 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrazing Detection using Deep Learning and Sentinel-2 Time Series Data
Oct 16, 2025Grazing shapes both agricultural production and biodiversity, yet scalable monitoring of where grazing occurs remains limited. We study seasonal grazing detection from Sentinel-2 L2A time series: for each polygon-defined field boundary, April-October imagery is used for binary prediction (grazed / not grazed). We train an ensemble of CNN-LSTM models on multi-temporal reflectance features, and achieve an average F1 score of 77 percent across five validation splits, with 90 percent recall on grazed pastures. Operationally, if inspectors can visit at most 4 percent of sites annually, prioritising fields predicted by our model as non-grazed yields 17.2 times more confirmed non-grazing sites than random inspection. These results indicate that coarse-resolution, freely available satellite data can reliably steer inspection resources for conservation-aligned land-use compliance. Code and models have been made publicly available.
GOMAA-Geo: GOal Modality Agnostic Active Geo-localization
Jun 04, 2024



We consider the task of active geo-localization (AGL) in which an agent uses a sequence of visual cues observed during aerial navigation to find a target specified through multiple possible modalities. This could emulate a UAV involved in a search-and-rescue operation navigating through an area, observing a stream of aerial images as it goes. The AGL task is associated with two important challenges. Firstly, an agent must deal with a goal specification in one of multiple modalities (e.g., through a natural language description) while the search cues are provided in other modalities (aerial imagery). The second challenge is limited localization time (e.g., limited battery life, urgency) so that the goal must be localized as efficiently as possible, i.e. the agent must effectively leverage its sequentially observed aerial views when searching for the goal. To address these challenges, we propose GOMAA-Geo - a goal modality agnostic active geo-localization agent - for zero-shot generalization between different goal modalities. Our approach combines cross-modality contrastive learning to align representations across modalities with supervised foundation model pretraining and reinforcement learning to obtain highly effective navigation and localization policies. Through extensive evaluations, we show that GOMAA-Geo outperforms alternative learnable approaches and that it generalizes across datasets - e.g., to disaster-hit areas without seeing a single disaster scenario during training - and goal modalities - e.g., to ground-level imagery or textual descriptions, despite only being trained with goals specified as aerial views. Code and models are publicly available at https://github.com/mvrl/GOMAA-Geo/tree/main.
Flexible SE(2) graph neural networks with applications to PDE surrogates
May 30, 2024



This paper presents a novel approach for constructing graph neural networks equivariant to 2D rotations and translations and leveraging them as PDE surrogates on non-gridded domains. We show that aligning the representations with the principal axis allows us to sidestep many constraints while preserving SE(2) equivariance. By applying our model as a surrogate for fluid flow simulations and conducting thorough benchmarks against non-equivariant models, we demonstrate significant gains in terms of both data efficiency and accuracy.
Impacts of Color and Texture Distortions on Earth Observation Data in Deep Learning
Mar 07, 2024



Land cover classification and change detection are two important applications of remote sensing and Earth observation (EO) that have benefited greatly from the advances of deep learning. Convolutional and transformer-based U-net models are the state-of-the-art architectures for these tasks, and their performances have been boosted by an increased availability of large-scale annotated EO datasets. However, the influence of different visual characteristics of the input EO data on a model's predictions is not well understood. In this work we systematically examine model sensitivities with respect to several color- and texture-based distortions on the input EO data during inference, given models that have been trained without such distortions. We conduct experiments with multiple state-of-the-art segmentation networks for land cover classification and show that they are in general more sensitive to texture than to color distortions. Beyond revealing intriguing characteristics of widely used land cover classification models, our results can also be used to guide the development of more robust models within the EO domain.
