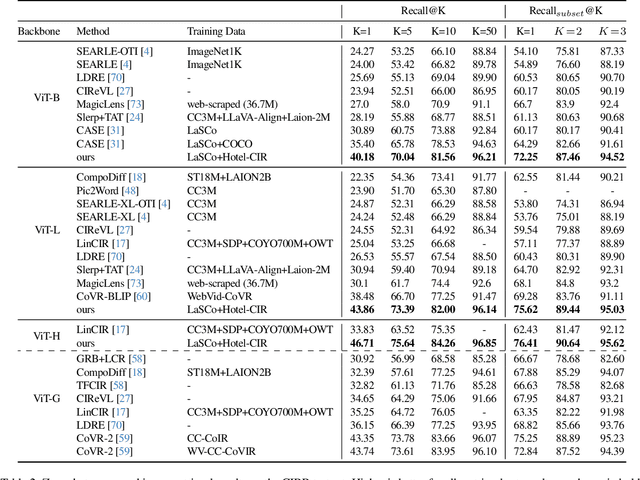
Composed image retrieval (CIR) is the task of retrieving a target image specified by a query image and a relative text that describes a semantic modification to the query image. Existing methods in CIR struggle to accurately represent the image and the text modification, resulting in subpar performance. To address this limitation, we introduce a CIR framework, ConText-CIR, trained with a Text Concept-Consistency loss that encourages the representations of noun phrases in the text modification to better attend to the relevant parts of the query image. To support training with this loss function, we also propose a synthetic data generation pipeline that creates training data from existing CIR datasets or unlabeled images. We show that these components together enable stronger performance on CIR tasks, setting a new state-of-the-art in composed image retrieval in both the supervised and zero-shot settings on multiple benchmark datasets, including CIRR and CIRCO. Source code, model checkpoints, and our new datasets are available at https://github.com/mvrl/ConText-CIR.
QuARI: Query Adaptive Retrieval Improvement
May 27, 2025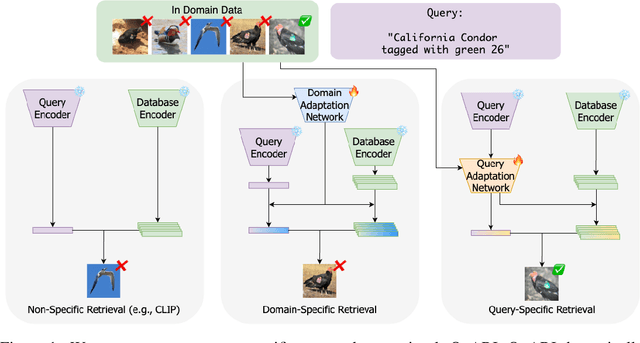
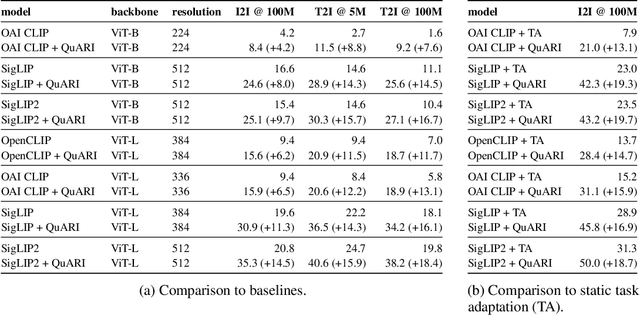
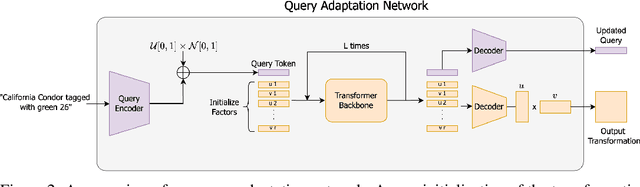
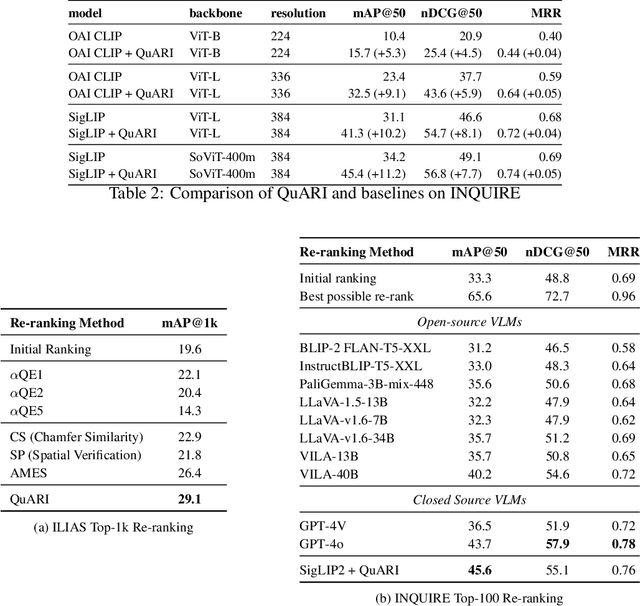
Massive-scale pretraining has made vision-language models increasingly popular for image-to-image and text-to-image retrieval across a broad collection of domains. However, these models do not perform well when used for challenging retrieval tasks, such as instance retrieval in very large-scale image collections. Recent work has shown that linear transformations of VLM features trained for instance retrieval can improve performance by emphasizing subspaces that relate to the domain of interest. In this paper, we explore a more extreme version of this specialization by learning to map a given query to a query-specific feature space transformation. Because this transformation is linear, it can be applied with minimal computational cost to millions of image embeddings, making it effective for large-scale retrieval or re-ranking. Results show that this method consistently outperforms state-of-the-art alternatives, including those that require many orders of magnitude more computation at query time.
