 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Consistency Refinement for Single Image Novel View Synthesis via Test-Time Adaptation of Diffusion Models
Apr 11, 2025Diffusion models for single image novel view synthesis (NVS) can generate highly realistic and plausible images, but they are limited in the geometric consistency to the given relative poses. The generated images often show significant errors with respect to the epipolar constraints that should be fulfilled, as given by the target pose. In this paper we address this issue by proposing a methodology to improve the geometric correctness of images generated by a diffusion model for single image NVS. We formulate a loss function based on image matching and epipolar constraints, and optimize the starting noise in a diffusion sampling process such that the generated image should both be a realistic image and fulfill geometric constraints derived from the given target pose. Our method does not require training data or fine-tuning of the diffusion models, and we show that we can apply it to multiple state-of-the-art models for single image NVS. The method is evaluated on the MegaScenes dataset and we show that geometric consistency is improved compared to the baseline models while retaining the quality of the generated images.
FlowIBR: Leveraging Pre-Training for Efficient Neural Image-Based Rendering of Dynamic Scenes
Sep 11, 2023



We introduce a novel approach for monocular novel view synthesis of dynamic scenes. Existing techniques already show impressive rendering quality but tend to focus on optimization within a single scene without leveraging prior knowledge. This limitation has been primarily attributed to the lack of datasets of dynamic scenes available for training and the diversity of scene dynamics. Our method FlowIBR circumvents these issues by integrating a neural image-based rendering method, pre-trained on a large corpus of widely available static scenes, with a per-scene optimized scene flow field. Utilizing this flow field, we bend the camera rays to counteract the scene dynamics, thereby presenting the dynamic scene as if it were static to the rendering network. The proposed method reduces per-scene optimization time by an order of magnitude, achieving comparable results to existing methods - all on a single consumer-grade GPU.
Adjustable Visual Appearance for Generalizable Novel View Synthesis
Jun 02, 2023



We present a generalizable novel view synthesis method where it is possible to modify the visual appearance of rendered views to match a target weather or lighting condition. Our method is based on a generalizable transformer architecture, trained on synthetically generated scenes under different appearance conditions. This allows for rendering novel views in a consistent manner of 3D scenes that were not included in the training set, along with the ability to (i) modify their appearance to match the target condition and (ii) smoothly interpolate between different conditions. Experiments on both real and synthetic scenes are provided including both qualitative and quantitative evaluations. Please refer to our project page for video results: https://ava-nvs.github.io/
Embodied Learning for Lifelong Visual Perception
Dec 28, 2021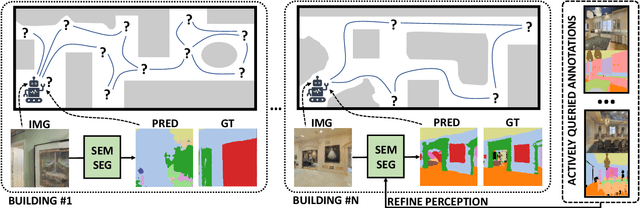
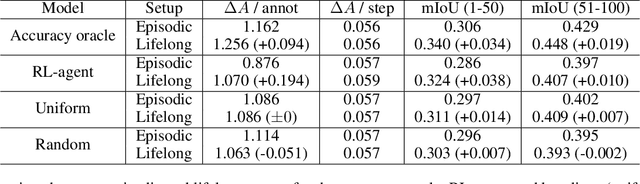

We study lifelong visual perception in an embodied setup, where we develop new models and compare various agents that navigate in buildings and occasionally request annotations which, in turn, are used to refine their visual perception capabilities. The purpose of the agents is to recognize objects and other semantic classes in the whole building at the end of a process that combines exploration and active visual learning. As we study this task in a lifelong learning context, the agents should use knowledge gained in earlier visited environments in order to guide their exploration and active learning strategy in successively visited buildings. We use the semantic segmentation performance as a proxy for general visual perception and study this novel task for several exploration and annotation methods, ranging from frontier exploration baselines which use heuristic active learning, to a fully learnable approach. For the latter, we introduce a deep reinforcement learning (RL) based agent which jointly learns both navigation and active learning. A point goal navigation formulation, coupled with a global planner which supplies goals, is integrated into the RL model in order to provide further incentives for systematic exploration of novel scenes. By performing extensive experiments on the Matterport3D dataset, we show how the proposed agents can utilize knowledge from previously explored scenes when exploring new ones, e.g. through less granular exploration and less frequent requests for annotations. The results also suggest that a learning-based agent is able to use its prior visual knowledge more effectively than heuristic alternatives.
