 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Learned Optimization
Dec 02, 2022



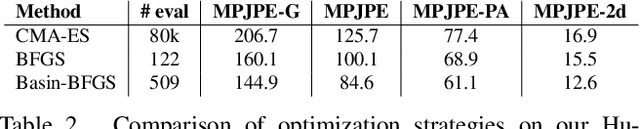
In this paper, we propose a new approach to learned optimization. As common in the literature, we represent the computation of the update step of the optimizer with a neural network. The parameters of the optimizer are then learned on a set of training optimization tasks, in order to perform minimisation efficiently. Our main innovation is to propose a new neural network architecture for the learned optimizer inspired by the classic BFGS algorithm. As in BFGS, we estimate a preconditioning matrix as a sum of rank-one updates but use a transformer-based neural network to predict these updates jointly with the step length and direction. In contrast to several recent learned optimization approaches, our formulation allows for conditioning across different dimensions of the parameter space of the target problem while remaining applicable to optimization tasks of variable dimensionality without retraining. We demonstrate the advantages of our approach on a benchmark composed of objective functions traditionally used for evaluation of optimization algorithms, as well as on the real world-task of physics-based reconstruction of articulated 3D human motion.
Trajectory Optimization for Physics-Based Reconstruction of 3d Human Pose from Monocular Video
May 24, 2022



We focus on the task of estimating a physically plausible articulated human motion from monocular video. Existing approaches that do not consider physics often produce temporally inconsistent output with motion artifacts, while state-of-the-art physics-based approaches have either been shown to work only in controlled laboratory conditions or consider simplified body-ground contact limited to feet. This paper explores how these shortcomings can be addressed by directly incorporating a fully-featured physics engine into the pose estimation process. Given an uncontrolled, real-world scene as input, our approach estimates the ground-plane location and the dimensions of the physical body model. It then recovers the physical motion by performing trajectory optimization. The advantage of our formulation is that it readily generalizes to a variety of scenes that might have diverse ground properties and supports any form of self-contact and contact between the articulated body and scene geometry. We show that our approach achieves competitive results with respect to existing physics-based methods on the Human3.6M benchmark, while being directly applicable without re-training to more complex dynamic motions from the AIST benchmark and to uncontrolled internet videos.
Differentiable Dynamics for Articulated 3d Human Motion Reconstruction
May 24, 2022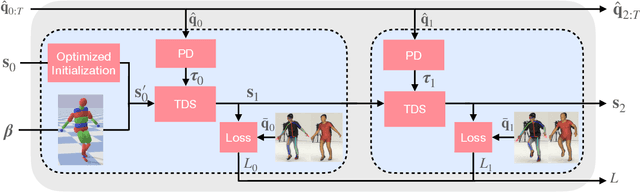
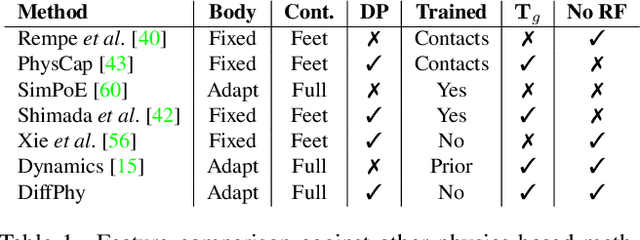