Creating and Benchmarking a Synthetic Dataset for Cloud Optical Thickness Estimation
Nov 23, 2023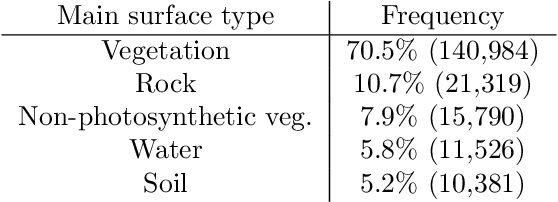
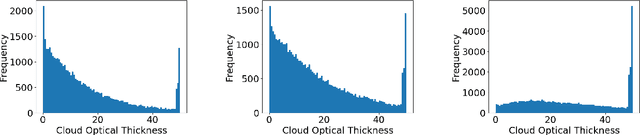
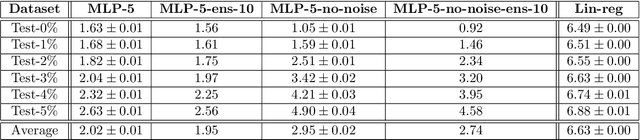
Cloud formations often obscure optical satellite-based monitoring of the Earth's surface, thus limiting Earth observation (EO) activities such as land cover mapping, ocean color analysis, and cropland monitoring. The integration of machine learning (ML) methods within the remote sensing domain has significantly improved performance on a wide range of EO tasks, including cloud detection and filtering, but there is still much room for improvement. A key bottleneck is that ML methods typically depend on large amounts of annotated data for training, which is often difficult to come by in EO contexts. This is especially true for the task of cloud optical thickness (COT) estimation. A reliable estimation of COT enables more fine-grained and application-dependent control compared to using pre-specified cloud categories, as is commonly done in practice. To alleviate the COT data scarcity problem, in this work we propose a novel synthetic dataset for COT estimation, where top-of-atmosphere radiances have been simulated for 12 of the spectral bands of the Multi-Spectral Instrument (MSI) sensor onboard Sentinel-2 platforms. These data points have been simulated under consideration of different cloud types, COTs, and ground surface and atmospheric profiles. Extensive experimentation of training several ML models to predict COT from the measured reflectivity of the spectral bands demonstrates the usefulness of our proposed dataset. Generalization to real data is also demonstrated on two satellite image datasets -- one that is publicly available, and one which we have collected and annotated. The synthetic data, the newly collected real dataset, code and models have been made publicly available at https://github.com/aleksispi/ml-cloud-opt-thick.
Fully Convolutional Networks for Dense Water Flow Intensity Prediction in Swedish Catchment Areas
Apr 04, 2023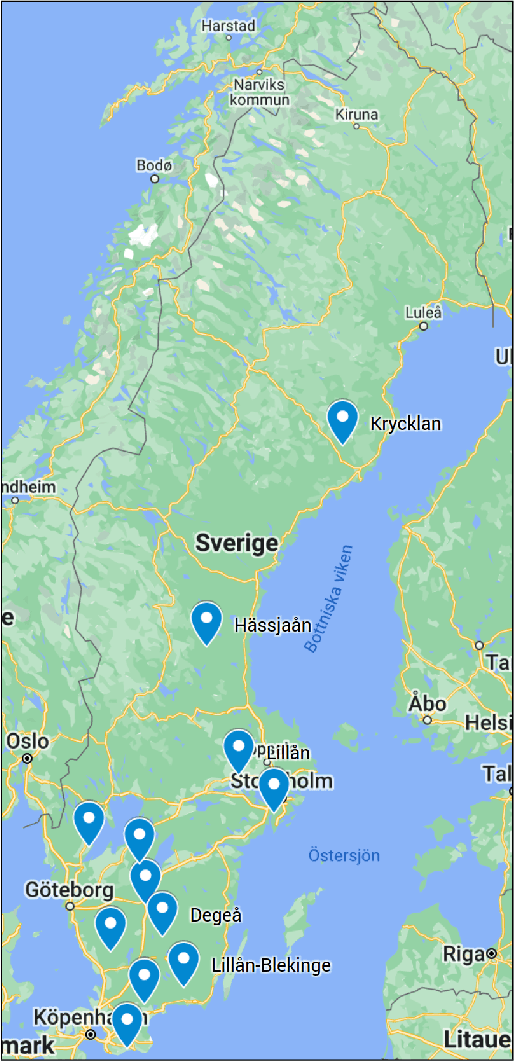
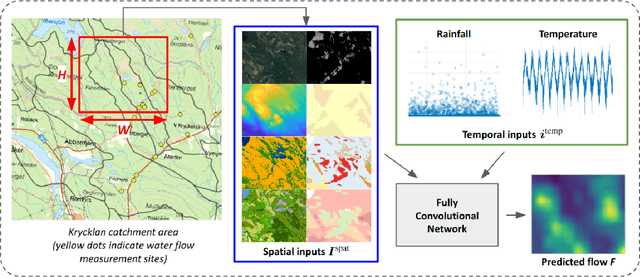
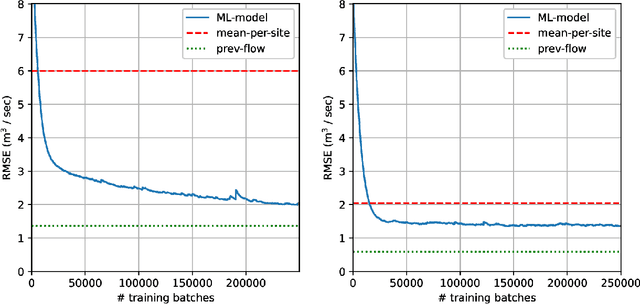
Intensifying climate change will lead to more extreme weather events, including heavy rainfall and drought. Accurate stream flow prediction models which are adaptable and robust to new circumstances in a changing climate will be an important source of information for decisions on climate adaptation efforts, especially regarding mitigation of the risks of and damages associated with flooding. In this work we propose a machine learning-based approach for predicting water flow intensities in inland watercourses based on the physical characteristics of the catchment areas, obtained