Embodied Visual Active Learning for Semantic Segmentation
Dec 17, 2020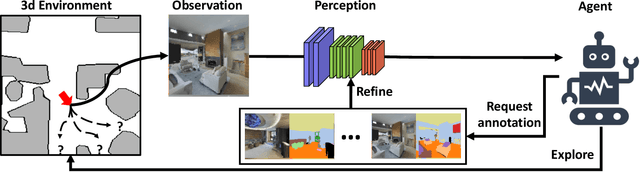
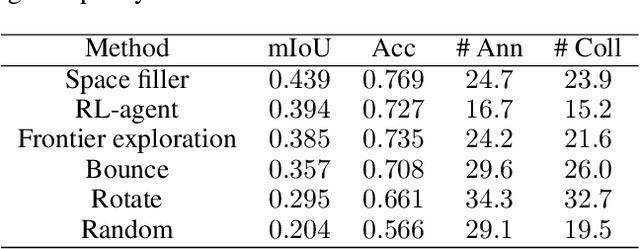
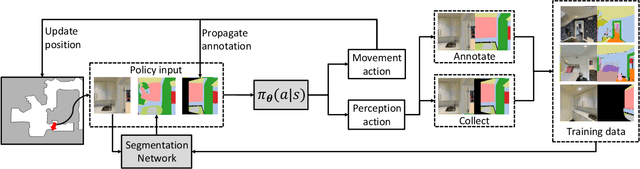
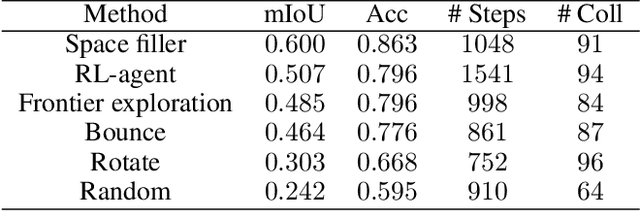
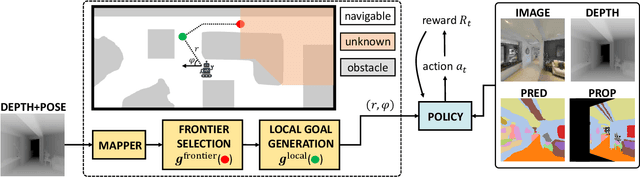
We study the task of embodied visual active learning, where an agent is set to explore a 3d environment with the goal to acquire visual scene understanding by actively selecting views for which to request annotation. While accurate on some benchmarks, today's deep visual recognition pipelines tend to not generalize well in certain real-world scenarios, or for unusual viewpoints. Robotic perception, in turn, requires the capability to refine the recognition capabilities for the conditions where the mobile system operates, including cluttered indoor environments or poor illumination. This motivates the proposed task, where an agent is placed in a novel environment with the objective of improving its visual recognition capability. To study embodied visual active learning, we develop a battery of agents - both learnt and pre-specified - and with different levels of knowledge of the environment. The agents are equipped with a semantic segmentation network and seek to acquire informative views, move and explore in order to propagate annotations in the neighbourhood of those views, then refine the underlying segmentation network by online retraining. The trainable method uses deep reinforcement learning with a reward function that balances two competing objectives: task performance, represented as visual recognition accuracy, which requires exploring the environment, and the necessary amount of annotated data requested during active exploration. We extensively evaluate the proposed models using the photorealistic Matterport3D simulator and show that a fully learnt method outperforms comparable pre-specified counterparts, even when requesting fewer annotations.
