 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiT: Point-Conditioned Diffusion Transformer for Satellite Image Synthesis
Mar 02, 2026We introduce GeoDiT, a diffusion transformer designed for text-to-satellite image generation with point-based control. Existing controlled satellite image generative models often require pixel-level maps that are time-consuming to acquire, yet semantically limited. To address this limitation, we introduce a novel point-based conditioning framework that controls the generation process through the spatial location of the points and the textual description associated with each point, providing semantically rich control signals. This approach enables flexible, annotation-friendly, and computationally simple inference for satellite image generation. To this end, we introduce an adaptive local attention mechanism that effectively regularizes the attention scores based on the input point queries. We systematically evaluate various domain-specific design choices for training GeoDiT, including the selection of satellite image representation for alignment and geolocation representation for conditioning. Our experiments demonstrate that GeoDiT achieves impressive generation performance, surpassing the state-of-the-art remote sensing generative models.
SimLBR: Learning to Detect Fake Images by Learning to Detect Real Images
Feb 23, 2026The rapid advancement of generative models has made the detection of AI-generated images a critical challenge for both research and society. Recent works have shown that most state-of-the-art fake image detection methods overfit to their training data and catastrophically fail when evaluated on curated hard test sets with strong distribution shifts. In this work, we argue that it is more principled to learn a tight decision boundary around the real image distribution and treat the fake category as a sink class. To this end, we propose SimLBR, a simple and efficient framework for fake image detection using Latent Blending Regularization (LBR). Our method significantly improves cross-generator generalization, achieving up to +24.85\% accuracy and +69.62\% recall on the challenging Chameleon benchmark. SimLBR is also highly efficient, training orders of magnitude faster than existing approaches. Furthermore, we emphasize the need for reliability-oriented evaluation in fake image detection, introducing risk-adjusted metrics and worst-case estimates to better assess model robustness. All code and models will be released on HuggingFace and GitHub.
VectorSynth: Fine-Grained Satellite Image Synthesis with Structured Semantics
Nov 11, 2025We introduce VectorSynth, a diffusion-based framework for pixel-accurate satellite image synthesis conditioned on polygonal geographic annotations with semantic attributes. Unlike prior text- or layout-conditioned models, VectorSynth learns dense cross-modal correspondences that align imagery and semantic vector geometry, enabling fine-grained, spatially grounded edits. A vision language alignment module produces pixel-level embeddings from polygon semantics; these embeddings guide a conditional image generation framework to respect both spatial extents and semantic cues. VectorSynth supports interactive workflows that mix language prompts with geometry-aware conditioning, allowing rapid what-if simulations, spatial edits, and map-informed content generation. For training and evaluation, we assemble a collection of satellite scenes paired with pixel-registered polygon annotations spanning diverse urban scenes with both built and natural features. We observe strong improvements over prior methods in semantic fidelity and structural realism, and show that our trained vision language model demonstrates fine-grained spatial grounding. The code and data are available at https://github.com/mvrl/VectorSynth.
Global and Local Entailment Learning for Natural World Imagery
Jun 26, 2025Learning the hierarchical structure of data in vision-language models is a significant challenge. Previous works have attempted to address this challenge by employing entailment learning. However, these approaches fail to model the transitive nature of entailment explicitly, which establishes the relationship between order and semantics within a representation space. In this work, we introduce Radial Cross-Modal Embeddings (RCME), a framework that enables the explicit modeling of transitivity-enforced entailment. Our proposed framework optimizes for the partial order of concepts within vision-language models. By leveraging our framework, we develop a hierarchical vision-language foundation model capable of representing the hierarchy in the Tree of Life. Our experiments on hierarchical species classification and hierarchical retrieval tasks demonstrate the enhanced performance of our models compared to the existing state-of-the-art models. Our code and models are open-sourced at https://vishu26.github.io/RCME/index.html.
Sat2Sound: A Unified Framework for Zero-Shot Soundscape Mapping
May 19, 2025We present Sat2Sound, a multimodal representation learning framework for soundscape mapping, designed to predict the distribution of sounds at any location on Earth. Existing methods for this task rely on satellite image and paired geotagged audio samples, which often fail to capture the diversity of sound sources at a given location. To address this limitation, we enhance existing datasets by leveraging a Vision-Language Model (VLM) to generate semantically rich soundscape descriptions for locations depicted in satellite images. Our approach incorporates contrastive learning across audio, audio captions, satellite images, and satellite image captions. We hypothesize that there is a fixed set of soundscape concepts shared across modalities. To this end, we learn a shared codebook of soundscape concepts and represent each sample as a weighted average of these concepts. Sat2Sound achieves state-of-the-art performance in cross-modal retrieval between satellite image and audio on two datasets: GeoSound and SoundingEarth. Additionally, building on Sat2Sound's ability to retrieve detailed soundscape captions, we introduce a novel application: location-based soundscape synthesis, which enables immersive acoustic experiences. Our code and models will be publicly available.