Understanding the Skill Gap in Recurrent Language Models: The Role of the Gather-and-Aggregate Mechanism
Apr 22, 2025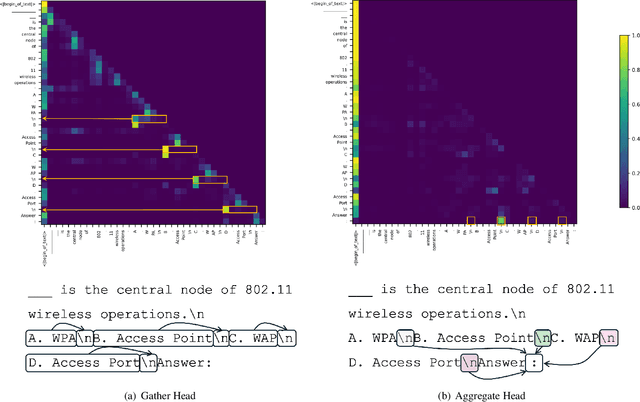



SSMs offer efficient processing of long sequences with fixed state sizes, but struggle with algorithmic tasks like retrieving past context. In this work, we examine how such in-context retrieval operates within Transformer- and SSM-based language models. We find that both architectures develop the same fundamental Gather-and-Aggregate (G&A) mechanism. A Gather Head first identifies and extracts relevant information from the context, which an Aggregate Head then integrates into a final representation. Across both model types, G&A concentrates in just a few heads, making them critical bottlenecks even for benchmarks that require a basic form of retrieval. For example, disabling a single Gather or Aggregate Head of a pruned Llama-3.1-8B degrades its ability to retrieve the correct answer letter in MMLU, reducing accuracy from 66% to 25%. This finding suggests that in-context retrieval can obscure the limited knowledge demands of certain tasks. Despite strong MMLU performance with retrieval intact, the pruned model fails on other knowledge tests. Similar G&A dependencies exist in GSM8K, BBH, and dialogue tasks. Given the significance of G&A in performance, we show that retrieval challenges in SSMs manifest in how they implement G&A, leading to smoother attention patterns rather than the sharp token transitions that effective G&A relies on. Thus, while a gap exists between Transformers and SSMs in implementing in-context retrieval, it is confined to a few heads, not the entire model. This insight suggests a unified explanation for performance differences between Transformers and SSMs while also highlighting ways to combine their strengths. For example, in pretrained hybrid models, attention components naturally take on the role of Aggregate Heads. Similarly, in a pretrained pure SSM, replacing a single G&A head with an attention-based variant significantly improves retrieval.
