 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHFM: A Unified Video Foundation Model for 4D Human Perception and Beyond
Mar 26, 2026We present THFM, a unified video foundation model for human-centric perception that jointly addresses dense tasks (depth, normals, segmentation, dense pose) and sparse tasks (2d/3d keypoint estimation) within a single architecture. THFM is derived from a pretrained text-to-video diffusion model, repurposed as a single-forward-pass perception model and augmented with learnable tokens for sparse predictions. Modulated by the text prompt, our single unified model is capable of performing various perception tasks. Crucially, our model is on-par or surpassing state-of-the-art specialized models on a variety of benchmarks despite being trained exclusively on synthetic data (i.e.~without training on real-world or benchmark specific data). We further highlight intriguing emergent properties of our model, which we attribute to the underlying diffusion-based video representation. For example, our model trained on videos with a single human in the scene generalizes to multiple humans and other object classes such as anthropomorphic characters and animals -- a capability that hasn't been demonstrated in the past.
Applications of fractional calculus in learned optimization
Nov 22, 2024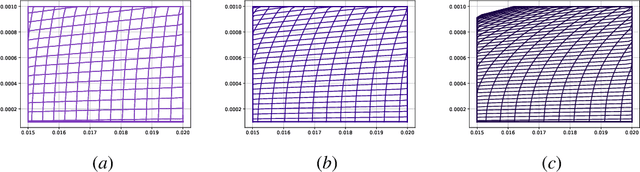
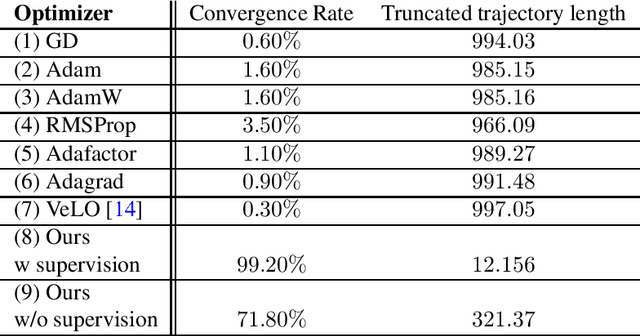
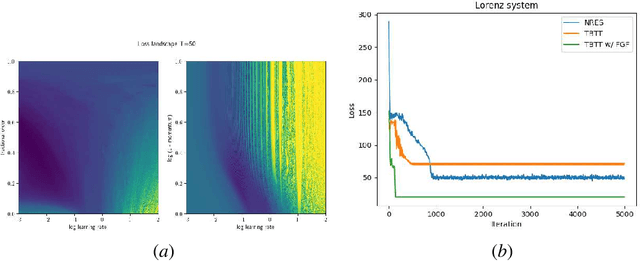
Fractional gradient descent has been studied extensively, with a focus on its ability to extend traditional gradient descent methods by incorporating fractional-order derivatives. This approach allows for more flexibility in navigating complex optimization landscapes and offers advantages in certain types of problems, particularly those involving non-linearities and chaotic dynamics. Yet, the challenge of fine-tuning the fractional order parameters remains unsolved. In this work, we demonstrate that it is possible to train a neural network to predict the order of the gradient effectively.
Learned Neural Physics Simulation for Articulated 3D Human Pose Reconstruction
Oct 15, 2024We propose a novel neural network approach, LARP (Learned Articulated Rigid body Physics), to model the dynamics of articulated human motion with contact. Our goal is to develop a faster and more convenient methodological alternative to traditional physics simulators for use in computer vision tasks such as human motion reconstruction from video. To that end we introduce a training procedure and model components that support the construction of a recurrent neural architecture to accurately simulate articulated rigid body dynamics. Our neural architecture supports features typically found in traditional physics simulators, such as modeling of joint motors, variable dimensions of body parts, contact between body parts and objects, and is an order of magnitude faster than traditional systems when multiple simulations are run in parallel. To demonstrate the value of LARP we use it as a drop-in replacement for a state of the art classical non-differentiable simulator in an existing video-based reconstruction framework and show comparative or better 3D human pose reconstruction accuracy.