We introduce DiffPhy, a differentiable physics-based model for articulated 3d human motion reconstruction from video. Applications of physics-based reasoning in human motion analysis have so far been limited, both by the complexity of constructing adequate physical models of articulated human motion, and by the formidable challenges of performing stable and efficient inference with physics in the loop. We jointly address such modeling and inference challenges by proposing an approach that combines a physically plausible body representation with anatomical joint limits, a differentiable physics simulator, and optimization techniques that ensure good performance and robustness to suboptimal local optima. In contrast to several recent methods, our approach readily supports full-body contact including interactions with objects in the scene. Most importantly, our model connects end-to-end with images, thus supporting direct gradient-based physics optimization by means of image-based loss functions. We validate the model by demonstrating that it can accurately reconstruct physically plausible 3d human motion from monocular video, both on public benchmarks with available 3d ground-truth, and on videos from the internet.
Embodied Learning for Lifelong Visual Perception
Dec 28, 2021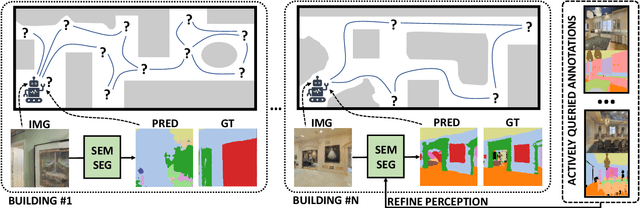
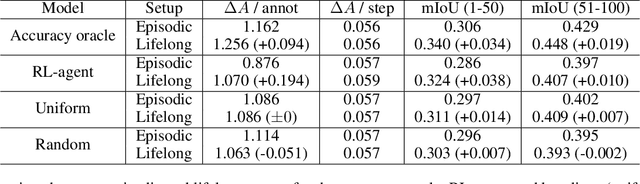

We study lifelong visual perception in an embodied setup, where we develop new models and compare various agents that navigate in buildings and occasionally request annotations which, in turn, are used to refine their visual perception capabilities. The purpose of the agents is to recognize objects and other semantic classes in the whole building at the end of a process that combines exploration and active visual learning. As we study this task in a lifelong learning context, the agents should use knowledge gained in earlier visited environments in order to guide their exploration and active learning strategy in successively visited buildings. We use the semantic segmentation performance as a proxy for general visual perception and study this novel task for several exploration and annotation methods, ranging from frontier exploration baselines which use heuristic active learning, to a fully learnable approach. For the latter, we introduce a deep reinforcement learning (RL) based agent which jointly learns both navigation and active learning. A point goal navigation formulation, coupled with a global planner which supplies goals, is integrated into the RL model in order to provide further incentives for systematic exploration of novel scenes. By performing extensive experiments on the Matterport3D dataset, we show how the proposed agents can utilize knowledge from previously explored scenes when exploring new ones, e.g. through less granular exploration and less frequent requests for annotations. The results also suggest that a learning-based agent is able to use its prior visual knowledge more effectively than heuristic alternatives.
Embodied Visual Active Learning for Semantic Segmentation
Dec 17, 2020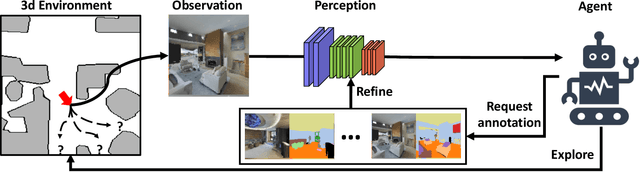
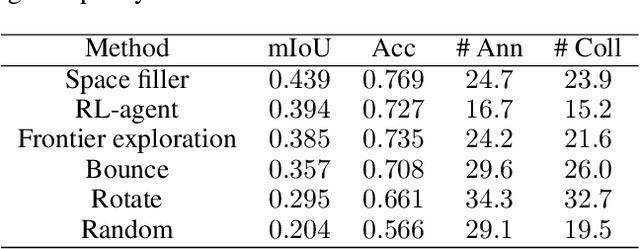
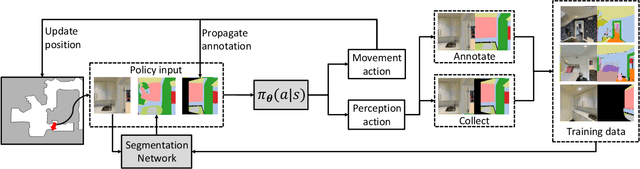
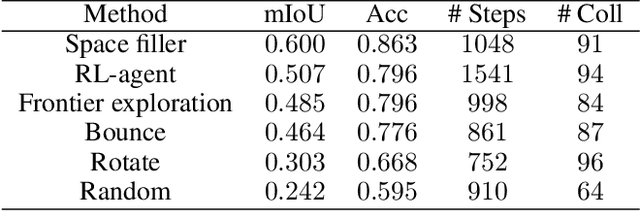
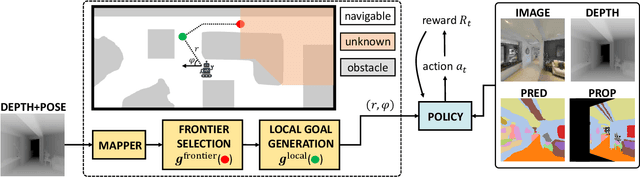
We study the task of embodied visual active learning, where an agent is set to explore a 3d environment with the goal to acquire visual scene understanding by actively selecting views for which to request annotation. While accurate on some benchmarks, today's deep visual recognition pipelines tend to not generalize well in certain real-world scenarios, or for unusual viewpoints. Robotic perception, in turn, requires the capability to refine the recognition capabilities for the conditions where the mobile system operates, including cluttered indoor environments or poor illumination. This motivates the proposed task, where an agent is placed in a novel environment with the objective of improving its visual recognition capability. To study embodied visual active learning, we develop a battery of agents - both learnt and pre-specified - and with different levels of knowledge of the environment. The agents are equipped with a semantic segmentation network and seek to acquire informative views, move and explore in order to propagate annotations in the neighbourhood of those views, then refine the underlying segmentation network by online retraining. The trainable method uses deep reinforcement learning with a reward function that balances two competing objectives: task performance, represented as visual recognition accuracy, which requires exploring the environment, and the necessary amount of annotated data requested during active exploration. We extensively evaluate the proposed models using the photorealistic Matterport3D simulator and show that a fully learnt method outperforms comparable pre-specified counterparts, even when requesting fewer annotations.
Deep Reinforcement Learning for Active Human Pose Estimation
Jan 07, 2020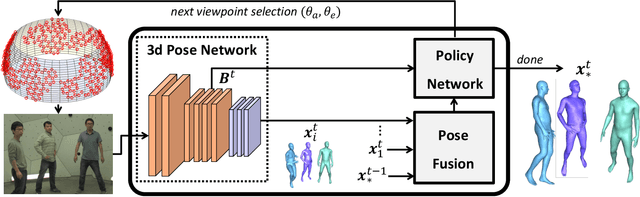

