 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Long-Range Parser for Sequential Data Understanding
Apr 08, 2024The transformer is a powerful data modelling framework responsible for remarkable performance on a wide range of tasks. However, they are limited in terms of scalability as it is suboptimal and inefficient to process long-sequence data. To this purpose we introduce BLRP (Bidirectional Long-Range Parser), a novel and versatile attention mechanism designed to increase performance and efficiency on long-sequence tasks. It leverages short and long range heuristics in the form of a local sliding window approach combined with a global bidirectional latent space synthesis technique. We show the benefits and versatility of our approach on vision and language domains by demonstrating competitive results against state-of-the-art methods on the Long-Range-Arena and CIFAR benchmarks together with ablations demonstrating the computational efficiency.
Watermark Text Pattern Spotting in Document Images
Jan 11, 2024Watermark text spotting in document images can offer access to an often unexplored source of information, providing crucial evidence about a record's scope, audience and sometimes even authenticity. Stemming from the problem of text spotting, detecting and understanding watermarks in documents inherits the same hardships - in the wild, writing can come in various fonts, sizes and forms, making generic recognition a very difficult problem. To address the lack of resources in this field and propel further research, we propose a novel benchmark (K-Watermark) containing 65,447 data samples generated using Wrender, a watermark text patterns rendering procedure. A validity study using humans raters yields an authenticity score of 0.51 against pre-generated watermarked documents. To prove the usefulness of the dataset and rendering technique, we developed an end-to-end solution (Wextract) for detecting the bounding box instances of watermark text, while predicting the depicted text. To deal with this specific task, we introduce a variance minimization loss and a hierarchical self-attention mechanism. To the best of our knowledge, we are the first to propose an evaluation benchmark and a complete solution for retrieving watermarks from documents surpassing baselines by 5 AP points in detection and 4 points in character accuracy.
Reconstructing Three-Dimensional Models of Interacting Humans
Aug 04, 2023



Understanding 3d human interactions is fundamental for fine-grained scene analysis and behavioural modeling. However, most of the existing models predict incorrect, lifeless 3d estimates, that miss the subtle human contact aspects--the essence of the event--and are of little use for detailed behavioral understanding. This paper addresses such issues with several contributions: (1) we introduce models for interaction signature estimation (ISP) encompassing contact detection, segmentation, and 3d contact signature prediction; (2) we show how such components can be leveraged to ensure contact consistency during 3d reconstruction; (3) we construct several large datasets for learning and evaluating 3d contact prediction and reconstruction methods; specifically, we introduce CHI3D, a lab-based accurate 3d motion capture dataset with 631 sequences containing $2,525$ contact events, $728,664$ ground truth 3d poses, as well as FlickrCI3D, a dataset of $11,216$ images, with $14,081$ processed pairs of people, and $81,233$ facet-level surface correspondences. Finally, (4) we propose methodology for recovering the ground-truth pose and shape of interacting people in a controlled setup and (5) annotate all 3d interaction motions in CHI3D with textual descriptions. Motion data in multiple formats (GHUM and SMPLX parameters, Human3.6m 3d joints) is made available for research purposes at \url{https://ci3d.imar.ro}, together with an evaluation server and a public benchmark.
CONSENT: Context Sensitive Transformer for Bold Words Classification
May 16, 2022

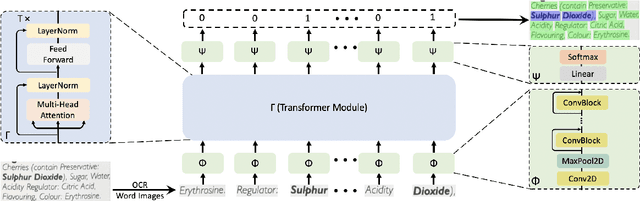

We present CONSENT, a simple yet effective CONtext SENsitive Transformer framework for context-dependent object classification within a fully-trainable end-to-end deep learning pipeline. We exemplify the proposed framework on the task of bold words detection proving state-of-the-art results. Given an image containing text of unknown font-types (e.g. Arial, Calibri, Helvetica), unknown language, taken under various degrees of illumination, angle distortion and scale variation, we extract all the words and learn a context-dependent binary classification (i.e. bold versus non-bold) using an end-to-end transformer-based neural network ensemble. To prove the extensibility of our framework, we demonstrate competitive results against state-of-the-art for the game of rock-paper-scissors by training the model to determine the winner given a sequence with $2$ pictures depicting hand poses.
Learning Complex 3D Human Self-Contact
Dec 18, 2020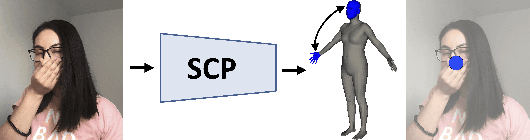