Semantic Video Segmentation by Gated Recurrent Flow Propagation
Oct 02, 2017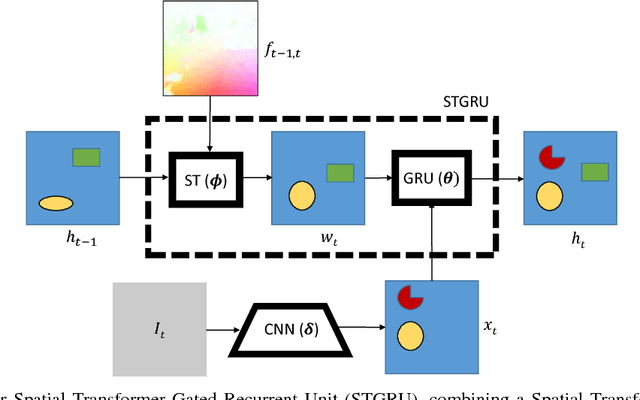
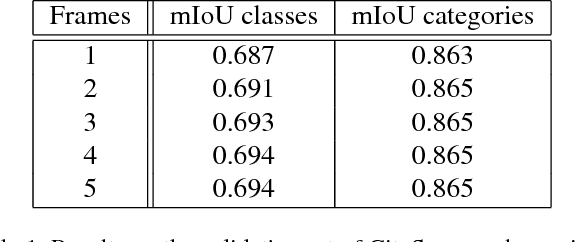
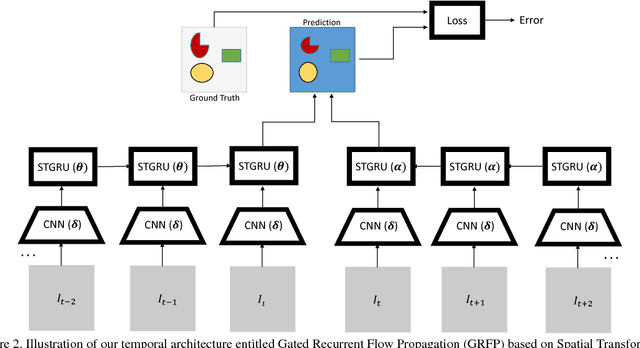
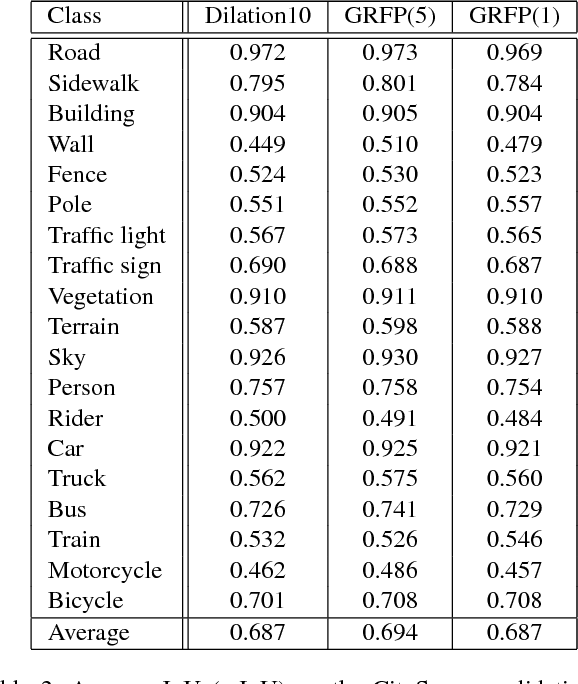
Semantic video segmentation is challenging due to the sheer amount of data that needs to be processed and labeled in order to construct accurate models. In this paper we present a deep, end-to-end trainable methodology to video segmentation that is capable of leveraging information present in unlabeled data in order to improve semantic estimates. Our model combines a convolutional architecture and a spatio-temporal transformer recurrent layer that are able to temporally propagate labeling information by means of optical flow, adaptively gated based on its locally estimated uncertainty. The flow, the recognition and the gated temporal propagation modules can be trained jointly, end-to-end. The temporal, gated recurrent flow propagation component of our model can be plugged into any static semantic segmentation architecture and turn it into a weakly supervised video processing one. Our extensive experiments in the challenging CityScapes and Camvid datasets, and based on multiple deep architectures, indicate that the resulting model can leverage unlabeled temporal frames, next to a labeled one, in order to improve both the video segmentation accuracy and the consistency of its temporal labeling, at no additional annotation cost and with little extra computation.