Token Level Routing Inference System for Edge Devices
Apr 10, 2025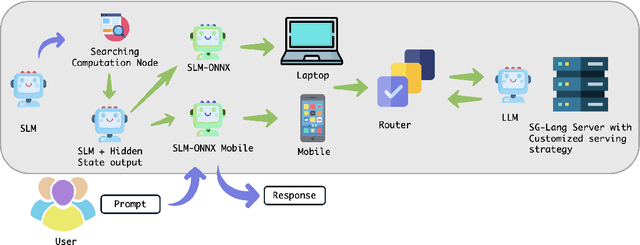
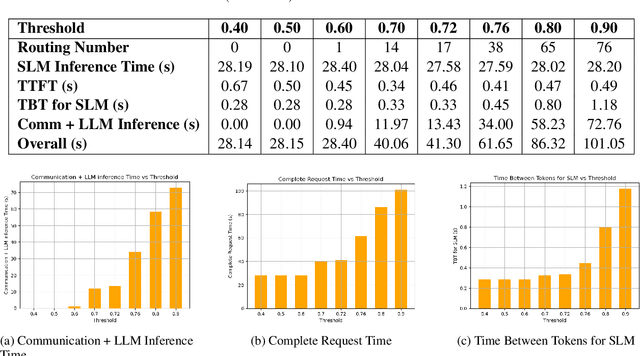
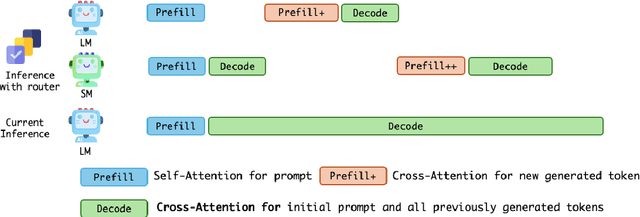
The computational complexity of large language model (LLM) inference significantly constrains their deployment efficiency on edge devices. In contrast, small language models offer faster decoding and lower resource consumption but often suffer from degraded response quality and heightened susceptibility to hallucinations. To address this trade-off, collaborative decoding, in which a large model assists in generating critical tokens, has emerged as a promising solution. This paradigm leverages the strengths of both model types by enabling high-quality inference through selective intervention of the large model, while maintaining the speed and efficiency of the smaller model. In this work, we present a novel collaborative decoding inference system that allows small models to perform on-device inference while selectively consulting a cloud-based large model for critical token generation. Remarkably, the system achieves a 60% performance gain on CommonsenseQA using only a 0.5B model on an M1 MacBook, with under 7% of tokens generation uploaded to the large model in the cloud.
GenStereo: Towards Open-World Generation of Stereo Images and Unsupervised Matching
Mar 17, 2025Stereo images are fundamental to numerous applications, including extended reality (XR) devices, autonomous driving, and robotics. Unfortunately, acquiring high-quality stereo images remains challenging due to the precise calibration requirements of dual-camera setups and the complexity of obtaining accurate, dense disparity maps. Existing stereo image generation methods typically focus on either visual quality for viewing or geometric accuracy for matching, but not both. We introduce GenStereo, a diffusion-based approach, to bridge this gap. The method includes two primary innovations (1) conditioning the diffusion process on a disparity-aware coordinate embedding and a warped input image, allowing for more precise stereo alignment than previous methods, and (2) an adaptive fusion mechanism that intelligently combines the diffusion-generated image with a warped image, improving both realism and disparity consistency. Through extensive training on 11 diverse stereo datasets, GenStereo demonstrates strong generalization ability. GenStereo achieves state-of-the-art performance in both stereo image generation and unsupervised stereo matching tasks. Our framework eliminates the need for complex hardware setups while enabling high-quality stereo image generation, making it valuable for both real-world applications and unsupervised learning scenarios. Project page is available at https://qjizhi.github.io/genstereo
Synthesizing Privacy-Preserving Text Data via Finetuning without Finetuning Billion-Scale LLMs
Mar 16, 2025Synthetic data offers a promising path to train models while preserving data privacy. Differentially private (DP) finetuning of large language models (LLMs) as data generator is effective, but is impractical when computation resources are limited. Meanwhile, prompt-based methods such as private evolution, depend heavily on the manual prompts, and ineffectively use private information in their iterative data selection process. To overcome these limitations, we propose CTCL (Data Synthesis with ConTrollability and CLustering), a novel framework for generating privacy-preserving synthetic data without extensive prompt engineering or billion-scale LLM finetuning. CTCL pretrains a lightweight 140M conditional generator and a clustering-based topic model on large-scale public data. To further adapt to the private domain, the generator is DP finetuned on private data for fine-grained textual information, while the topic model extracts a DP histogram representing distributional information. The DP generator then samples according to the DP histogram to synthesize a desired number of data examples. Evaluation across five diverse domains demonstrates the effectiveness of our framework, particularly in the strong privacy regime. Systematic ablation validates the design of each framework component and highlights the scalability of our approach.
RANGE: Retrieval Augmented Neural Fields for Multi-Resolution Geo-Embeddings
Feb 27, 2025The choice of representation for geographic location significantly impacts the accuracy of models for a broad range of geospatial tasks, including fine-grained species classification, population density estimation, and biome classification. Recent works like SatCLIP and GeoCLIP learn such representations by contrastively aligning geolocation with co-located images. While these methods work exceptionally well, in this paper, we posit that the current training strategies fail to fully capture the important visual features. We provide an information theoretic perspective on why the resulting embeddings from these methods discard crucial visual information that is important for many downstream tasks. To solve this problem, we propose a novel retrieval-augmented strategy called RANGE. We build our method on the intuition that the visual features of a location can be estimated by combining the visual features from multiple similar-looking locations. We evaluate our method across a wide variety of tasks. Our results show that RANGE outperforms the existing state-of-the-art models with significant margins in most tasks. We show gains of up to 13.1\% on classification tasks and 0.145 $R^2$ on regression tasks. All our code will be released on GitHub. Our models will be released on HuggingFace.