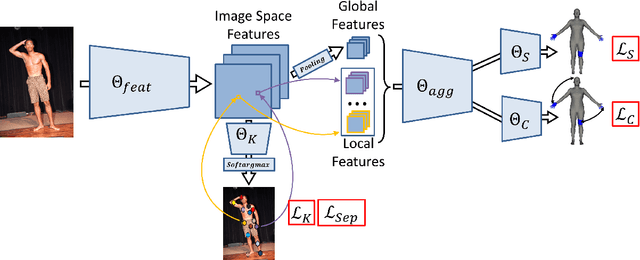

Monocular estimation of three dimensional human self-contact is fundamental for detailed scene analysis including body language understanding and behaviour modeling. Existing 3d reconstruction methods do not focus on body regions in self-contact and consequently recover configurations that are either far from each other or self-intersecting, when they should just touch. This leads to perceptually incorrect estimates and limits impact in those very fine-grained analysis domains where detailed 3d models are expected to play an important role. To address such challenges we detect self-contact and design 3d losses to explicitly enforce it. Specifically, we develop a model for Self-Contact Prediction (SCP), that estimates the body surface signature of self-contact, leveraging the localization of self-contact in the image, during both training and inference. We collect two large datasets to support learning and evaluation: (1) HumanSC3D, an accurate 3d motion capture repository containing $1,032$ sequences with $5,058$ contact events and $1,246,487$ ground truth 3d poses synchronized with images collected from multiple views, and (2) FlickrSC3D, a repository of $3,969$ images, containing $25,297$ surface-to-surface correspondences with annotated image spatial support. We also illustrate how more expressive 3d reconstructions can be recovered under self-contact signature constraints and present monocular detection of face-touch as one of the multiple applications made possible by more accurate self-contact models.
Human Synthesis and Scene Compositing
Oct 18, 2019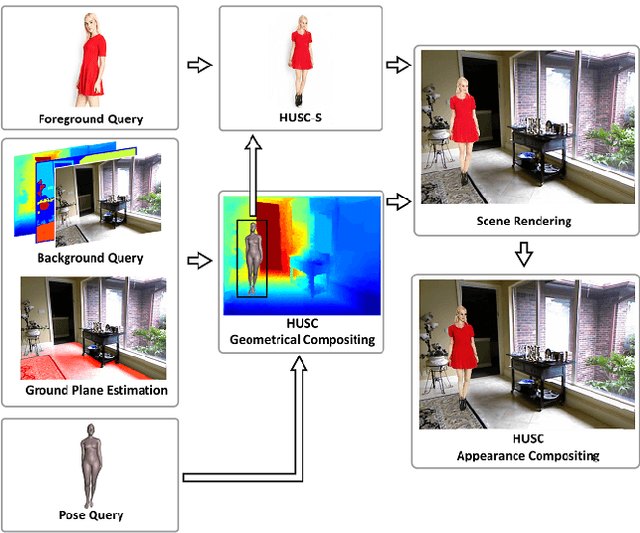
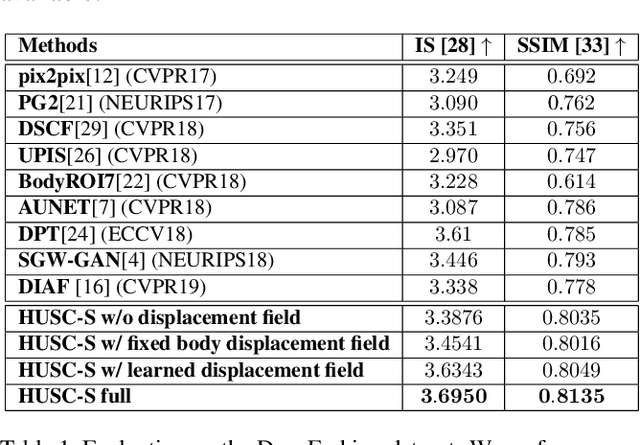
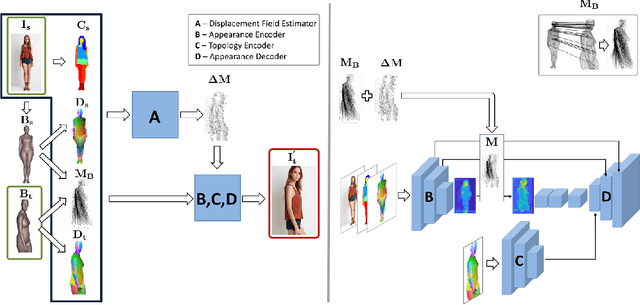
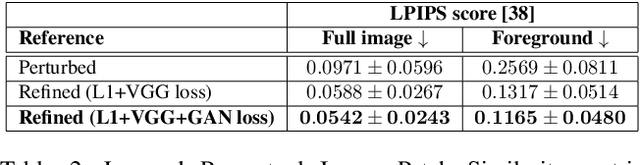
Generating good quality and geometrically plausible synthetic images of humans with the ability to control appearance, pose and shape parameters, has become increasingly important for a variety of tasks ranging from photo editing, fashion virtual try-on, to special effects and image compression. In this paper, we propose HUSC, a HUman Synthesis and Scene Compositing framework for the realistic synthesis of humans with different appearance, in novel poses and scenes. Central to our formulation is 3d reasoning for both people and scenes, in order to produce realistic collages, by correctly modeling perspective effects and occlusion, by taking into account scene semantics and by adequately handling relative scales. Conceptually our framework consists of three components: (1) a human image synthesis model with controllable pose and appearance, based on a parametric representation, (2) a person insertion procedure that leverages the geometry and semantics of the 3d scene, and (3) an appearance compositing process to create a seamless blending between the colors of the scene and the generated human image, and avoid visual artifacts. The performance of our framework is supported by both qualitative and quantitative results, in particular state-of-the art synthesis scores for the DeepFashion dataset.
Deep Multitask Architecture for Integrated 2D and 3D Human Sensing
Jan 31, 2017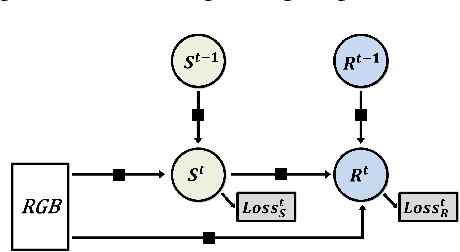

