 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Three-Dimensional Models of Interacting Humans
Aug 04, 2023Understanding 3d human interactions is fundamental for fine-grained scene analysis and behavioural modeling. However, most of the existing models predict incorrect, lifeless 3d estimates, that miss the subtle human contact aspects--the essence of the event--and are of little use for detailed behavioral understanding. This paper addresses such issues with several contributions: (1) we introduce models for interaction signature estimation (ISP) encompassing contact detection, segmentation, and 3d contact signature prediction; (2) we show how such components can be leveraged to ensure contact consistency during 3d reconstruction; (3) we construct several large datasets for learning and evaluating 3d contact prediction and reconstruction methods; specifically, we introduce CHI3D, a lab-based accurate 3d motion capture dataset with 631 sequences containing $2,525$ contact events, $728,664$ ground truth 3d poses, as well as FlickrCI3D, a dataset of $11,216$ images, with $14,081$ processed pairs of people, and $81,233$ facet-level surface correspondences. Finally, (4) we propose methodology for recovering the ground-truth pose and shape of interacting people in a controlled setup and (5) annotate all 3d interaction motions in CHI3D with textual descriptions. Motion data in multiple formats (GHUM and SMPLX parameters, Human3.6m 3d joints) is made available for research purposes at \url{https://ci3d.imar.ro}, together with an evaluation server and a public benchmark.
Learning Complex 3D Human Self-Contact
Dec 18, 2020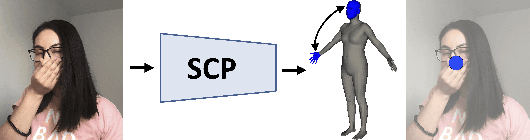

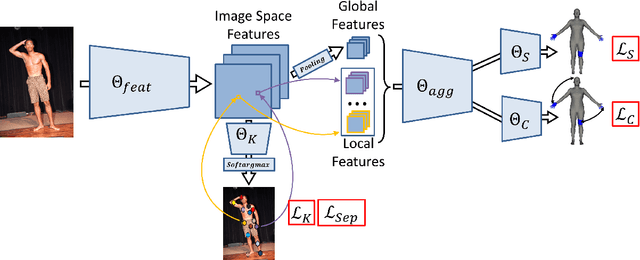

Monocular estimation of three dimensional human self-contact is fundamental for detailed scene analysis including body language understanding and behaviour modeling. Existing 3d reconstruction methods do not focus on body regions in self-contact and consequently recover configurations that are either far from each other or self-intersecting, when they should just touch. This leads to perceptually incorrect estimates and limits impact in those very fine-grained analysis domains where detailed 3d models are expected to play an important role. To address such challenges we detect self-contact and design 3d losses to explicitly enforce it. Specifically, we develop a model for Self-Contact Prediction (SCP), that estimates the body surface signature of self-contact, leveraging the localization of self-contact in the image, during both training and inference. We collect two large datasets to support learning and evaluation: (1) HumanSC3D, an accurate 3d motion capture repository containing $1,032$ sequences with $5,058$ contact events and $1,246,487$ ground truth 3d poses synchronized with images collected from multiple views, and (2) FlickrSC3D, a repository of $3,969$ images, containing $25,297$ surface-to-surface correspondences with annotated image spatial support. We also illustrate how more expressive 3d reconstructions can be recovered under self-contact signature constraints and present monocular detection of face-touch as one of the multiple applications made possible by more accurate self-contact models.
A Parallel Framework for Parametric Maximum Flow Problems in Image Segmentation
Dec 07, 2015
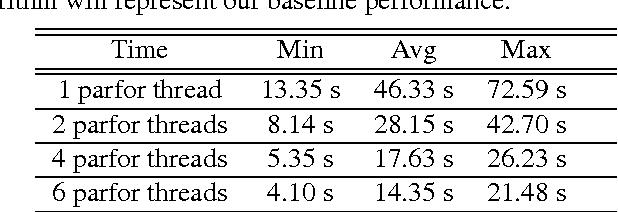

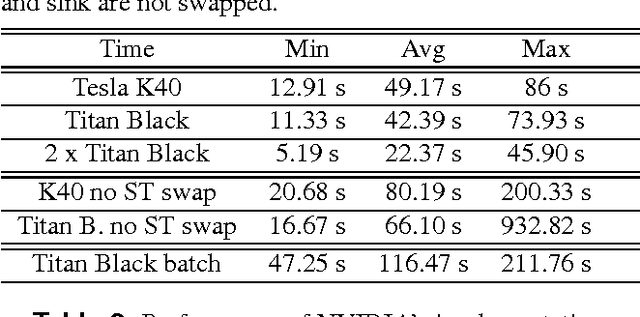
This paper presents a framework that supports the implementation of parallel solutions for the widespread parametric maximum flow computational routines used in image segmentation algorithms. The framework is based on supergraphs, a special construction combining several image graphs into a larger one, and works on various architectures (multi-core or GPU), either locally or remotely in a cluster of computing nodes. The framework can also be used for performance evaluation of parallel implementations of maximum flow algorithms. We present the case study of a state-of-the-art image segmentation algorithm based on graph cuts, Constrained Parametric Min-Cut (CPMC), that uses the parallel framework to solve parametric maximum flow problems, based on a GPU implementation of the well-known push-relabel algorithm. Our results indicate that real-time implementations based on the proposed techniques are possible.