from geospatial data (including elevation and soil maps, as well as satellite imagery), in addition to temporal information about past rainfall quantities and temperature variations. We target the one-day-ahead regime, where a fully convolutional neural network model receives spatio-temporal inputs and predicts the water flow intensity in every coordinate of the spatial input for the subsequent day. To the best of our knowledge, we are the first to tackle the task of dense water flow intensity prediction; earlier works have considered predicting flow intensities at a sparse set of locations at a time. An extensive set of model evaluations and ablations are performed, which empirically justify our various design choices. Code and preprocessed data have been made publicly available at https://github.com/aleksispi/fcn-water-flow.
Aerial View Goal Localization with Reinforcement Learning
Sep 08, 2022
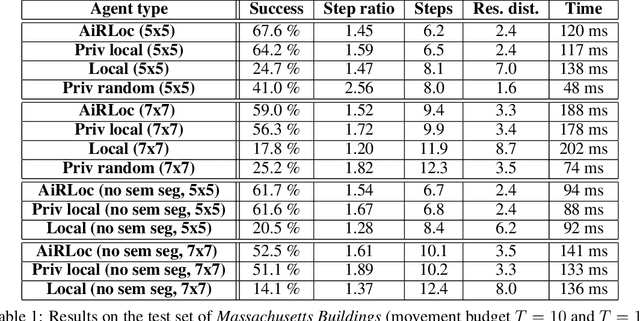
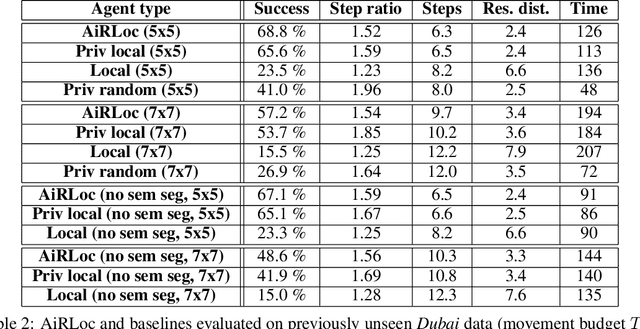
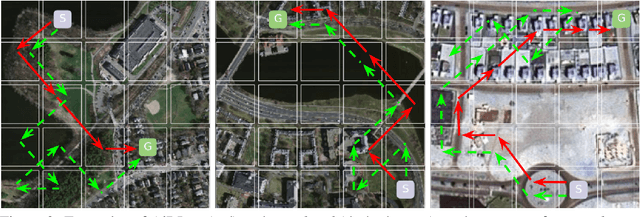
With an increased amount and availability of unmanned aerial vehicles (UAVs) and other remote sensing devices (e.g. satellites), we have recently seen a vast increase in computer vision methods for aerial view data. One application of such technologies is within search-and-rescue (SAR), where the task is to localize and assist one or several people who are missing, for example after a natural disaster. In many cases the rough location may be known and a UAV can be deployed to explore a given, confined area to precisely localize the missing people. Due to time and battery constraints it is often critical that localization is performed as efficiently as possible. In this work, we approach this type of problem by abstracting it as an aerial view goal localization task in a framework that emulates a SAR-like setup without requiring access to actual UAVs. In this framework, an agent operates on top of an aerial image (proxy for a search area) and is tasked with localizing a goal that is described in terms of visual cues. To further mimic the situation on an actual UAV, the agent is not able to observe the search area in its entirety, not even at low resolution, and thus it has to operate solely based on partial glimpses when navigating towards the goal. To tackle this task, we propose AiRLoc, a reinforcement learning (RL)-based model that decouples exploration (searching for distant goals) and exploitation (localizing nearby goals). Extensive evaluations show that AiRLoc outperforms heuristic search methods as well as alternative learnable approaches. We also conduct a proof-of-concept study which indicates that the learnable methods outperform humans on average. Code has been made publicly available: https://github.com/aleksispi/airloc.
