 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Learning for Lifelong Visual Perception
Paper and Code
Dec 28, 2021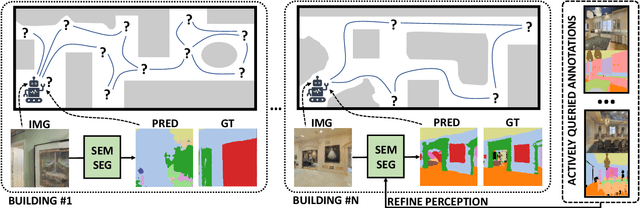
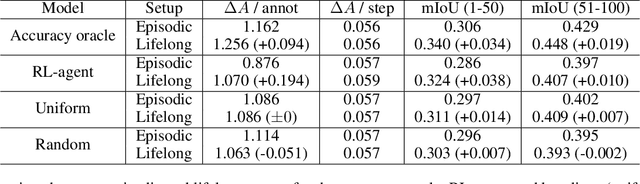
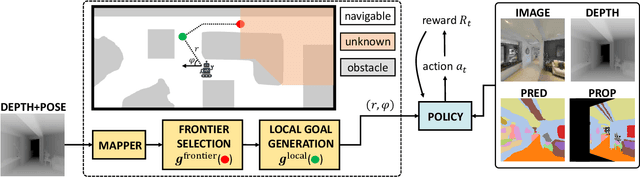

We study lifelong visual perception in an embodied setup, where we develop new models and compare various agents that navigate in buildings and occasionally request annotations which, in turn, are used to refine their visual perception capabilities. The purpose of the agents is to recognize objects and other semantic classes in the whole building at the end of a process that combines exploration and active visual learning. As we study this task in a lifelong learning context, the agents should use knowledge gained in earlier visited environments in order to guide their exploration and active learning strategy in successively visited buildings. We use the semantic segmentation performance as a proxy for general visual perception and study this novel task for several exploration and annotation methods, ranging from frontier exploration baselines which use heuristic active learning, to a fully learnable approach. For the latter, we introduce a deep reinforcement learning (RL) based agent which jointly learns both navigation and active learning. A point goal navigation formulation, coupled with a global planner which supplies goals, is integrated into the RL model in order to provide further incentives for systematic exploration of novel scenes. By performing extensive experiments on the Matterport3D dataset, we show how the proposed agents can utilize knowledge from previously explored scenes when exploring new ones, e.g. through less granular exploration and less frequent requests for annotations. The results also suggest that a learning-based agent is able to use its prior visual knowledge more effectively than heuristic alternatives.