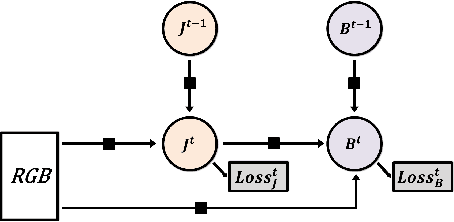

We propose a deep multitask architecture for \emph{fully automatic 2d and 3d human sensing} (DMHS), including \emph{recognition and reconstruction}, in \emph{monocular images}. The system computes the figure-ground segmentation, semantically identifies the human body parts at pixel level, and estimates the 2d and 3d pose of the person. The model supports the joint training of all components by means of multi-task losses where early processing stages recursively feed into advanced ones for increasingly complex calculations, accuracy and robustness. The design allows us to tie a complete training protocol, by taking advantage of multiple datasets that would otherwise restrictively cover only some of the model components: complex 2d image data with no body part labeling and without associated 3d ground truth, or complex 3d data with limited 2d background variability. In detailed experiments based on several challenging 2d and 3d datasets (LSP, HumanEva, Human3.6M), we evaluate the sub-structures of the model, the effect of various types of training data in the multitask loss, and demonstrate that state-of-the-art results can be achieved at all processing levels. We also show that in the wild our monocular RGB architecture is perceptually competitive to a state-of-the art (commercial) Kinect system based on RGB-D data.
Parametric Image Segmentation of Humans with Structural Shape Priors
Jan 27, 2015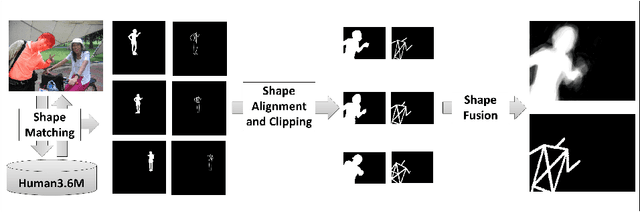
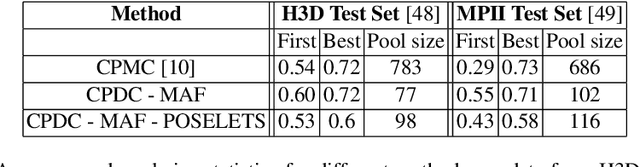
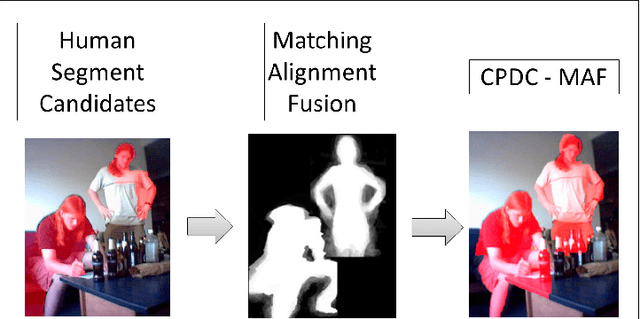

The figure-ground segmentation of humans in images captured in natural environments is an outstanding open problem due to the presence of complex backgrounds, articulation, varying body proportions, partial views and viewpoint changes. In this work we propose class-specific segmentation models that leverage parametric max-flow image segmentation and a large dataset of human shapes. Our contributions are as follows: (1) formulation of a sub-modular energy model that combines class-specific structural constraints and data-driven shape priors, within a parametric max-flow optimization methodology that systematically computes all breakpoints of the model in polynomial time; (2) design of a data-driven class-specific fusion methodology, based on matching against a large training set of exemplar human shapes (100,000 in our experiments), that allows the shape prior to be constructed on-the-fly, for arbitrary viewpoints and partial views. (3) demonstration of state of the art results, in two challenging datasets, H3D and MPII (where figure-ground segmentation annotations have been added by us), where we substantially improve on the first ranked hypothesis estimates of mid-level segmentation methods, by 20%, with hypothesis set sizes that are up to one order of magnitude smaller.