Embodied Learning for Lifelong Visual Perception
Dec 28, 2021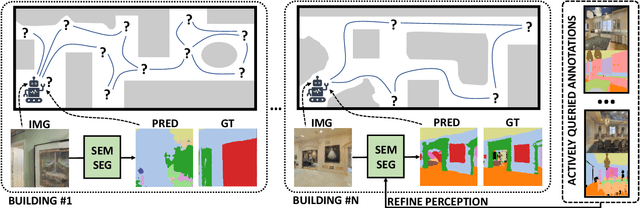
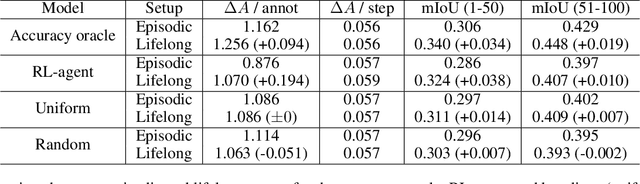
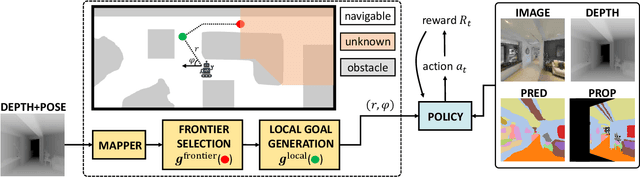

We study lifelong visual perception in an embodied setup, where we develop new models and compare various agents that navigate in buildings and occasionally request annotations which, in turn, are used to refine their visual perception capabilities. The purpose of the agents is to recognize objects and other semantic classes in the whole building at the end of a process that combines exploration and active visual learning. As we study this task in a lifelong learning context, the agents should use knowledge gained in earlier visited environments in order to guide their exploration and active learning strategy in successively visited buildings. We use the semantic segmentation performance as a proxy for general visual perception and study this novel task for several exploration and annotation methods, ranging from frontier exploration baselines which use heuristic active learning, to a fully learnable approach. For the latter, we introduce a deep reinforcement learning (RL) based agent which jointly learns both navigation and active learning. A point goal navigation formulation, coupled with a global planner which supplies goals, is integrated into the RL model in order to provide further incentives for systematic exploration of novel scenes. By performing extensive experiments on the Matterport3D dataset, we show how the proposed agents can utilize knowledge from previously explored scenes when exploring new ones, e.g. through less granular exploration and less frequent requests for annotations. The results also suggest that a learning-based agent is able to use its prior visual knowledge more effectively than heuristic alternatives.