Instant 3D Human Avatar Generation using Image Diffusion Models
Jun 11, 2024
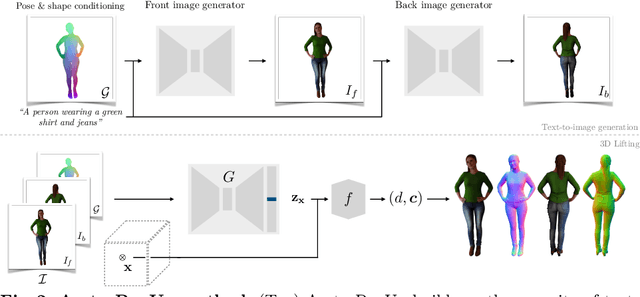
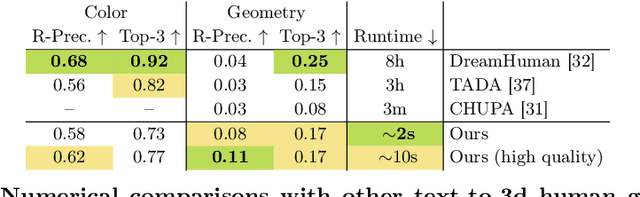
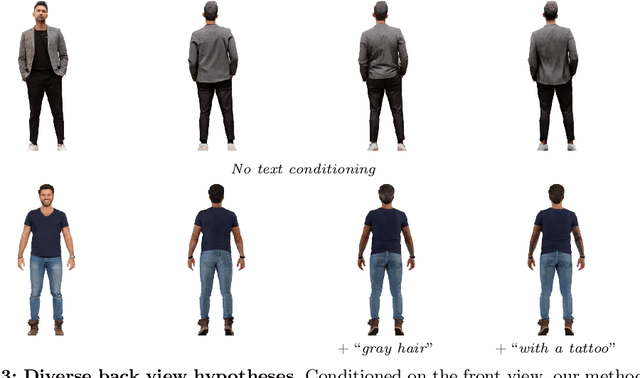
We present AvatarPopUp, a method for fast, high quality 3D human avatar generation from different input modalities, such as images and text prompts and with control over the generated pose and shape. The common theme is the use of diffusion-based image generation networks that are specialized for each particular task, followed by a 3D lifting network. We purposefully decouple the generation from the 3D modeling which allow us to leverage powerful image synthesis priors, trained on billions of text-image pairs. We fine-tune latent diffusion networks with additional image conditioning to solve tasks such as image generation and back-view prediction, and to support qualitatively different multiple 3D hypotheses. Our partial fine-tuning approach allows to adapt the networks for each task without inducing catastrophic forgetting. In our experiments, we demonstrate that our method produces accurate, high-quality 3D avatars with diverse appearance that respect the multimodal text, image, and body control signals. Our approach can produce a 3D model in as few as 2 seconds, a four orders of magnitude speedup w.r.t. the vast majority of existing methods, most of which solve only a subset of our tasks, and with fewer controls, thus enabling applications that require the controlled 3D generation of human avatars at scale. The project website can be found at https://www.nikoskolot.com/avatarpopup/.
DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
Mar 30, 2024

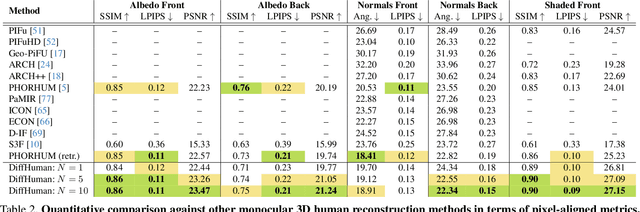

We present DiffHuman, a probabilistic method for photorealistic 3D human reconstruction from a single RGB image. Despite the ill-posed nature of this problem, most methods are deterministic and output a single solution, often resulting in a lack of geometric detail and blurriness in unseen or uncertain regions. In contrast, DiffHuman predicts a probability distribution over 3D reconstructions conditioned on an input 2D image, which allows us to sample multiple detailed 3D avatars that are consistent with the image. DiffHuman is implemented as a conditional diffusion model that denoises pixel-aligned 2D observations of an underlying 3D shape representation. During inference, we may sample 3D avatars by iteratively denoising 2D renders of the predicted 3D representation. Furthermore, we introduce a generator neural network that approximates rendering with considerably reduced runtime (55x speed up), resulting in a novel dual-branch diffusion framework. Our experiments show that DiffHuman can produce diverse and detailed reconstructions for the parts of the person that are unseen or uncertain in the input image, while remaining competitive with the state-of-the-art when reconstructing visible surfaces.