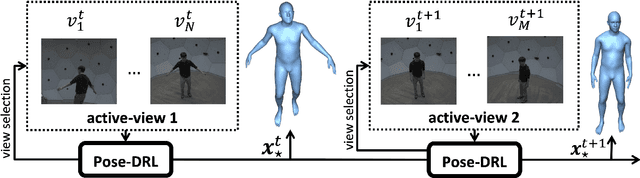

Most 3d human pose estimation methods assume that input -- be it images of a scene collected from one or several viewpoints, or from a video -- is given. Consequently, they focus on estimates leveraging prior knowledge and measurement by fusing information spatially and/or temporally, whenever available. In this paper we address the problem of an active observer with freedom to move and explore the scene spatially -- in `time-freeze' mode -- and/or temporally, by selecting informative viewpoints that improve its estimation accuracy. Towards this end, we introduce Pose-DRL, a fully trainable deep reinforcement learning-based active pose estimation architecture which learns to select appropriate views, in space and time, to feed an underlying monocular pose estimator. We evaluate our model using single- and multi-target estimators with strong result in both settings. Our system further learns automatic stopping conditions in time and transition functions to the next temporal processing step in videos. In extensive experiments with the Panoptic multi-view setup, and for complex scenes containing multiple people, we show that our model learns to select viewpoints that yield significantly more accurate pose estimates compared to strong multi-view baselines.