Embodied Visual Active Learning for Semantic Segmentation
Dec 17, 2020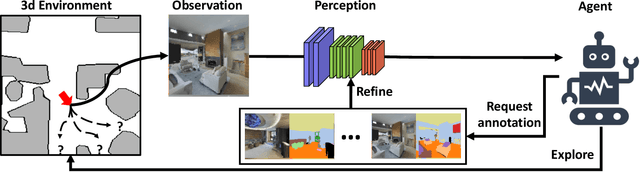
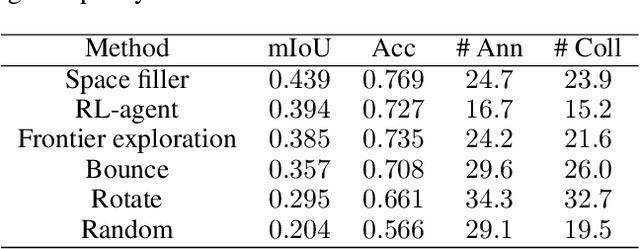
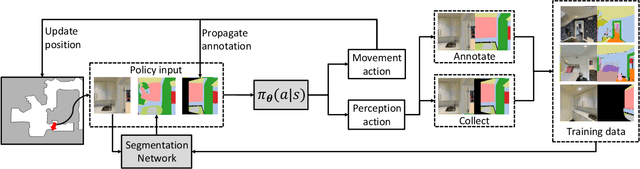
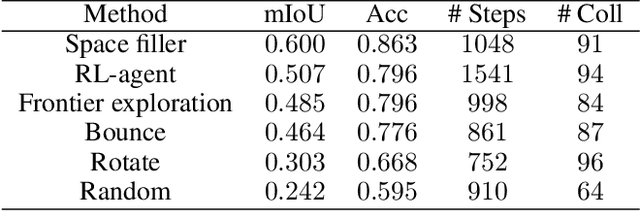
We study the task of embodied visual active learning, where an agent is set to explore a 3d environment with the goal to acquire visual scene understanding by actively selecting views for which to request annotation. While accurate on some benchmarks, today's deep visual recognition pipelines tend to not generalize well in certain real-world scenarios, or for unusual viewpoints. Robotic perception, in turn, requires the capability to refine the recognition capabilities for the conditions where the mobile system operates, including cluttered indoor environments or poor illumination. This motivates the proposed task, where an agent is placed in a novel environment with the objective of improving its visual recognition capability. To study embodied visual active learning, we develop a battery of agents - both learnt and pre-specified - and with different levels of knowledge of the environment. The agents are equipped with a semantic segmentation network and seek to acquire informative views, move and explore in order to propagate annotations in the neighbourhood of those views, then refine the underlying segmentation network by online retraining. The trainable method uses deep reinforcement learning with a reward function that balances two competing objectives: task performance, represented as visual recognition accuracy, which requires exploring the environment, and the necessary amount of annotated data requested during active exploration. We extensively evaluate the proposed models using the photorealistic Matterport3D simulator and show that a fully learnt method outperforms comparable pre-specified counterparts, even when requesting fewer annotations.
Deep Reinforcement Learning for Active Human Pose Estimation
Jan 07, 2020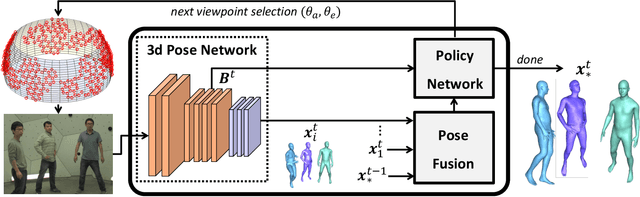

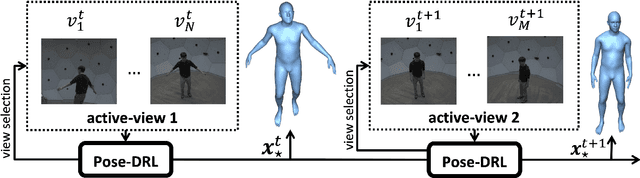

Most 3d human pose estimation methods assume that input -- be it images of a scene collected from one or several viewpoints, or from a video -- is given. Consequently, they focus on estimates leveraging prior knowledge and measurement by fusing information spatially and/or temporally, whenever available. In this paper we address the problem of an active observer with freedom to move and explore the scene spatially -- in `time-freeze' mode -- and/or temporally, by selecting informative viewpoints that improve its estimation accuracy. Towards this end, we introduce Pose-DRL, a fully trainable deep reinforcement learning-based active pose estimation architecture which learns to select appropriate views, in space and time, to feed an underlying monocular pose estimator. We evaluate our model using single- and multi-target estimators with strong result in both settings. Our system further learns automatic stopping conditions in time and transition functions to the next temporal processing step in videos. In extensive experiments with the Panoptic multi-view setup, and for complex scenes containing multiple people, we show that our model learns to select viewpoints that yield significantly more accurate pose estimates compared to strong multi-view baselines.