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
Mar 13, 2024We propose VLOGGER, a method for audio-driven human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2) a novel diffusion-based architecture that augments text-to-image models with both spatial and temporal controls. This supports the generation of high quality video of variable length, easily controllable through high-level representations of human faces and bodies. In contrast to previous work, our method does not require training for each person, does not rely on face detection and cropping, generates the complete image (not just the face or the lips), and considers a broad spectrum of scenarios (e.g. visible torso or diverse subject identities) that are critical to correctly synthesize humans who communicate. We also curate MENTOR, a new and diverse dataset with 3d pose and expression annotations, one order of magnitude larger than previous ones (800,000 identities) and with dynamic gestures, on which we train and ablate our main technical contributions. VLOGGER outperforms state-of-the-art methods in three public benchmarks, considering image quality, identity preservation and temporal consistency while also generating upper-body gestures. We analyze the performance of VLOGGER with respect to multiple diversity metrics, showing that our architectural choices and the use of MENTOR benefit training a fair and unbiased model at scale. Finally we show applications in video editing and personalization.
Score Distillation Sampling with Learned Manifold Corrective
Jan 10, 2024



Score Distillation Sampling (SDS) is a recent but already widely popular method that relies on an image diffusion model to control optimization problems using text prompts. In this paper, we conduct an in-depth analysis of the SDS loss function, identify an inherent problem with its formulation, and propose a surprisingly easy but effective fix. Specifically, we decompose the loss into different factors and isolate the component responsible for noisy gradients. In the original formulation, high text guidance is used to account for the noise, leading to unwanted side effects. Instead, we train a shallow network mimicking the timestep-dependent denoising deficiency of the image diffusion model in order to effectively factor it out. We demonstrate the versatility and the effectiveness of our novel loss formulation through several qualitative and quantitative experiments, including optimization-based image synthesis and editing, zero-shot image translation network training, and text-to-3D synthesis.
Personalized Pose Forecasting
Dec 06, 2023Human pose forecasting is the task of predicting articulated human motion given past human motion. There exists a number of popular benchmarks that evaluate an array of different models performing human pose forecasting. These benchmarks do not reflect that a human interacting system, such as a delivery robot, observes and plans for the motion of the same individual over an extended period of time. Every individual has unique and distinct movement patterns. This is however not reflected in existing benchmarks that evaluate a model's ability to predict an average human's motion rather than a particular individual's. We reformulate the human motion forecasting problem and present a model-agnostic personalization method. Motion forecasting personalization can be performed efficiently online by utilizing a low-parametric time-series analysis model that personalizes neural network pose predictions.
SPHEAR: Spherical Head Registration for Complete Statistical 3D Modeling
Nov 04, 2023



We present \emph{SPHEAR}, an accurate, differentiable parametric statistical 3D human head model, enabled by a novel 3D registration method based on spherical embeddings. We shift the paradigm away from the classical Non-Rigid Registration methods, which operate under various surface priors, increasing reconstruction fidelity and minimizing required human intervention. Additionally, SPHEAR is a \emph{complete} model that allows not only to sample diverse synthetic head shapes and facial expressions, but also gaze directions, high-resolution color textures, surface normal maps, and hair cuts represented in detail, as strands. SPHEAR can be used for automatic realistic visual data generation, semantic annotation, and general reconstruction tasks. Compared to state-of-the-art approaches, our components are fast and memory efficient, and experiments support the validity of our design choices and the accuracy of registration, reconstruction and generation techniques.
Blendshapes GHUM: Real-time Monocular Facial Blendshape Prediction
Sep 11, 2023We present Blendshapes GHUM, an on-device ML pipeline that predicts 52 facial blendshape coefficients at 30+ FPS on modern mobile phones, from a single monocular RGB image and enables facial motion capture applications like virtual avatars. Our main contributions are: i) an annotation-free offline method for obtaining blendshape coefficients from real-world human scans, ii) a lightweight real-time model that predicts blendshape coefficients based on facial landmarks.