RANGE: Retrieval Augmented Neural Fields for Multi-Resolution Geo-Embeddings
Feb 27, 2025The choice of representation for geographic location significantly impacts the accuracy of models for a broad range of geospatial tasks, including fine-grained species classification, population density estimation, and biome classification. Recent works like SatCLIP and GeoCLIP learn such representations by contrastively aligning geolocation with co-located images. While these methods work exceptionally well, in this paper, we posit that the current training strategies fail to fully capture the important visual features. We provide an information theoretic perspective on why the resulting embeddings from these methods discard crucial visual information that is important for many downstream tasks. To solve this problem, we propose a novel retrieval-augmented strategy called RANGE. We build our method on the intuition that the visual features of a location can be estimated by combining the visual features from multiple similar-looking locations. We evaluate our method across a wide variety of tasks. Our results show that RANGE outperforms the existing state-of-the-art models with significant margins in most tasks. We show gains of up to 13.1\% on classification tasks and 0.145 $R^2$ on regression tasks. All our code will be released on GitHub. Our models will be released on HuggingFace.
TaxaBind: A Unified Embedding Space for Ecological Applications
Nov 01, 2024
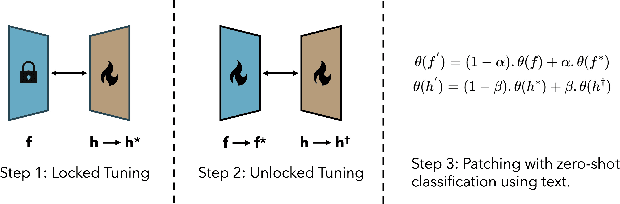

We present TaxaBind, a unified embedding space for characterizing any species of interest. TaxaBind is a multimodal embedding space across six modalities: ground-level images of species, geographic location, satellite image, text, audio, and environmental features, useful for solving ecological problems. To learn this joint embedding space, we leverage ground-level images of species as a binding modality. We propose multimodal patching, a technique for effectively distilling the knowledge from various modalities into the binding modality. We construct two large datasets for pretraining: iSatNat with species images and satellite images, and iSoundNat with species images and audio. Additionally, we introduce TaxaBench-8k, a diverse multimodal dataset with six paired modalities for evaluating deep learning models on ecological tasks. Experiments with TaxaBind demonstrate its strong zero-shot and emergent capabilities on a range of tasks including species classification, cross-model retrieval, and audio classification. The datasets and models are made available at https://github.com/mvrl/TaxaBind.
PSM: Learning Probabilistic Embeddings for Multi-scale Zero-Shot Soundscape Mapping
Aug 13, 2024A soundscape is defined by the acoustic environment a person perceives at a location. In this work, we propose a framework for mapping soundscapes across the Earth. Since soundscapes involve sound distributions that span varying spatial scales, we represent locations with multi-scale satellite imagery and learn a joint representation among this imagery, audio, and text. To capture the inherent uncertainty in the soundscape of a location, we design the representation space to be probabilistic. We also fuse ubiquitous metadata (including geolocation, time, and data source) to enable learning of spatially and temporally dynamic representations of soundscapes. We demonstrate the utility of our framework by creating large-scale soundscape maps integrating both audio and text with temporal control. To facilitate future research on this task, we also introduce a large-scale dataset, GeoSound, containing over $300k$ geotagged audio samples paired with both low- and high-resolution satellite imagery. We demonstrate that our method outperforms the existing state-of-the-art on both GeoSound and the existing SoundingEarth dataset. Our dataset and code is available at https://github.com/mvrl/PSM.
GOMAA-Geo: GOal Modality Agnostic Active Geo-localization
Jun 04, 2024



We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. This could emulate a UAV involved in a search-and-rescue operation navigating through an area, observing a stream of aerial images as it goes. The AGL task is associated with two important challenges. Firstly, an agent must deal with a goal specification in one of multiple modalities (e.g., through a natural language description) while the search cues are provided in other modalities (aerial imagery). The second challenge is limited localization time (e.g., limited battery life, urgency) so that the goal must be localized as efficiently as possible, i.e. the agent must effectively leverage its sequentially observed aerial views when searching for the goal. To address these challenges, we propose GOMAA-Geo - a goal modality agnostic active geo-localization agent - for zero-shot generalization between different goal modalities. Our approach combines cross-modality contrastive learning to align representations across modalities with supervised foundation model pretraining and reinforcement learning to obtain highly effective navigation and localization policies. Through extensive evaluations, we show that GOMAA-Geo outperforms alternative learnable approaches and that it generalizes across datasets - e.g., to disaster-hit areas without seeing a single disaster scenario during training - and goal modalities - e.g., to ground-level imagery or textual descriptions, despite only being trained with goals specified as aerial views. Code and models are publicly available at https://github.com/mvrl/GOMAA-Geo/tree/main.
GEOBIND: Binding Text, Image, and Audio through Satellite Images
Apr 17, 2024In remote sensing, we are interested in modeling various modalities for some geographic location. Several works have focused on learning the relationship between a location and type of landscape, habitability, audio, textual descriptions, etc. Recently, a common way to approach these problems is to train a deep-learning model that uses satellite images to infer some unique characteristics of the location. In this work, we present a deep-learning model, GeoBind, that can infer about multiple modalities, specifically text, image, and audio, from satellite imagery of a location. To do this, we use satellite images as the binding element and contrastively align all other modalities to the satellite image data. Our training results in a joint embedding space with multiple types of data: satellite image, ground-level image, audio, and text. Furthermore, our approach does not require a single complex dataset that contains all the modalities mentioned above. Rather it only requires multiple satellite-image paired data. While we only align three modalities in this paper, we present a general framework that can be used to create an embedding space with any number of modalities by using satellite images as the binding element. Our results show that, unlike traditional unimodal models, GeoBind is versatile and can reason about multiple modalities for a given satellite image input.